NGINX och HAProxy: Testning av användarupplevelse i molnet – NGINX NGINX och HAProxy: Testning av användarupplevelse i molnet: Testning av användarupplevelse i molnet
Många prestandanivåer mäter toppgenomströmning eller förfrågningar per sekund (RPS), men dessa mått kan förenkla prestandan på verkliga platser. Få organisationer kör sina tjänster vid eller nära toppgenomströmning, där en 10-procentig förändring av prestandan i endera riktningen kan göra en betydande skillnad. Den genomströmning eller RPS som en webbplats behöver är inte oändlig, utan bestäms av externa faktorer som antalet samtidiga användare som de måste betjäna och varje användares aktivitetsnivå. I slutändan är det viktigaste att dina användare får den bästa servicenivån. Slutanvändarna bryr sig inte om hur många andra som besöker din webbplats. De bryr sig bara om den service de får och ursäktar inte dålig prestanda för att systemet är överbelastat.
Detta leder oss till observationen att det viktigaste är att en organisation levererar konsekventa prestanda med låg latenstid till alla sina användare, även vid hög belastning. När vi jämförde NGINX och HAProxy som körs på Amazon Elastic Compute Cloud (EC2) som reverse proxies, ville vi göra två saker:
- Detektera vilken belastningsnivå som varje proxy bekvämt kan hantera
- Samla in latenspercentilfördelningen, som vi finner är den mätning som är mest direkt korrelerad med användarupplevelsen
Testprotokoll och insamlad mätning
Vi använde belastningsgenereringsprogrammet wrk2 för att efterlikna en klient, som gör kontinuerliga förfrågningar via HTTPS under en definierad period. Systemet som testades – HAProxy eller NGINX – fungerade som en omvänd proxy och upprättade krypterade förbindelser med de klienter som simulerades av wrk trådar, vidarebefordrade förfrågningar till en backend-webbserver som körde NGINX Plus R22 och returnerade det svar som webbservern genererade (en fil) till klienten.
Var och en av de tre komponenterna (klient, reverse proxy och webbserver) körde Ubuntu 20.04.1 LTS på en c5n.2xlarge Amazon Machine Image (AMI) i EC2.
Som nämnts samlade vi in den fullständiga percentilfördelningen för latenstid från varje testkörning. Latency definieras som den tid som förflyter mellan det att klienten genererar begäran och det att klienten tar emot svaret. En percentilfördelning för latens sorterar de latensmätningar som samlats in under testperioden från högst (mest latens) till lägst.
Testmetodik
Client
Med hjälp av wrk2 (version 4.0.0.0) körde vi följande skript på Amazon EC2-instansen:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/För att simulera många klienter som får tillgång till en webbapplikation skapades 4 wrk trådar som tillsammans upprättade 100 anslutningar till den omvända proxyn. Under den 30 sekunder långa testkörningen genererade skriptet ett visst antal RPS. Dessa parametrar motsvarar följande wrk2 alternativ:
-
‑t– Antal trådar som ska skapas (4) -
‑c– Antal TCP-anslutningar som ska skapas (100) -
‑d– Antal sekunder i testperioden (30 sekunder) -
‑R– -
‑R. Antal RPS som utfärdats av klienten -
‑‑latencyoption – Utdata innehåller korrigerad information om latenspercentilen
Vi ökade successivt antalet RPS under testkörningarna tills ett av proxysystemen fick ett 100-procentigt CPU-utnyttjande. För ytterligare diskussion, se Resultat av prestanda.
Alla anslutningar mellan klient och proxy gjordes över HTTPS med TLSv1.3. Vi använde ECC med en 256-bitars nyckelstorlek, Perfect Forward Secrecy och chiffersviten TLS_AES_256_GCM_SHA384. (Eftersom TLSv1.2 fortfarande används allmänt på Internet körde vi om testerna med den också; resultaten var så lika dem för TLSv1.3 att vi inte tar med dem här.)
HAProxy: Vi har konfigurerat HAProxy version 2.3 (stable) som reverse proxy.
Antalet samtidiga användare på en populär webbplats kan vara enormt. För att hantera den stora trafikvolymen måste din omvända proxy kunna skalas för att dra nytta av flera kärnor. Det finns två grundläggande sätt att skala: multi-processing och multi-threading. Både NGINX och HAProxy har stöd för multiprocessing, men det finns en viktig skillnad – i HAProxys implementering delar processerna inte på minnet (medan de gör det i NGINX). Oförmågan att dela tillstånd mellan processer har flera konsekvenser för HAProxy:
- Konfigurationsparametrar – inklusive gränser, statistik och hastigheter – måste definieras separat för varje process.
