VGG16 – Rede Convolucional para Classificação e Detecção
VGG16 é um modelo de rede neural convolucional proposto por K. Simonyan e A. Zisserman da Universidade de Oxford no artigo “Very Deep Convolutional Networks for Large-Scale Image Recognition”. O modelo atinge 92,7% de precisão nos testes top-5 da ImageNet, que é um conjunto de dados com mais de 14 milhões de imagens pertencentes a 1000 classes. Foi um dos modelos mais famosos submetidos ao ILSVRC-2014. Ele faz a melhoria sobre o AlexNet substituindo grandes filtros do tamanho do kernel (11 e 5 na primeira e segunda camada convolucional, respectivamente) por múltiplos filtros 3×3 do tamanho do kernel, um após o outro. O VGG16 foi treinado durante semanas e estava usando a GPU NVIDIA Titan Black.
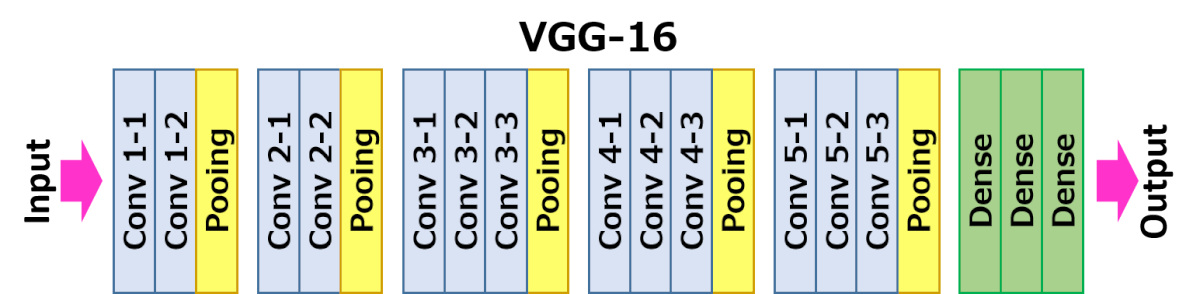
DataSet
ImageNet é um conjunto de dados com mais de 15 milhões de imagens rotuladas de alta resolução pertencentes a cerca de 22.000 categorias. As imagens foram coletadas da web e etiquetadas por rotuladores humanos usando a ferramenta de crowd-sourcing do Amazon’s Mechanical Turk. A partir de 2010, como parte do Pascal Visual Object Challenge, foi realizado um concurso anual chamado ImageNet Desafio de Reconhecimento Visual em Grande Escala (ILSVRC). O ILSVRC usa um subconjunto da ImageNet com cerca de 1000 imagens em cada uma das 1000 categorias. No total, há aproximadamente 1,2 milhões de imagens de treinamento, 50.000 imagens de validação e 150.000 imagens de teste. A ImageNet consiste em imagens de resolução variável. Portanto, as imagens foram reduzidas a uma resolução fixa de 256×256. Dada uma imagem retangular, a imagem é redimensionada e recortada do patch central 256×256 da imagem resultante.
A Arquitetura
A arquitetura descrita abaixo é VGG16.
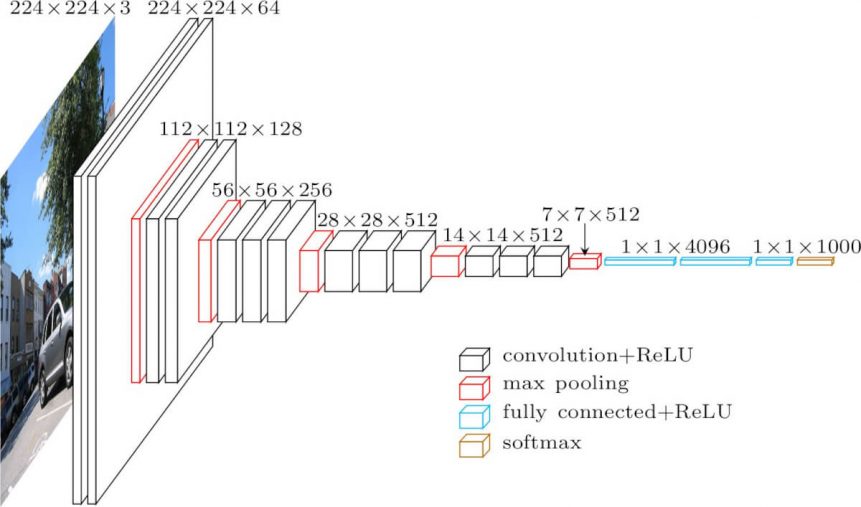
A entrada para a camada cov1 é de tamanho fixo 224 x 224 imagem RGB. A imagem é passada através de uma pilha de camadas convolutivas (conv.), onde os filtros foram utilizados com um campo receptivo muito pequeno: 3×3 (que é o menor tamanho para capturar a noção de esquerda/direita, para cima/baixo, centro). Em uma das configurações, ele também utiliza filtros de convolução 1×1, o que pode ser visto como uma transformação linear dos canais de entrada (seguido por não-linearidade). O passo de convolução é fixado em 1 pixel; o acolchoamento espacial da entrada da camada de conv. é tal que a resolução espacial é preservada após a convolução, ou seja, o acolchoamento é de 1 pixel para camadas de conv. 3×3. O agrupamento espacial é realizado por cinco camadas de agrupamento máximo, que seguem algumas das camadas conv. (nem todas as camadas conv. são seguidas pelo agrupamento máximo). O Max-pooling é realizado sobre uma janela de 2×2 pixels, com passo 2.
