NGINX és HAProxy: A felhasználói élmény tesztelése a felhőben
Néhány teljesítmény-összehasonlító mérőszám a csúcsteljesítményt vagy a másodpercenkénti kéréseket (RPS) méri, de ezek a mérőszámok túlságosan leegyszerűsíthetik a teljesítményt a valós helyszíneken. Kevés szervezet futtatja szolgáltatásait a csúcsteljesítményen vagy annak közelében, ahol a teljesítmény 10%-os változása mindkét irányban jelentős különbséget jelenthet. A webhely által igényelt áteresztőképesség vagy RPS nem végtelen, hanem olyan külső tényezők határozzák meg, mint az egyidejűleg kiszolgálandó felhasználók száma és az egyes felhasználók aktivitási szintje. Végső soron az a legfontosabb, hogy a felhasználók a lehető legjobb szintű szolgáltatást kapják. A végfelhasználókat nem érdekli, hogy hányan látogatják még a webhelyét. Őket csak az érdekli, hogy milyen szolgáltatást kapnak, és nem mentegetik a rossz teljesítményt azért, mert a rendszer túlterhelt.
Ez elvezet minket ahhoz a megfigyeléshez, hogy a legfontosabb az, hogy egy szervezet konzisztens, alacsony késleltetésű teljesítményt nyújtson minden felhasználójának, még nagy terhelés mellett is. Az Amazon Elastic Compute Cloudon (EC2) fordított proxyként futó NGINX és HAProxy összehasonlításakor két dolgot tűztünk ki célul:
- Meghatározni, hogy az egyes proxy-k milyen szintű terhelést tudnak kényelmesen kezelni
- A késleltetés százalékos eloszlását gyűjteni, amely szerintünk a felhasználói élménnyel legközvetlenebbül összefüggő mérőszám
Tesztelési protokollok és gyűjtött mérőszámok
A terhelésgeneráló programmal wrk2 emuláltunk egy ügyfelet, aki egy meghatározott időszak alatt folyamatos kéréseket intézett HTTPS-en keresztül. A tesztelt rendszer – a HAProxy vagy az NGINX – fordított proxyként működött, titkosított kapcsolatot hozott létre a wrk szálak által szimulált ügyfelekkel, továbbította a kéréseket egy NGINX Plus R22-t futtató backend webszerverre, és visszaküldte a webszerver által generált választ (egy fájlt) az ügyfélnek.
A három komponens (ügyfél, fordított proxy és webszerver) mindegyike Ubuntu 20.04.1 LTS-t futtatott egy c5n.2xlarge Amazon Machine Image (AMI) c5n.2xlarge Amazon Machine Image (AMI) EC2-ben.
Mint említettük, minden egyes tesztfuttatásból összegyűjtöttük a teljes késleltetés százalékos eloszlását. A késleltetést úgy határozzuk meg, mint a kérés generálása és a válasz fogadása között eltelt idő. A késleltetési percentilis eloszlás a tesztidőszak alatt gyűjtött késleltetési méréseket a legmagasabb (legnagyobb késleltetés) és a legalacsonyabb között rendezi.
Tesztelési módszertan
Kliens
A wrk2 (4.0.0 verzió) segítségével a következő szkriptet futtattuk az Amazon EC2-példányon:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/A webes alkalmazást elérő sok ügyfél szimulálása érdekében 4 wrk szálat hoztunk létre, amelyek együttesen 100 kapcsolatot hoztak létre a fordított proxyhoz. A 30 másodperces tesztfutás során a szkript meghatározott számú RPS-t generált. Ezek a paraméterek a következő wrk2 beállításoknak feleltek meg:
-
‑topció – Létrehozandó szálak száma (4) -
‑copció – Létrehozandó TCP-kapcsolatok száma (100) -
‑dopció – A tesztidőszak másodperceinek száma (30 másodperc) -
‑Ropció. Az ügyfél által kiadott RPS-ek száma -
‑‑latencyopció – A kimenet tartalmazza a korrigált késleltetési százalékos információkat
A tesztfuttatások során fokozatosan növeltük az RPS-ek számát, amíg az egyik proxy el nem érte a 100%-os CPU-kihasználtságot. További megbeszélésért lásd: Teljesítményeredmények.