- Prestationsmått samlas in per process; för att kombinera dem krävs ytterligare konfigurering, vilket kan vara ganska komplext.
- Varje process hanterar hälsokontroller separat, så målservrar undersöks per process i stället för per server som förväntat.
- Sessionshållbarhet är inte möjlig.
- En dynamisk konfigurationsändring som görs via HAProxy Runtime API gäller en enda process, så du måste upprepa API-anropet för varje process.
På grund av de här problemen avråder HAProxy starkt från att använda implementeringen av multiprocesser. För att citera direkt från HAProxys konfigurationshandbok:
Användning av flera processer är svårare att felsöka och avråds verkligen från.
HAProxy introducerade multi-threading i version 1.8 som ett alternativ till multi-processing. Multi-threading löser till största delen problemet med delning av tillstånd, men som vi diskuterar i resultat av prestanda presterar HAProxy inte lika bra i multi-thread-läge som i multi-process-läge.
Vår HAProxy-konfiguration omfattade tillhandahållande av både flertrådsläge (HAProxy MT) och flerprocessläge (HAProxy MP). För att växla mellan lägena på varje RPS-nivå under testningen kommenterade och avkommenterade vi lämpliga rader och startade om HAProxy för att konfigurationen skulle träda i kraft:
$ sudo service haproxy restartHär är konfigurationen med HAProxy MT: fyra trådar skapas under en process och varje tråd är kopplad till en CPU. För HAProxy MP (kommenterat här) finns det fyra processer som var och en är kopplad till en CPU.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Konfiguration och versionering
Vi använde NGINX Open Source version 1.18.0 som omvänd proxy.
För att använda alla kärnor som finns tillgängliga på maskinen (fyra i det här fallet) inkluderade vi parametern auto i worker_processes-direktivet, vilket också är inställningen i standardfilen nginx.conf som distribueras från vårt förråd. Dessutom inkluderades worker_cpu_affinity-direktivet för att knyta varje arbetsprocess till en CPU (varje 1 i den andra parametern betecknar en CPU i maskinen).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Prestandaresultat
Som front end till din applikation är prestandan hos din omvända proxy kritisk.
Vi testade varje omvänd proxy (NGINX, HAProxy MP och HAProxy MT) med ett ökande antal RPS tills en av dem uppnådde 100 % CPU-användning. Alla tre presterade på liknande sätt på de RPS-nivåer där CPU inte uttömdes.
Det var först HAProxy MT som nådde 100 % CPU-användning, vid 85 000 RPS, och då försämrades prestandan dramatiskt för både HAProxy MT och HAProxy MP. Här presenterar vi latenspercentilfördelningen för varje omvänd proxy vid den belastningsnivån. Diagrammet ritades från utdata från skriptet wrk med hjälp av programmet HdrHistogram som finns på GitHub.
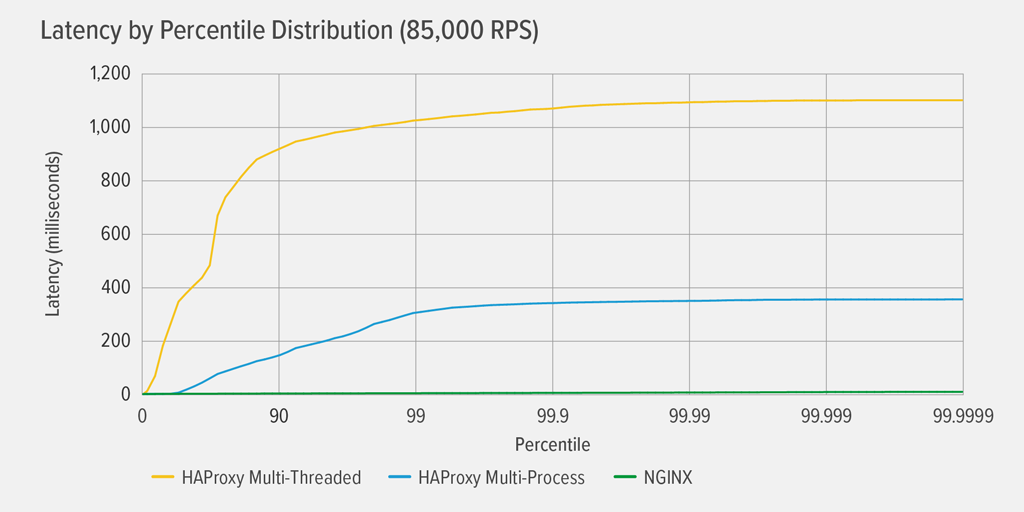
Vid 85 000 RPS stiger latensen med HAProxy MT abrupt fram till den 90:e percentilen, för att sedan gradvis plana ut vid cirka 1100 millisekunder (ms).
