NGINX e HAProxy: Testing User Experience in the Cloud – NGINX
Muitos benchmarks de desempenho medem o pico de produção ou solicitações por segundo (RPS), mas essas métricas podem simplificar demais a história do desempenho em sites do mundo real. Poucas organizações executam seus serviços em ou perto do pico de produção, onde uma mudança de 10% no desempenho de qualquer forma pode fazer uma diferença significativa. O throughput ou RPS que um site requer não é infinito, mas é fixado por fatores externos como o número de usuários simultâneos que eles têm que servir e o nível de atividade de cada usuário. No final, o que mais importa é que seus usuários recebam o melhor nível de serviço. Os usuários finais não se importam quantas outras pessoas estão visitando o seu site. Eles apenas se importam com o serviço que recebem e não desculpam o mau desempenho porque o sistema está sobrecarregado.
Isso nos leva à observação de que o que mais importa é que uma organização forneça um desempenho consistente e de baixa latência a todos os seus usuários, mesmo sob carga alta. Ao comparar o NGINX e o HAProxy rodando na Amazon Elastic Compute Cloud (EC2) como proxies reversíveis, nós nos propusemos a fazer duas coisas:
- Determinar que nível de carga cada proxy manipula confortavelmente
- Colher a distribuição do percentil de latência, que achamos ser a métrica mais diretamente correlacionada com a experiência do usuário
Protocolos de teste e métricas coletadas
Usamos o programa de geração de carga wrk2 para emular um cliente, fazendo solicitações contínuas sobre HTTPS durante um período definido. O sistema em teste – HAProxy ou NGINX – atuou como proxy reverso, estabelecendo conexões criptografadas com os clientes simulados por wrk threads, encaminhando solicitações para um servidor web backend rodando NGINX Plus R22, e retornando a resposta gerada pelo servidor web (um arquivo) para o cliente.
Cada um dos três componentes (cliente, proxy reverso e servidor web) rodou Ubuntu 20.04.1 LTS em um c5n.2xlarge Amazon Machine Image (AMI) no EC2.
Como mencionado, nós coletamos a distribuição completa do percentil de latência de cada execução de teste. A latência é definida como a quantidade de tempo entre o cliente que gera a solicitação e o recebimento da resposta. Uma distribuição do percentil de latência ordena as medidas de latência coletadas durante o período de teste da maior (maior latência) para a menor.
Testing Methodology
Client
Using wrk2 (versão 4.0.0), nós rodamos o seguinte script na instância EC2 da Amazon:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Para simular muitos clientes acessando uma aplicação web, 4 wrk foram gerados threads que juntos estabeleceram 100 conexões para o proxy reverso. Durante a execução de teste de 30 segundos, o script gerou um número especificado de RPS. Estes parâmetros correspondem aos seguintes parâmetros wrk2 opções:
-
‑topção – Número de threads a criar (4) -
‑copção – Número de conexões TCP a criar (100) -
‑dopção – Número de segundos no período de teste (30 segundos) -
‑Ropção – Número de RPS emitidas pelo cliente -
‑‑latencyopção – Saída inclui informação corrigida do percentil de latência
Aumentamos incrementalmente o número de RPS sobre o conjunto de execuções de teste até que um dos proxies atinja 100% de utilização da CPU. Para mais discussão, veja Resultados de Desempenho.
Todas as conexões entre cliente e proxy foram feitas sobre HTTPS com TLSv1.3. Usamos ECC com um tamanho de chave de 256 bits, Perfect Forward Secrecy, e o conjunto TLS_AES_256_GCM_SHA384 cipher (Como o TLSv1.2 ainda é comumente usado na Internet, nós também re-analizamos os testes com ele; os resultados foram tão similares aos do TLSv1.3 que não os incluímos aqui.)
HAProxy: Configuração e Versionamento
Provisionamos o HAProxy versão 2.3 (estável) como o proxy reverso.
O número de usuários simultâneos em um site popular pode ser enorme. Para lidar com o grande volume de tráfego, seu proxy reverso precisa ser capaz de escalar para tirar vantagem de vários núcleos. Existem duas formas básicas de escalar: multi-processamento e multi-tarefas. Tanto o NGINX como o HAProxy suportam multi-processamento, mas há uma diferença importante – na implementação do HAProxy, os processos não partilham memória (enquanto que no NGINX partilham). A incapacidade de compartilhar estado entre processos tem várias consequências para o HAProxy:
- Parâmetros de configuração – incluindo limites, estatísticas e taxas – devem ser definidos separadamente para cada processo.