A kliens és a proxy közötti összes kapcsolat HTTPS-en keresztül, TLSv1.3-mal történt. ECC-t használtunk 256 bites kulcsmérettel, Perfect Forward Secrecy-vel és a TLS_AES_256_GCM_SHA384 titkosítási csomaggal. (Mivel a TLSv1.2-t még mindig gyakran használják az interneten, a teszteket ezzel is újra lefuttattuk; az eredmények annyira hasonlóak voltak a TLSv1.3 eredményeihez, hogy azokat itt nem közöljük.)
HAProxy:
A HAProxy 2.3-as (stabil) verzióját állítottuk be fordított proxyként.
Egy népszerű weboldalon az egyidejű felhasználók száma hatalmas lehet. A nagy forgalom kezeléséhez a fordított proxynek képesnek kell lennie a skálázásra, hogy kihasználja a több magot. A skálázásnak két alapvető módja van: a többprocesszoros és a többszálú feldolgozás. Mind az NGINX, mind a HAProxy támogatja a többszálú feldolgozást, de van egy fontos különbség – a HAProxy implementációjában a folyamatok nem osztják meg a memóriát (míg az NGINX-ben igen). Az, hogy az állapotot nem lehet megosztani a folyamatok között, több következménnyel jár a HAProxy esetében:
- A konfigurációs paramétereket – beleértve a limiteket, statisztikákat és sebességeket – minden egyes folyamathoz külön kell definiálni.
- A teljesítménymetrikákat folyamatonként gyűjtik; ezek kombinálása további konfigurációt igényel, ami meglehetősen összetett lehet.
- Minden folyamat külön kezeli az állapotellenőrzéseket, így a célkiszolgálók vizsgálata folyamatonként történik, nem pedig kiszolgálónként, ahogyan az elvárható lenne.
- A munkamenet-megmaradás nem lehetséges.
- A HAProxy Runtime API-n keresztül végrehajtott dinamikus konfigurációs módosítás egyetlen folyamatra vonatkozik, így az API-hívást minden egyes folyamathoz meg kell ismételni.
A felsorolt problémák miatt a HAProxy erősen lebeszél a többprocesszoros megvalósítás használatáról. Hogy közvetlenül a HAProxy konfigurációs kézikönyvéből idézzek:
A MULTIPLE PROCESSES HASZNÁLATA NEHÉBB DEBUG-OLNI ÉS TÉNYLEG TILOS.
A HAProxy az 1.8-as verzióban vezette be a multi-threadinget a multi-processing alternatívájaként. A többszálúság többnyire megoldja az állapotmegosztás problémáját, de ahogyan azt a Teljesítményeredményeknél tárgyaljuk, többszálú üzemmódban a HAProxy nem teljesít olyan jól, mint többprocesszoros üzemmódban.
A HAProxy konfigurációnk tartalmazta a többszálas üzemmód (HAProxy MT) és a többprocesszoros üzemmód (HAProxy MP) biztosítását is. Ahhoz, hogy a tesztelés során az egyes RPS-szinteken váltogassuk az üzemmódokat, a megfelelő sorokat kommentáltuk és kommentár nélkülivé tettük, majd újraindítottuk a HAProxy-t, hogy a konfiguráció érvénybe lépjen:
$ sudo service haproxy restartItt a konfiguráció a HAProxy MT biztosításával: négy szál jön létre egy folyamat alatt, és minden szál egy CPU-hoz van rögzítve. A HAProxy MP esetében (itt ki van kommentálva) négy folyamat van egyenként egy CPU-hoz szegezve.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Konfiguráció és verziószám
Az NGINX Open Source 1.18.0-s verzióját telepítettük fordított proxyként.