HAProxy MP presterar bättre än HAProxy MT – latensen stiger i långsammare takt fram till den 99:e percentilen, varefter den börjar plana ut vid ungefär 400 ms. (Som en bekräftelse på att HAProxy MP är effektivare observerade vi att HAProxy MT använde något mer processorkraft än HAProxy MP på varje RPS-nivå.)
NGINX lider praktiskt taget ingen latens vid någon percentil. Den högsta latenstid som ett betydande antal användare kan uppleva (vid den 99,9999:e percentilen) är ungefär 8 ms.
Vad säger dessa resultat om användarupplevelsen? Som nämndes i inledningen är det mått som verkligen spelar roll svarstiden ur slutanvändarens perspektiv, och inte servicetiden för det system som testas.
Det är en vanlig missuppfattning att medianlatenstiden i en distribution bäst representerar användarupplevelsen. I själva verket är medianen det tal som ungefär hälften av svarstiderna är sämre än! Användare skickar vanligtvis många förfrågningar och får tillgång till många resurser per sidladdning, så flera av deras förfrågningar kommer garanterat att uppleva fördröjningar vid de övre percentilerna i diagrammet (99:e till 99,9999:e). Eftersom användarna är så intoleranta mot dålig prestanda är det de höga percentilerna som de sannolikt lägger märke till.
Tänk på det så här: din upplevelse av att checka ut i en livsmedelsbutik bestäms av hur lång tid det tar att lämna butiken från det ögonblick då du ställde dig i kassakön, inte bara hur lång tid det tog för kassörskan att räkna upp dina varor. Om t.ex. en kund framför dig ifrågasätter priset på en vara och kassörskan måste få någon att bekräfta det, blir din totala utcheckningstid mycket längre än vanligt.
För att ta hänsyn till detta i våra latensresultat måste vi korrigera för något som kallas samordnad utelämnande, där (som förklaras i en anmärkning i slutet av wrk2 README) ”svar med hög latens resulterar i att belastningsgeneratorn samordnar sig med servern för att undvika mätning under perioder med hög latens”. Som tur är korrigerar wrk2 som standard för samordnad utelämnande (för mer information om samordnad utelämnande, se README).
När HAProxy MT uttömmer processorn med 85 000 RPS upplever många förfrågningar hög latens. De är rättmätigt inkluderade i uppgifterna eftersom vi korrigerar för samordnad utelämnande. Det räcker med en eller två förfrågningar med hög latens för att fördröja en sidladdning och resultera i en uppfattning om dålig prestanda. Med tanke på att ett verkligt system betjänar flera användare samtidigt, även om endast 1 % av förfrågningarna har hög latenstid (värdet vid den 99:e percentilen), påverkas potentiellt en stor andel av användarna.
Slutsats
En av huvudpunkterna i prestandabänkmärkning är att avgöra om din app är tillräckligt lyhörd för att tillfredsställa användarna och få dem att komma tillbaka.
Både NGINX och HAProxy är mjukvarubaserade och har händelsestyrda arkitekturer. HAProxy MP ger bättre prestanda än HAProxy MT, men bristen på delning av tillstånd mellan processerna gör hanteringen mer komplex, vilket vi beskriver i detalj i HAProxy: Konfigurering och versionering. HAProxy MT åtgärdar dessa begränsningar, men på bekostnad av sämre prestanda, vilket framgår av resultaten.
Med NGINX finns det inga kompromisser – eftersom processerna delar tillstånd finns det inget behov av ett flertrådningsläge. Du får den överlägsna prestandan från multiprocessering utan de begränsningar som gör att HAProxy avskräcker från att använda den.