Using Convolutional Neural Networks for Image Recognition
Este artigo foi originalmente publicado no site da Cadence. Ele é reimpresso aqui com a permissão da Cadence.
Redes Neurais Convolucionais (CNNs) são amplamente utilizadas em problemas de reconhecimento de padrões e imagens, pois possuem uma série de vantagens em comparação com outras técnicas. Este white paper cobre os conceitos básicos das CNNs incluindo uma descrição das várias camadas utilizadas. Usando o reconhecimento de sinais de tráfego como exemplo, discutimos os desafios do problema geral e introduzimos algoritmos e software de implementação desenvolvidos pela Cadence que podem trocar carga computacional e energia por uma modesta degradação nas taxas de reconhecimento de sinais. Descrevemos os desafios do uso de CNNs em sistemas incorporados e introduzimos as principais características do processador de sinais digitais (DSP) Cadence® Tensilica® Vision P5 para Imaging e Computer Vision e softwares que o tornam tão adequado para aplicações CNN em muitas tarefas de imagem e reconhecimento relacionadas.
O que é uma CNN?
Uma rede neural é um sistema de “neurônios” artificiais interconectados que trocam mensagens entre si. As conexões têm pesos numéricos que são ajustados durante o processo de treinamento, para que uma rede devidamente treinada responda corretamente quando apresentada com uma imagem ou padrão a reconhecer. A rede consiste em múltiplas camadas de “neurônios” detectores de características. Cada camada tem muitos neurônios que respondem a diferentes combinações de inputs das camadas anteriores. Como mostrado na Figura 1, as camadas são construídas de modo que a primeira camada detecta um conjunto de padrões primitivos no input, a segunda camada detecta padrões de padrões, a terceira camada detecta padrões desses padrões, e assim por diante. As CNNs típicas usam 5 a 25 camadas distintas de reconhecimento de padrões.
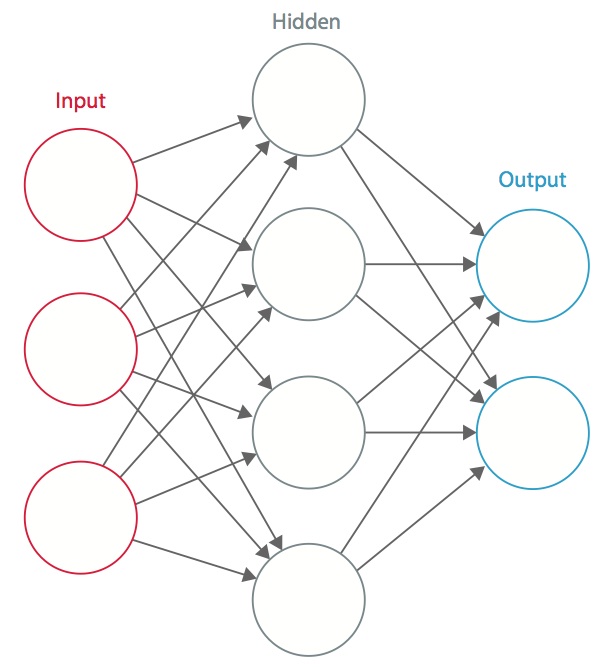
Figure 1: Uma rede neural artificial
Treinamento é realizado usando um conjunto de dados “etiquetados” de entradas em uma ampla variedade de padrões representativos de entradas que são etiquetados com sua resposta de saída pretendida. O treinamento usa métodos de uso geral para determinar iterativamente os pesos dos neurônios de características intermediárias e finais. A Figura 2 demonstra o processo de treinamento em um nível de bloco.
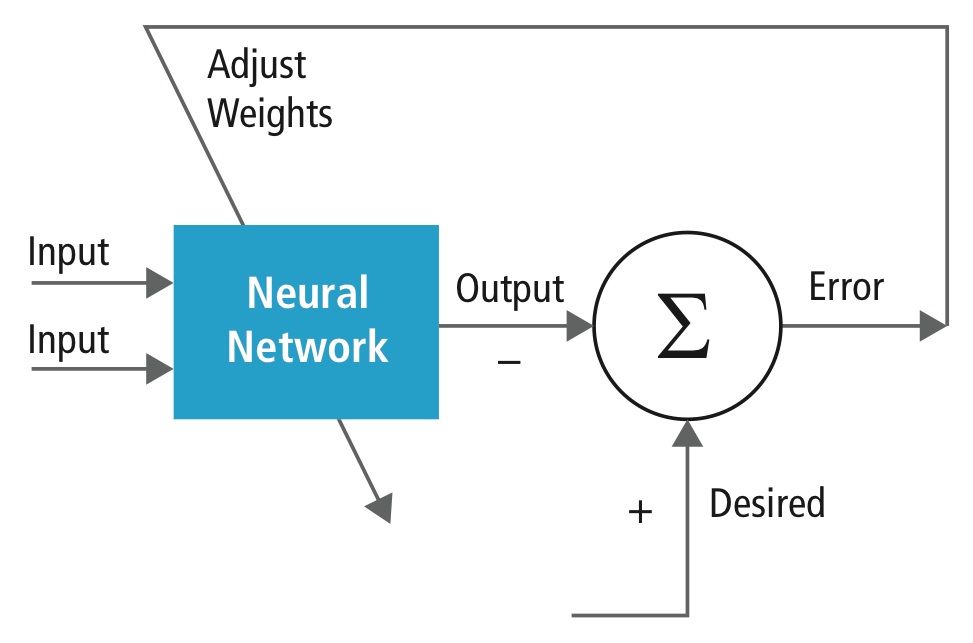
Figure 2: Treinamento de redes neurais
Redes neurais são inspiradas em sistemas neurais biológicos. A unidade computacional básica do cérebro é um neurônio e elas estão conectadas com sinapses. A Figura 3 compara um neurônio biológico com um modelo matemático básico .