A gépen rendelkezésre álló összes mag (ebben az esetben négy) használatához a worker_processes direktívához a auto paramétert adtuk meg, ami a repository-ból terjesztett alapértelmezett nginx.conf fájlban is ez a beállítás. Ezenkívül a worker_cpu_affinity direktívát is felvettük, hogy minden egyes munkafolyamatot egy CPU-hoz kössünk (a második paraméterben minden 1 egy CPU-t jelöl a gépen).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Teljesítményeredmények
Az alkalmazás front endjeként a fordított proxy teljesítménye kritikus fontosságú.
Minden fordított proxy-t (NGINX, HAProxy MP és HAProxy MT) növekvő számú RPS mellett teszteltünk, amíg az egyik el nem érte a 100%-os CPU-kihasználtságot. Mindhárom hasonlóan teljesített azokon az RPS-szinteken, ahol a CPU nem merült ki.
A 100%-os CPU-kihasználtság elérése először a HAProxy MT esetében következett be 85 000 RPS-nél, és ezen a ponton a teljesítmény drámaian romlott mind a HAProxy MT, mind a HAProxy MP esetében. Itt bemutatjuk az egyes reverz proxy-k késleltetési százalékos eloszlását ezen a terhelési szinten. A diagramot a wrk szkript kimenetéből rajzoltuk ki a GitHubon elérhető HdrHistogram program segítségével.
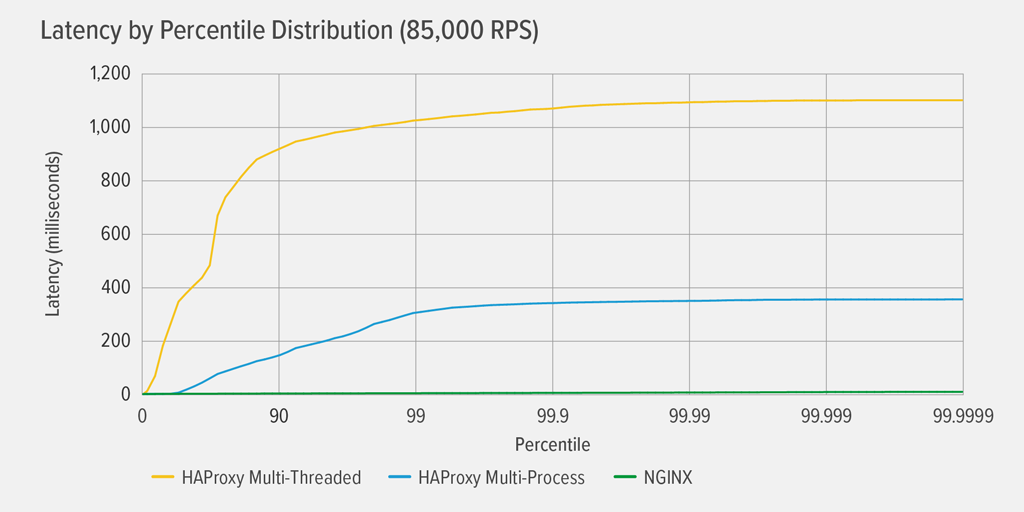
A 85 000 RPS-nél a HAProxy MT-vel a késleltetés hirtelen emelkedik a 90. percentilisig, majd körülbelül 1100 milliszekundumnál (ms) fokozatosan kiegyenlítődik.
A HAProxy MP jobban teljesít, mint a HAProxy MT – a késleltetés a 99. percentilisig lassabban emelkedik, majd nagyjából 400 ms-nál kezd kiegyenlítődni. (A HAProxy MP hatékonyságának megerősítéseként megfigyeltük, hogy a HAProxy MT minden RPS-szinten valamivel több CPU-t használt, mint a HAProxy MP.)