- Métricas de desempenho são coletadas por processo; combiná-las requer configuração adicional, que pode ser bastante complexa.
- Cada processo lida com verificações de saúde separadamente, assim os servidores alvo são sondados por processo e não por servidor como esperado.
- A persistência da sessão não é possível.
- Uma mudança de configuração dinâmica feita através da API HAProxy Runtime aplica-se a um único processo, assim você deve repetir a chamada da API para cada processo.
Por causa destes problemas, o HAProxy desencoraja fortemente o uso de sua implementação de multi-processamento. Para citar directamente do manual de configuração do HAProxy:
USING MULTIPIPLE PROCESSES IS HARDER TO DEBUG AND IS REALY DISCOURAGED.
HAProxy introduced multi-threading in version 1.8 as an alternative to multi-processing. O multi-tarefa resolve o problema de partilha de estado, mas como discutimos em Resultados de Performance, no modo multi-tarefa o HAProxy não funciona tão bem como no modo multi-processo.
A nossa configuração HAProxy incluiu o provisionamento tanto para o modo multithread (HAProxy MT) como para o modo multi-processamento (HAProxy MP). Para alternar entre modos em cada nível RPS durante o teste, comentamos e descomentamos o conjunto apropriado de linhas e reiniciamos o HAProxy para que a configuração tivesse efeito:
$ sudo service haproxy restartAqui está a configuração com o provisionamento do HAProxy MT: quatro threads são criadas sob um único processo e cada thread é afixada a uma CPU. Para o HAProxy MP (comentado aqui), existem quatro processos cada um afixados a uma CPU.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Configuração e Versionamento
Desenvolvemos o NGINX Open Source versão 1.18.0 como proxy reverso.
Para usar todos os núcleos disponíveis na máquina (quatro neste caso), incluímos o parâmetro auto à diretiva worker_processes, que também é a configuração no arquivo nginx.conf padrão distribuído a partir do nosso repositório. Além disso, a diretiva worker_cpu_affinity foi incluída para fixar cada processo de trabalhador em uma CPU (cada 1 no segundo parâmetro denota uma CPU na máquina).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Resultados de desempenho
Como o front end da sua aplicação, o desempenho do seu proxy reverso é crítico.
Testamos cada proxy reverso (NGINX, HAProxy MP e HAProxy MT) em números crescentes de RPS até que um deles atingisse 100% de utilização da CPU. Todos os três tiveram desempenho semelhante nos níveis de RPS onde a CPU não foi esgotada.
Atingir 100% de utilização da CPU ocorreu primeiro para HAProxy MT, a 85.000 RPS, e nesse ponto o desempenho piorou drasticamente tanto para HAProxy MT como para HAProxy MP. Aqui apresentamos a distribuição percentual de latência de cada proxy reverso a esse nível de carga. O gráfico foi plotado a partir da saída do script wrk usando o programa HdrHistogram disponível no GitHub.
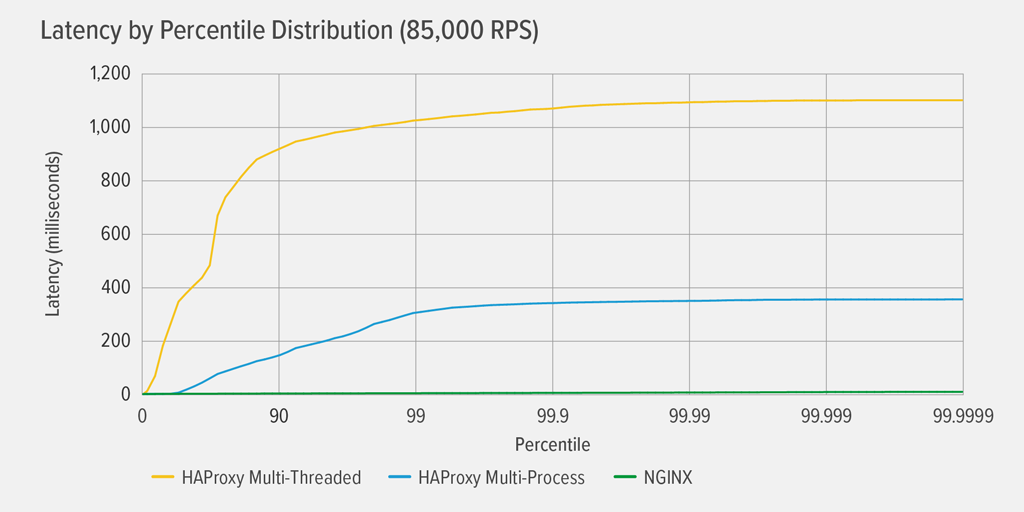
Em 85.000 RPS, a latência com HAProxy MT sobe abruptamente até o percentil 90, e então gradualmente se desnivela em aproximadamente 1100 milissegundos (ms).