Figura 3: Ilustração de um neurônio biológico (topo) e seu modelo matemático (fundo)
Em um sistema neural animal real, um neurônio é percebido como recebendo sinais de entrada de seus dendritos e produzindo sinais de saída ao longo de seu axônio. O axônio se ramifica e se conecta via sinapses aos dendritos de outros neurônios. Quando a combinação de sinais de entrada atinge alguma condição de limiar entre seus dendritos de entrada, o neurônio é acionado e sua ativação é comunicada aos neurônios sucessores.
No modelo computacional da rede neural, os sinais que viajam ao longo dos axônios (por exemplo, x0) interagem multiplicativamente (por exemplo, w0x0) com os dendritos dos outros neurônios com base na força sináptica daquela sinapse (por exemplo, w0). Os pesos sinápticos são aprendidos e controlam a influência de um ou outro neurônio. Os dendritos levam o sinal para o corpo celular, onde todos eles são somados. Se a soma final estiver acima de um limiar especificado, o neurônio dispara, enviando um espigão ao longo de seu axônio. No modelo computacional, assume-se que os tempos precisos da queima não importam e que apenas a freqüência da queima comunica informação. Baseado na interpretação do código da taxa, a taxa de disparo do neurônio é modelada com uma função de ativação ƒ que representa a freqüência dos espigões ao longo do axônio. Uma escolha comum da função de ativação é a sigmóide. Em resumo, cada neurônio calcula o produto de pontos de entrada e pesos, adiciona o viés e aplica a não-linearidade como função de ativação (por exemplo, seguindo uma função de resposta sigmóide).
A CNN é um caso especial da rede neural descrita acima. Uma CNN consiste de uma ou mais camadas convolucionais, muitas vezes com uma camada de subamostragem, que são seguidas por uma ou mais camadas totalmente conectadas como em uma rede neural padrão.
O desenho de uma CNN é motivado pela descoberta de um mecanismo visual, o córtex visual, no cérebro. O córtex visual contém muitas células que são responsáveis pela detecção da luz em pequenas sub-regiões sobrepostas do campo visual, que são chamadas de campos receptivos. Estas células actuam como filtros locais sobre o espaço de entrada, e as células mais complexas têm campos receptivos maiores. A camada de convolução em uma CNN executa a função que é executada pelas células no córtex visual .
Uma CNN típica para reconhecimento de sinais de tráfego é mostrada na Figura 4. Cada característica de uma camada recebe entradas de um conjunto de características localizadas em uma pequena vizinhança na camada anterior chamada campo receptivo local. Com campos receptivos locais, as características podem extrair características visuais elementares, tais como bordas orientadas, pontos finais, cantos, etc., que são então combinadas pelas camadas mais altas.
No modelo tradicional de reconhecimento de padrão/imagem, um extrator de características projetado à mão reúne informações relevantes da entrada e elimina variabilidades irrelevantes. O extrator é seguido por um classificador treinável, uma rede neural padrão que classifica os vetores de características em classes.
Em uma CNN, camadas de convolução desempenham o papel de extrator de características. Mas elas não são desenhadas à mão. Os pesos do kernel do filtro de convolução são decididos como parte do processo de treinamento. As camadas convolutivas são capazes de extrair as características locais porque restringem os campos receptivos das camadas ocultas a serem locais.
Figure 4: O diagrama de blocos típico de uma CNN
CNNs são usados em várias áreas, incluindo reconhecimento de imagem e padrão, reconhecimento de fala, processamento de linguagem natural, e análise de vídeo. Há uma série de razões pelas quais as redes neurais convolucionais estão se tornando importantes. Nos modelos tradicionais para reconhecimento de padrões, os extratores de características são desenhados à mão. Nas CNNs, os pesos da camada convolutiva que está sendo usada para extração de características, bem como a camada totalmente conectada que está sendo usada para classificação, são determinados durante o processo de treinamento. As estruturas de rede melhoradas das CNNs levam à economia nos requisitos de memória e complexidade de computação e, ao mesmo tempo, proporcionam melhor desempenho para aplicações onde a entrada tem correlação local (por exemplo, imagem e fala).
Requisitos grandes de recursos computacionais para treinamento e avaliação de CNNs são às vezes atendidos por unidades de processamento gráfico (GPUs), DSPs, ou outras arquiteturas de silício otimizadas para alto rendimento e baixa energia ao executar os padrões idiossincráticos de computação CNNs. De fato, processadores avançados como o Tensilica Vision P5 DSP for Imaging e Computer Vision da Cadence têm um conjunto quase ideal de recursos de computação e memória necessários para executar CNNs com alta eficiência.