Três camadas totalmente conectadas (FC) seguem uma pilha de camadas convolutivas (que tem uma profundidade diferente em arquiteturas diferentes): as duas primeiras têm 4096 canais cada uma, a terceira realiza a classificação ILSVRC de 1000 canais e assim contém 1000 canais (um para cada classe). A camada final é a camada soft-max. A configuração das camadas totalmente conectadas é a mesma em todas as redes.
Todas as camadas ocultas estão equipadas com a não-linearidade de retificação (ReLU). Note-se também que nenhuma das redes (excepto uma) contém normalização da resposta local (LRN), tal normalização não melhora o desempenho no conjunto de dados ILSVRC, mas leva a um aumento do consumo de memória e do tempo de computação.
Configurações
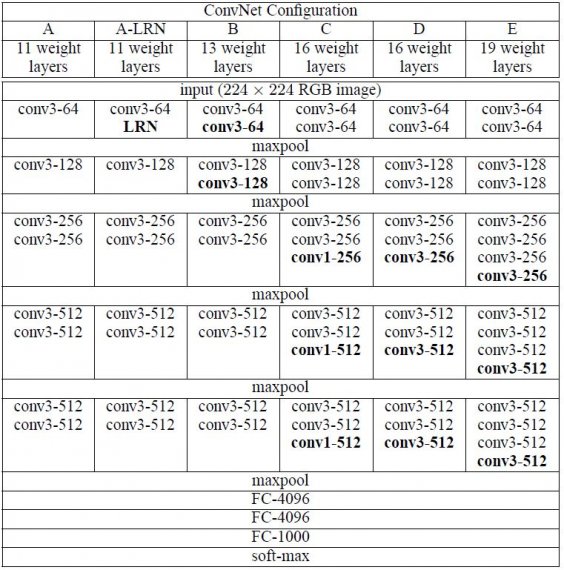
As configurações da ConvNet estão delineadas na figura 2. As redes são referidas aos seus nomes (A-E). Todas as configurações seguem o desenho genérico presente na arquitetura e diferem apenas na profundidade: de 11 camadas de peso na rede A (8 camadas conv. e 3 FC) a 19 camadas de peso na rede E (16 camadas conv. e 3 FC). A largura das camadas conv. (o número de canais) é bastante pequena, começando de 64 na primeira camada e depois aumentando por um factor de 2 após cada camada de max-pooling, até atingir 512.
Casos de uso e implementação
Felizmente, há dois grandes inconvenientes com a VGGNet:
- É dolorosamente lento para treinar.
- Os próprios pesos da arquitetura de rede são bastante grandes (em relação a disco/largura de banda).
Devido à sua profundidade e número de nós totalmente conectados, a VGGG16 é superior a 533MB. Isto torna a implementação do VGG uma tarefa cansativa. O VGG16 é usado em muitos problemas de classificação de imagens de aprendizagem profunda; contudo, arquiteturas de rede menores são frequentemente mais desejáveis (como SqueezeNet, GoogLeNet, etc.). Mas é um grande bloco de construção para fins de aprendizagem pois é fácil de implementar.
Resultado
VGG16 supera significativamente a geração anterior de modelos nos concursos ILSVRC-2012 e ILSVRC-2013. O resultado VGG16 também está competindo pelo vencedor da tarefa de classificação (GoogLeNet com erro de 6,7%) e supera substancialmente o vencedor do ILSVRC-2013 Clarifai, que alcançou 11,2% com dados externos de treinamento e 11,7% sem ele. Quanto ao desempenho da rede única, a arquitetura VGG16 alcança o melhor resultado (erro de teste de 7,0%), superando um único GoogLeNet em 0,9%.
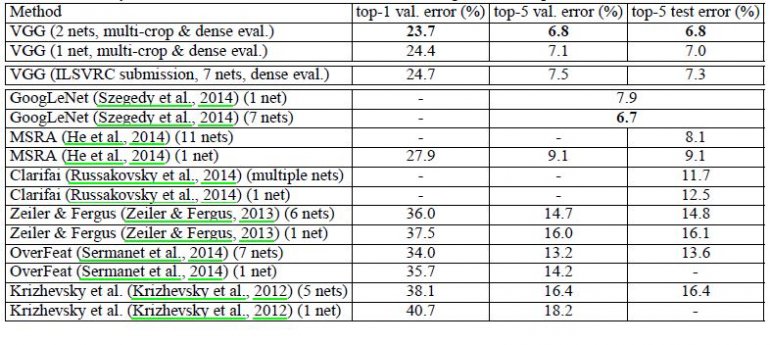
Foi demonstrado que a profundidade de representação é benéfica para a precisão da classificação, e que o desempenho de ponta no conjunto de dados do desafio ImageNet pode ser alcançado usando uma arquitetura convencional ConvNet com profundidade substancialmente aumentada.