HAProxy MP tem um desempenho melhor que HAProxy MT – a latência sobe a um ritmo mais lento até ao percentil 99, altura em que começa a nivelar a cerca de 400ms. (Como confirmação de que HAProxy MP é mais eficiente, observámos que HAProxy MT usava um pouco mais de CPU que HAProxy MP em cada nível de RPS.)
NGINX praticamente não sofre de latência em nenhum percentil. A maior latência que qualquer número significativo de usuários pode experimentar (no percentil 99,9999) é de aproximadamente 8ms.
O que estes resultados nos dizem sobre a experiência do usuário? Como mencionado na introdução, a métrica que realmente importa é o tempo de resposta da perspectiva do usuário final, e não o tempo de serviço do sistema em teste.
É um equívoco comum que a latência mediana em uma distribuição representa melhor a experiência do usuário. Na verdade, a mediana é o número que cerca de metade do tempo de resposta é pior do que! Os usuários normalmente emitem muitos pedidos e acessam muitos recursos por carga de página, então vários de seus pedidos são obrigados a experimentar latências nos percentis superiores do gráfico (99º a 99,9999º). Como os utilizadores são tão intolerantes ao mau desempenho, as latências nos percentis altos são as que mais provavelmente notarão.
Pense desta forma: a sua experiência de check-out numa mercearia é determinada pelo tempo que demora a sair da loja a partir do momento em que entrou na linha de checkout, e não apenas pelo tempo que demorou a caixa a ligar para os seus artigos. Se, por exemplo, um cliente na sua frente disputar o preço de um artigo e o caixa tiver de arranjar alguém para o verificar, o seu tempo total de checkout é muito maior do que o habitual.
Para levar isso em conta em nossos resultados de latência, precisamos corrigir para algo chamado omissão coordenada, na qual (como explicado em uma nota no final do wrk2 README) “respostas de alta latência resultam na coordenação do gerador de carga com o servidor para evitar medição durante períodos de alta latência”. Felizmente wrk2 corrige para omissão coordenada por padrão (para mais detalhes sobre omissão coordenada, veja o README).
Quando o HAProxy MT esgota a CPU a 85.000 RPS, muitos pedidos experimentam alta latência. Eles são corretamente incluídos nos dados porque nós estamos corrigindo para omissão coordenada. Basta um ou dois pedidos de alta latência para atrasar a carga de uma página e resultar na percepção de um mau desempenho. Dado que um sistema real está servindo múltiplos usuários ao mesmo tempo, mesmo que apenas 1% das requisições tenham alta latência (o valor no percentil 99), uma grande proporção de usuários é potencialmente afetada.
Conclusão
Um dos principais pontos do benchmarking de desempenho é determinar se a sua aplicação é responsiva o suficiente para satisfazer os usuários e mantê-los voltando.
Both NGINX e HAProxy são baseados em software e têm arquiteturas guiadas por eventos. Enquanto o HAProxy MP oferece melhor desempenho do que o HAProxy MT, a falta de partilha de estado entre os processos torna a gestão mais complexa, como detalhamos no HAProxy: Configuração e Versionamento. O HAProxy MT resolve estas limitações, mas à custa de um desempenho inferior, como demonstrado nos resultados.
Com o NGINX, não existem tradeoffs – porque os processos partilham estado, não há necessidade de um modo multithreading. Você obtém o desempenho superior do multi-processamento sem as limitações que fazem com que o HAProxy desencoraje o seu uso.