Em aplicações de reconhecimento de padrões e imagens, as melhores taxas de detecção corretas possíveis (CDRs) foram alcançadas usando CNNs. Por exemplo, as CNNs alcançaram um CDR de 99,77% usando o banco de dados MNIST de dígitos manuscritos , um CDR de 97,47% com o conjunto de dados NORB de objetos 3D , e um CDR de 97,6% sobre ~5600 imagens de mais de 10 objetos . As CNNs não só dão o melhor desempenho em comparação com outros algoritmos de detecção, como até superam o desempenho humano em casos como a classificação de objetos em categorias de granulação fina, como a raça particular de cão ou espécie de ave .
Figure 5 mostra um típico pipeline de algoritmos de visão, que consiste em quatro etapas: pré-processamento da imagem, detecção de regiões de interesse (ROI) que contêm objetos prováveis, reconhecimento de objetos e tomada de decisão de visão. A etapa de pré-processamento geralmente depende dos detalhes da entrada, especialmente do sistema de câmera, e é freqüentemente implementada em uma unidade com fio fora do subsistema de visão. A tomada de decisão no final do pipeline normalmente opera em objetos reconhecidos – pode tomar decisões complexas, mas opera com muito menos dados, de modo que essas decisões não são geralmente difíceis de calcular ou problemas de memória intensiva. O grande desafio está nos estágios de detecção e reconhecimento de objetos, onde as CNNs estão agora tendo um amplo impacto.

Figure 5: Algoritmo de visão pipeline
Camadas de CNNs
Empilhando múltiplas e diferentes camadas em uma CNN, arquiteturas complexas são construídas para problemas de classificação. Quatro tipos de camadas são mais comuns: camadas de convolução, camadas de pooling/subamostragem, camadas não lineares e camadas totalmente conectadas.
Camadas de convolução
A operação de convolução extrai diferentes características da entrada. A primeira camada de convolução extrai características de baixo nível como bordas, linhas, e cantos. As camadas de nível mais alto extraem características de nível mais alto. A Figura 6 ilustra o processo de convolução 3D usado nas CNNs. O input é de tamanho N x N x D e gira com kernels H, cada um de
size k x k x D separadamente. A convolução de uma entrada com um kernel produz uma característica de saída, e com os kernels H produz independentemente as características H. A partir do canto superior esquerdo do input, cada kernel é movido da esquerda para a direita, um elemento de cada vez. Uma vez alcançado o canto superior direito, o kernel é movido um elemento no sentido descendente, e novamente o kernel é movido da esquerda para a direita, um elemento de cada vez. Este processo é repetido até
o kernel atingir o canto inferior direito. Para o caso em que N = 32 e k = 5 , existem 28 posições únicas da esquerda para a direita e 28 posições únicas de cima para baixo que o kernel pode tomar. Correspondendo a estas posições, cada característica na saída conterá 28×28 (ou seja, (N-k+1) x (N-k+1)) elementos. Para cada posição do kernel em um processo de janela deslizante, k x k x D elementos de entrada e k x k x D elementos do kernel são element-by- element multiplicados e acumulados. Assim, para criar um elemento de uma característica de saída, são necessárias operações de k x k x D multiply-accumulate.
Figure 6: Representação pictórica do processo de convolução
Camadas de pooling/subsampling
A camada de pooling/subsampling reduz a resolução das características. Torna as características robustas contra ruído e distorção. Há duas formas de fazer pooling: max pooling e pooling médio. Em ambos os casos, a entrada é dividida em espaços bidimensionais não sobrepostos. Por exemplo, na Figura 4, a camada 2 é a camada do pooling. Cada característica de entrada é 28×28 e é dividida em 14×14 regiões de tamanho 2×2. Para o agrupamento médio, a média dos quatro valores na região é calculada. Para o agrupamento máximo, o valor máximo dos quatro valores é selecionado.
Figure 7 elabora ainda mais o processo de agrupamento. A entrada é de tamanho 4×4. Para subamostragem 2×2, uma imagem 4×4 é dividida em quatro matrizes não sobrepostas de tamanho 2×2. No caso de agrupamento máximo, o valor máximo dos quatro valores na matriz 2×2 é a saída. No caso de pooling médio, a média dos quatro valores é a saída. Observe que para o output com índice (2,2), o resultado da média é uma fração que foi arredondada para o número inteiro mais próximo.
Figure 7: Representação pictórica do agrupamento máximo e do agrupamento médio
Camadas não lineares
Redes naturais em geral e CNNs em particular dependem de uma função “trigger” não linear para sinalizar uma identificação distinta – cation de características prováveis em cada camada oculta. As CNNs podem usar uma variedade de funções específicas -como unidades lineares retificadas (ReLUs) e funções de disparo contínuo (não-lineares)- para implementar eficientemente este disparo não-linear.
ReLU
A ReLU implementa a função y = max(x,0), portanto os tamanhos de entrada e saída desta camada são os mesmos. Ele aumenta as propriedades não lineares da função de decisão e da rede em geral sem afetar os campos receptivos da camada de convolução. Em comparação com as outras funções não lineares utilizadas nas CNNs (por exemplo, tangente hiperbólica, absoluta da tangente hiperbólica e sigmóide), a vantagem de uma ReLU é que a rede treina muitas vezes mais rápido. A funcionalidade ReLU é ilustrada na Figura 8, com sua função de transferência plotada acima da seta.