ANGINX gyakorlatilag semmilyen percentilisnél nem szenved késleltetést. A legnagyobb késleltetés, amelyet bármely jelentős számú felhasználó tapasztalhat (a 99,9999. percentilisnél), nagyjából 8 ms.
Mit mondanak ezek az eredmények a felhasználói élményről? Ahogy a bevezetőben említettük, az igazán fontos mérőszám a válaszidő a végfelhasználó szemszögéből, és nem a tesztelt rendszer szolgáltatási ideje.
Egy gyakori tévhit, hogy egy eloszlásban a késleltetési idő mediánja reprezentálja legjobban a felhasználói élményt. Valójában a medián az a szám, amelynél a válaszidők körülbelül fele rosszabb! A felhasználók jellemzően sok kérést adnak ki és sok erőforrást érnek el oldalbetöltésenként, így a kéréseik közül többnek a késleltetési ideje biztosan a diagram felső percentiliseinél (99. és 99,9999. között) van. Mivel a felhasználók annyira intoleránsak a rossz teljesítménnyel szemben, a magas percentiliseknél lévő késleltetések azok, amelyeket a legnagyobb valószínűséggel észrevesznek.
Gondoljon erre így: az élelmiszerboltban történő fizetés élményét az határozza meg, hogy mennyi időbe telik, mióta beállt a pénztári sorba, és nem csak az, hogy a pénztárosnak mennyi időbe telik, amíg a tételeket összeírja. Ha például az Ön előtt lévő vásárló vitatja egy termék árát, és a pénztárosnak szólnia kell valakinek, hogy ellenőrizze azt, akkor az Ön teljes pénztári ideje sokkal hosszabb lesz a szokásosnál.
Hogy ezt figyelembe vegyük a késleltetési eredményeinkben, korrigálnunk kell az úgynevezett koordinált kihagyásnak nevezett dolgot, amelyben (amint azt a wrk2 README végén található megjegyzésben kifejtjük) “a nagy késleltetésű válaszok azt eredményezik, hogy a terhelésgenerátor koordinál a szerverrel, hogy elkerülje a mérést a nagy késleltetésű időszakokban”. Szerencsére a wrk2 alapértelmezés szerint korrigálja a koordinált kihagyást (a koordinált kihagyással kapcsolatos további részletekért lásd a README-t).
Amikor a HAProxy MT 85 000 RPS mellett kimeríti a CPU-t, sok kérésnél nagy késleltetés tapasztalható. Ezek jogosan szerepelnek az adatokban, mivel korrigáljuk a koordinált kihagyást. Elég egy-két nagy késleltetésű kérés ahhoz, hogy késleltesse az oldal betöltését, és a rossz teljesítmény érzékelését eredményezze. Tekintettel arra, hogy egy valós rendszer egyszerre több felhasználót szolgál ki, még ha a kéréseknek csak 1%-a rendelkezik magas késleltetéssel (a 99. percentilis értéke), akkor is a felhasználók nagy része potenciálisan érintett.
Következtetés
A teljesítményértékelés egyik fő szempontja annak meghatározása, hogy az alkalmazás elég érzékeny-e ahhoz, hogy a felhasználók elégedettek legyenek és visszatérjenek.
Az NGINX és a HAProxy is szoftveralapú és eseményvezérelt architektúrával rendelkezik. Bár a HAProxy MP jobb teljesítményt nyújt, mint a HAProxy MT, az állapotmegosztás hiánya a folyamatok között bonyolultabbá teszi a kezelést, ahogy azt a HAProxy esetében részleteztük: Konfiguráció és verziókezelés. A HAProxy MT kezeli ezeket a korlátokat, de az eredményekben bemutatott alacsonyabb teljesítmény rovására.
Az NGINX esetében nincsenek kompromisszumok – mivel a folyamatok megosztják az állapotot, nincs szükség többszálú üzemmódra. Megkapja a többprocesszoros működés kiváló teljesítményét azok nélkül a korlátozások nélkül, amelyek miatt a HAProxy lebeszél a használatáról.