Figure 8: Representação pictórica da funcionalidade ReLU
Função de disparo contínuo (não-linear)
A camada não-linear opera elemento por elemento em cada característica. Uma função de disparo contínuo pode ser tangente hiperbólica (Figura 9), absoluta de tangente hiperbólica (Figura 10), ou sigmóide (Figura 11). A Figura 12 demonstra como a não-linearidade é aplicada elemento por elemento.
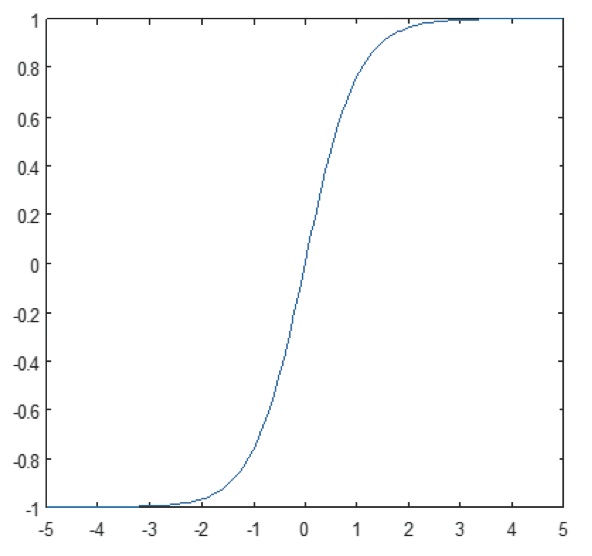
Figure 9: Lote da função tangente hiperbólica
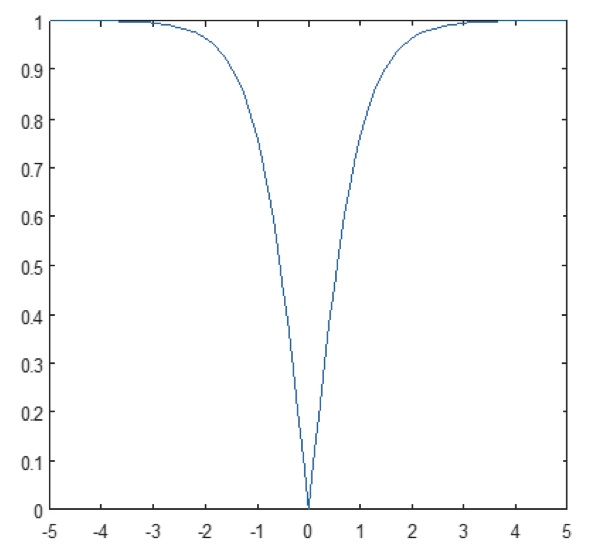
Figure 10: Lote absoluto da função tangente hiperbólica
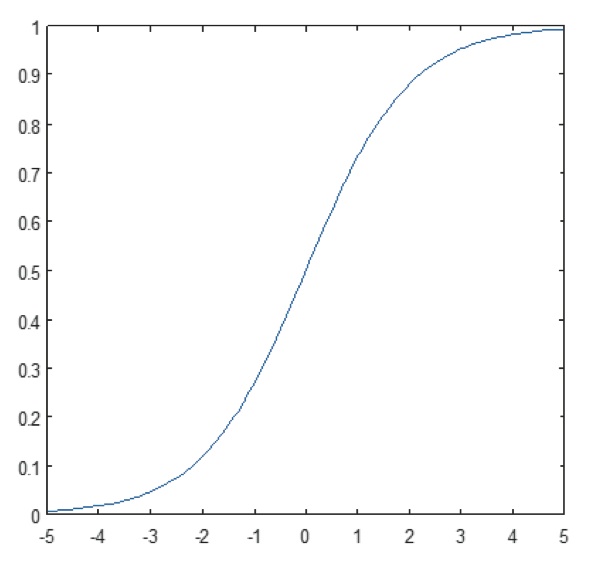
Figure 11: Lote da função sigmóide
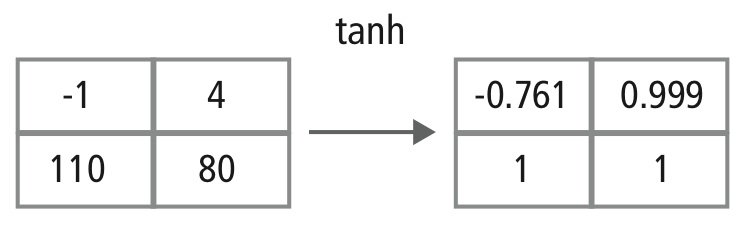
Figure 12: Representação pictórica do processamento tanh
Camadas totalmente conectadas
Camadas totalmente conectadas são frequentemente usadas como as camadas finais de uma CNN. Estas camadas somam matematicamente uma ponderação da camada anterior de características, indicando a mistura precisa de “ingredientes” para determinar um resultado de saída alvo específico. No caso de uma camada totalmente ligada, todos os elementos de todas as características da camada anterior são usados no cálculo de cada elemento de cada característica de saída.
Figure 13 explica a camada totalmente ligada L. A camada L-1 tem duas características, cada uma delas 2×2, ou seja, tem quatro elementos. A camada L tem duas características, cada uma com um único elemento.
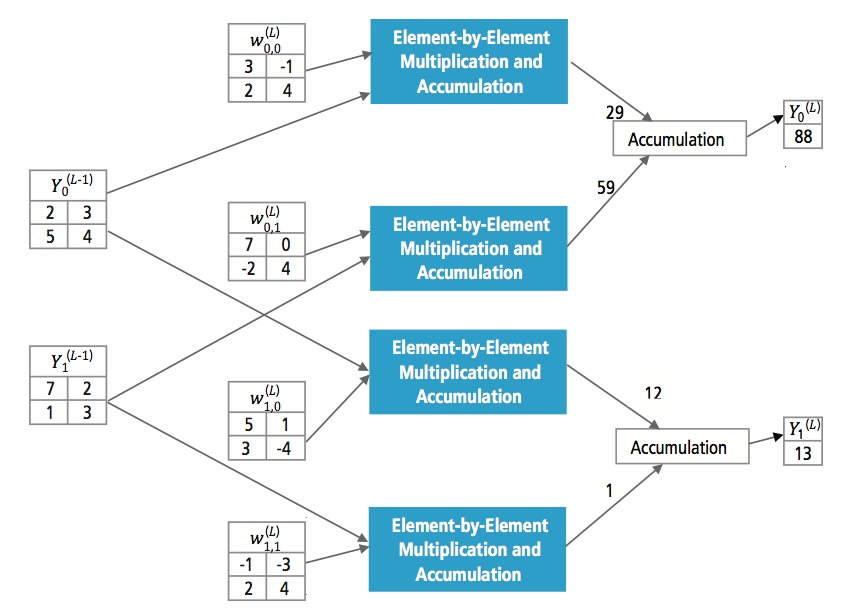
Figure 13: Processamento de uma camada totalmente conectada
Por que CNN?
Apesar de as redes neurais e outros métodos de detecção de padrões terem surgido nos últimos 50 anos, houve um desenvolvimento significativo na área de redes neurais convolucionais no passado recente. Esta seção cobre as vantagens do uso da CNN para reconhecimento de imagem.
Ruggedness to shifts and distortion in the image
Detecção usando CNN é resistente a distorções como mudança de forma devido a lentes de câmera, diferentes condições de iluminação, diferentes poses, presença de oclusões parciais, deslocamentos horizontais e verticais, etc. No entanto, as CNNs são invariantes, uma vez que a mesma configuração de peso é utilizada em todo o espaço. Em teoria, nós também podemos conseguir invariantes de deslocamento usando camadas totalmente conectadas. Mas o resultado do treinamento neste caso são múltiplas unidades com padrões de peso idênticos em diferentes locais da entrada. Para aprender estas configurações de peso, um grande número de instâncias de treinamento seria necessário para cobrir o espaço de possíveis variações.
Menos requisitos de memória
Neste mesmo caso hipotético onde usamos uma camada totalmente conectada para extrair as características, a imagem de entrada de tamanho 32×32 e uma camada oculta com 1000 características exigirá uma ordem de 106 coeficientes, um enorme requisito de memória. Na camada convolucional, os mesmos coeficientes são usados em diferentes locais no espaço, de modo que a necessidade de memória é drasticamente reduzida.
Mais fácil e melhor treino
Again usando a rede neural padrão que seria equivalente a uma CNN, porque o número de para-éteres seria muito maior, o tempo de treino também aumentaria proporcionalmente. Em uma CNN, como o número de parâmetros é drasticamente reduzido, o tempo de treinamento é proporcionalmente reduzido. Além disso, assumindo um treinamento perfeito, podemos projetar uma rede neural padrão cujo desempenho seria igual ao de uma CNN. Mas no treinamento prático,
uma rede neural padrão equivalente à CNN teria mais parâmetros, o que levaria a uma maior adição de ruído durante o processo de treinamento. Portanto, o desempenho de uma rede neural padrão equivalente a uma CNN será sempre mais fraco.
O Algoritmo de Reconhecimento para Dataset GTSRB
O Benchmark de Reconhecimento de Sinais de Tráfego Alemão (GTSRB) foi um desafio de classificação de multi-classe e imagem única realizado na Conferência Internacional Conjunta sobre Redes Neurais (IJCNN) 2011, com os seguintes requisitos
- 51.840 imagens de sinais de trânsito alemães em 43 classes (Figuras 14 e 15)
- O tamanho das imagens varia de 15×15 a 222×193
- Imagens são agrupadas por classe e faixa com pelo menos 30 imagens por faixa
- Imagens estão disponíveis como imagens coloridas (RGB), características HOG, características Haar e histogramas coloridos
- Competição é apenas para o algoritmo de classificação; algoritmo para encontrar região de interesse no quadro não é necessário
- Não é partilhada informação temporal das sequências de teste, pelo que a dimensão temporal não pode ser utilizada no algoritmo de classificação

Figure 14: GTSRB sinais de tráfego ideais

Figure 15: GTSRB sinais de tráfego com deficiências
Cadence Algorithm for Traffic Sign Signal Recognition in GTSRB Dataset
Cadence desenvolveu vários algoritmos no MATLAB para reconhecimento de sinais de tráfego usando o conjunto de dados GTSRB, começando com uma configuração de base baseada em um conhecido documento sobre reconhecimento de sinais . A taxa correta de detecção de 99,24% e esforço de computação de quase >50 milhões de multiply-adds por sinal é mostrada como um ponto verde espesso na Figura 16. A cadência alcançou resultados significativamente melhores usando nossa nova abordagem Hierárquica CNN proprietária. Neste algoritmo, 43 sinais de tráfego foram divididos em cinco famílias. No total, nós implementamos seis CNNs menores. A primeira CNN decide a que família pertence o sinal de tráfego recebido. Uma vez que a família do sinal é conhecida, a CNN (uma das cinco restantes) correspondente à família detectada é executada para decidir o sinal de tráfego dentro dessa família. Usando este algoritmo, a Cadence alcançou uma taxa de detecção correta de 99,58%, o melhor CDR alcançado no GTSRB até o momento.
Algoritmo para Performance vs. Complexidade Tradeoff
A fim de controlar a complexidade das CNNs em aplicações embarcadas, a Cadence também desenvolveu um algoritmo proprietário usando decomposição de autovalor que reduz uma CNN treinada à sua dimensão canônica. Usando este algoritmo, fomos capazes de reduzir drasticamente a complexidade da CNN sem nenhuma degradação de desempenho, ou com uma pequena redução controlada do CDR. A Figura 16 mostra os resultados alcançados:
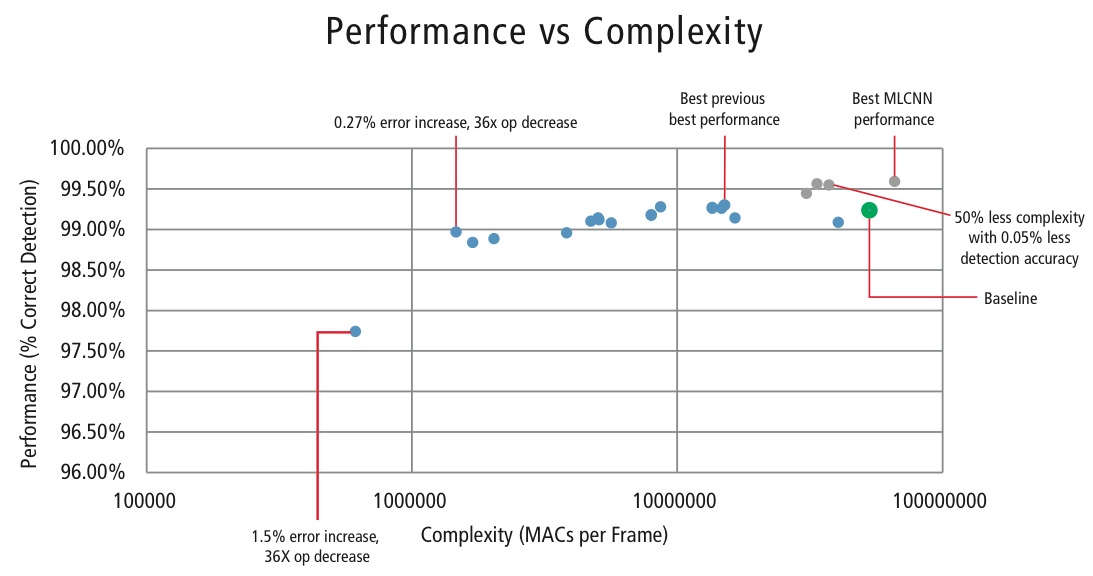
Figure 16: Gráfico de desempenho vs. complexidade para várias configurações da CNN para detectar sinais de tráfego no conjunto de dados GTSRB
O ponto verde na Figura 16 é a configuração de linha de base. Esta configuração é bastante próxima da configuração sugerida na Referência . Requer 53 MMACs por frame para uma taxa de erro de 0,76%.
- O segundo ponto da esquerda requer 1,47 milhões de MACs por frame para uma taxa de erro de 1,03%, ou seja, para um aumento na taxa de erro de 0,27%, o requisito MAC foi reduzido num factor de 36,14,
- O ponto mais à esquerda requer 0,61 MMACs por frame para se atingir uma taxa de erro de 2,26%, ou seja, o número de MACs é reduzido num factor de 86,4 vezes.
- Os pontos a azul são para uma CNN de nível único, enquanto que os pontos a vermelho são para uma CNN hierárquica. Um desempenho de 99,58% na melhor das hipóteses é alcançado pela CNN hierárquica.
CNNs em sistemas incorporados
Como mostrado na Figura 5, um subsistema de visão requer muito processamento de imagem, além de uma CNN. Para executar CNNs em um sistema embarcado com restrição de energia que suporte o processamento de imagens, ele deve cumprir os seguintes requisitos:
- Disponibilidade de alto desempenho computacional: Para uma implementação CNN típica, bilhões de MACs por segundo é o requisito.
- Largura de banda maior: No caso de uma camada totalmente conectada usada para fins de classificação, cada coeficiente é usado em multiplicação apenas uma vez. Assim, o requisito de largura de banda da loja é maior do que o número de MACs realizados pelo processador.
- Requisito de potência dinâmica baixa: O sistema deve consumir menos energia. Para resolver este problema, é necessária uma implementação de ponto fixo, que impõe o requisito de satisfazer os requisitos de desempenho usando o número mínimo possível de bits finitos.
- Flexibilidade: Deve ser possível atualizar facilmente o projeto existente para um novo projeto de melhor desempenho.
Os recursos computacionais são sempre uma restrição nos sistemas embarcados, se o caso de uso permitir uma pequena degradação no desempenho, é útil ter um algoritmo que possa alcançar uma enorme economia em complexidade computacional ao custo de uma pequena degradação controlada no desempenho. Portanto, o trabalho da Cadence em um algoritmo para alcançar complexidade versus uma troca de desempenho, como explicado na seção anterior, tem grande relevância para implementar CNNs em sistemas embarcados.
CNNs em processadores Tensilica
O DSP Tensilica Vision P5 é um DSP de alto desempenho, de baixa potência, projetado especificamente para processamento de imagem e visão por computador. O DSP tem uma arquitetura VLIW com suporte a SIMD. Ele tem cinco slots de edição em uma palavra de instrução de até 96 bits e pode carregar até 1024 bits de palavras da memória a cada ciclo. Os registros internos e unidades de operação variam de 512 bits a 1536 bits, onde os dados são representados como 16, 32, ou 64 fatias de 8b, 16b, 24b, 32b, ou 48b pixels de dados.
O DSP aborda todos os desafios para implementar CNNs em sistemas embarcados como discutido na seção anterior.
- Disponibilidade de alto desempenho computacional: Além do suporte avançado para implementar o processamento de sinais de imagem, o DSP tem suporte de instrução para todas as etapas das CNNs. Para operações de convolução, ele tem um conjunto de instruções muito rico suportando operações multi/multiply-accumulate que suportam operações 8b x 8b, 8b x 16b e 16b x 16b para dados assinados/não assinados. Pode realizar até 64 8b x 16b e 8b x 8b multiplicar/multiplicar/acumular operações em um ciclo e 32 16b x 16b multiplicar/multiplicar/acumular operações em um ciclo. Para o agrupamento máximo e funcionalidade ReLU, o DSP tem instruções para fazer 64 comparações de 8 bits em um ciclo. Para implementar funções não lineares com faixas finitas como tanh e signum, o DSP tem instruções para implementar uma tabela de look-up para 64 valores de 7 bits em um ciclo. Na maioria dos casos, as instruções para comparação e a tabela look-up são programadas em paralelo com instruções de multiplicar/multiplicar-acumular e não levam nenhum ciclo extra.
- Largura de banda maior: O DSP pode realizar até duas operações de carga/armazém de 512 bits por ciclo.
- Baixa necessidade de potência dinâmica: O DSP é uma máquina de ponto fixo. Devido ao manuseio flexível de uma variedade de tipos de dados, o desempenho total e a vantagem energética do cálculo misto de 16b e 8b pode ser alcançado com perda mínima de precisão.
- Flexibilidade: Uma vez que o DSP é um processador programável, o sistema pode ser atualizado para uma nova versão apenas executando uma atualização de firmware.
- Floating Point: Para algoritmos que requerem uma faixa dinâmica estendida para seus dados e/ou coeficientes, o DSP tem uma unidade opcional de ponto flutuante vetorial.
O DSP Vision P5 é entregue com um conjunto completo de ferramentas de software que inclui um compilador C/C++ de alto desempenho com vetorização e agendamento automático para suportar a arquitetura SIMD e VLIW sem a necessidade de escrever a linguagem de montagem. Este abrangente conjunto de ferramentas também inclui o linker, assembler, debugger, profiler e ferramentas de visualização gráfica. Um abrangente simulador de conjunto de instruções (ISS) permite que o designer simule e avalie rapidamente o desempenho. Ao trabalhar com sistemas grandes ou vetores de teste longos, a opção rápida e funcional do simulador TurboXim atinge velocidades que são 40X a 80X mais rápidas do que o ISS para desenvolvimento eficiente de software e verificação funcional.
Cadence implementou uma arquitetura de camada única CNN no DSP para reconhecimento de sinais de tráfego alemão. A cadência alcançou um CDR de 99,403% com quantização de 16 bits para amostras de dados e quantização de 8 bits para coeficientes em todas as camadas para esta arquitetura. Possui duas camadas de convolução, três camadas totalmente conectadas, quatro camadas ReLU, três camadas máximas de pooling e uma camada tanh não-linear. A cadência atingiu um desempenho de 38,58 MACs/ ciclo em média para toda a rede, incluindo os ciclos para todas as camadas Max Pooling, Tanh, e ReLU. A cadência atingiu um desempenho de 58,43 MACs por ciclo para a terceira camada, incluindo os ciclos para as funcionalidades Tanh e ReLU. Este DSP rodando a 600MHz pode processar mais de 850 sinais de tráfego em um segundo.
O Futuro das CNNs
As áreas promissoras da pesquisa de redes neurais são as redes neurais recorrentes (RNNs) usando memória de curto prazo (LSTM). Essas áreas estão fornecendo o estado atual da arte em tarefas de reconhecimento de séries temporais como reconhecimento de fala e reconhecimento de caligrafia. Os RNN/autoencoders também são capazes de gerar caligrafia / fala / imagens com alguma distribuição conhecida ,,,,.
Deep belief networks, outro tipo promissor de rede que utiliza máquinas Boltzman restritas (RMBs)/codificadoresautoen-, são capazes de ser treinados gananciosamente, uma camada de cada vez, e portanto são mais facilmente treináveis para redes muito profundas ,.
Conclusão
CNNs dão o melhor desempenho em problemas de reconhecimento de padrões/imagens e até superam o desempenho humano em certos casos. A cadência tem alcançado os melhores resultados na indústria usando algoritmos e arquiteturas proprietárias com CNNs. Desenvolvemos CNNs hierárquicas para reconhecimento de sinais de tráfego no GTSRB, alcançando o melhor desempenho de sempre neste conjunto de dados. Desenvolvemos outro algoritmo para a troca desempenho versus complexidade e conseguimos alcançar uma redução de complexidade de 86 para uma degradação do CDR de menos de 2%. O Tensilica Vision P5 DSP para imagem e visão computadorizada da Cadence tem todas as características necessárias para implementar CNNs, além das características necessárias para fazer o processamento do sinal de imagem. Mais de 850 reconhecimentos de sinais de tráfego podem ser realizados executando o DSP a 600MHz. O Tensilica Vision P5 DSP da Cadence tem um conjunto quase ideal de recursos para executar CNNs.
“Rede neural artificial”. Wikipédia. https://en.wikipedia.org/wiki/Artificial_neural_network
Karpathy, Andrej. 2015. “Redes Neuronais Parte 1: Configurando a Arquitetura.” Notas para CS231n Convolutional Neural Networks for Visual Recognition (Redes Neurais Convolucionais para Reconhecimento Visual), Stanford University. http://cs231n.github.io/neural-networks-1/
“Rede Neural Convolucional”. Wikipedia. https://en.wikipedia.org/wiki/Convolutional_neural_network
Sermanet, Pierre, e Yann LeCun. 2011. “Reconhecimento de sinais de trânsito com redes multiescala.” Courant Institute of Mathematical Sciences, New York University. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6033589
Ciresan, Dan, Ueli Meier, e Jürgen Schmidhuber. 2012. “Redes neurais multicolunas profundas para classificação de imagens.” 2012 IEEE Conference on Computer Vision and Pattern Recognition (New York, NY: Institute of Electrical and Electronics Engineers (IEEE)). http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6248110
Ciresan, Dan, Ueli Meier, Jonathan Masci, Luca M. Gambardella, e Jurgen Schmidhuber. 2011. “Redes Neurais Convolucionais Flexíveis e de Alto Desempenho para Classificação de Imagens”. Anais da Vigésima Segunda Conferência Internacional Conjunta sobre Inteligência Artificial-Volume Dois: 1237-1242. Recuperado em 17 de Novembro de 2013. http://people.idsia.ch/~juergen/ijcai2011.pdf
Lawrence, Steve, C. Lee Giles, Ah Chung Tsoi, e Andrew D. Back. 1997. “Face Recognition”: A Convolutional Neural Network Approach.” IEEE Transactions on Neural Networks, Volume 8; Issue 1. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=554195
Russakovsky, O. et al. 2014. “Desafio de Reconhecimento Visual em Grande Escala da ImageNet”. International Journal of Computer Vision. http://link.springer.com/article/10.1007/s11263-015-0816-y#
Ovtcharov, Kalin, Olatunji Ruwarse, Joo-Young Kim et al. 22 de Fevereiro de 2015. “Acelerando Redes Convolucionais Profundas Usando Hardware Especializado”. Pesquisa Microsoft. http://research-srv.microsoft.com/pubs/240715/CNN%20Whitepaper.pdf
Stallkamp, J., M. Schlipsing, J. Salmen, e C. Igel. “Man Vs. Computador”: Algoritmos de Aprendizagem de Máquinas de Benchmarking para Aplicação de Sinais de Trânsito.” IJCNN 2011. http://www.sciencedirect.com/science/article/pii/S0893608012000457
Hochreiter, Sepp, e Jürgen Schmidhuber. 1997. “Memória de Longa Duração a Curto Prazo.” Computação Neural, 9(8):1735-1780. ftp://ftp.idsia.ch/pub/juergen/lstm.pdf
Graves, Alex. 2014. “Gerando Sequências com Redes Neurais Recorrentes.” http://arxiv.org/abs/1308.0850
Schmidhuber, Jurgen. 2015. “Redes Neurais Recorrentes.” http://people.idsia.ch/~juergen/rnn.html
Olshausen, Bruno A., e David J. Field. 1996. “Emergência de propriedades de campo receptivas a células simples através da aprendizagem de um código esparso para imagens naturais.” Natureza 381.6583: 607-609. http://www.nature.com/nature/journal/v381/n6583/abs/381607a0.html
Hinton, G. E. e Salakhutdinov, R. R. 2006. “Reduzindo a dimensionalidade dos dados com redes neurais”. Science vol. 313 no. 5786 pp. 504-507. http://www.sciencemag.org/content/suppl/2006/08/04/313.5786.504.DC1.
Hinton, Geoffrey E. 2009. “Redes de crenças profundas”. Scholarpedia, 4(5):5947.
http://www.scholarpedia.org/article/Deep_belief_networks