Reddit AmItheAsshole é mais agradável para as mulheres do que para os homens – uma prova de SQL?
Quando os vermelhos perguntam “eu sou o imbecil” enquanto falam sobre as mulheres, eles têm uma mudança maior de serem julgados como o imbecil. Vamos conferir essas métricas – com BigQuery, dbt, e Data Studio
Não tome nada que eu escrevi aqui como verdade absoluta. Várias pessoas no Twitter notaram problemas e adicionaram correções à análise que eu ofereci. Ler este post como originalmente apresentado – e as reações – pode ser uma ótima maneira de você aprender tanto quanto eu aprendi enquanto lia as respostas. Você pode encontrar muitos de seus pensamentos não filtrados seguindo este tópico do Twitter.
Context
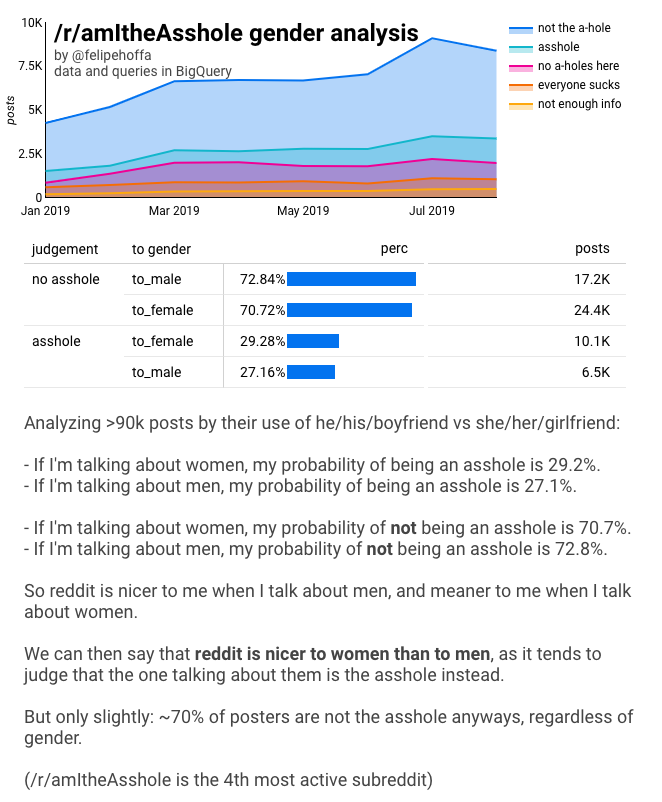
/r/amItheAsshole cresceu para ser o 4º subreddit mais ativo – pelo número de comentários. As pessoas vêm a este subredito para contar suas histórias, e perguntam a outros redactores “Eu sou o idiota aqui?”. Acontece que a maioria das pessoas são julgadas como “não o imbecil”, como se vê neste gráfico:
O meu tweet com estes resultados recebeu muita atenção:
Incluindo a pergunta – o vermelho é mais agradável para as mulheres ou para os homens?
Gênero de decisão
Ao olhar o título ou o conteúdo de um post, você pode ter dificuldade em decidir se “eu” é homem ou mulher – mas é muito fácil contar o número de “ela/ele/ele/ela/ela namorada/o namorado” presente na história.
Vejamos alguns posts aleatórios, e a contagem de cada um desses pronomes e palavras de gênero:

Vemos que a contagem dos pronomes e palavras do gênero no exemplo corresponde a quem a história se refere. Estas histórias são sobre um cliente masculino, uma namorada feminina, um vizinho masculino, um filho masculino e uma filha adolescente feminina.
Com estes números, podemos agora estabelecer uma regra arbitrária: Se houver mais do dobro do número de pronomes masculinos do que femininos, esse post é sobre um homem. Podemos usar a regra oposta para dizer que o post é sobre uma mulher. Se os números forem muito próximos ou nulos, chamaremos o post de “neutro”.
Outra regra que podemos definir para simplificar a análise:
- Se o julgamento não for ‘a-hole’ ou ‘no a-holes aqui’ então podemos dizer ‘o poster não é um idiota’.
- Se o julgamento for ‘idiota’ ou ‘todo mundo chupa’ então podemos dizer ‘o cartaz é um idiota’.
Se agregarmos todos estes posts, chegamos aos números:

Quando eu apresentei estes resultados pela primeira vez, me disseram “estes números estão muito próximos, podem ser um erro estatístico”.
Significado estatístico?
Como podemos dizer que os números não são meros erros estatísticos? Vamos ver a tendência mês a mês – é estável?

Sim! A tendência varia mês a mês, mas há uma clara maior chance de ser um imbecil quando se fala de mulheres do que quando se fala de homens. Se a pequena diferença fosse apenas uma casualidade estatística, esperaríamos que a tendência saltasse selvagemente.
E por favor note que estes resultados são muito específicos, já que este tweet notes:
Ao qual eu respondi
How-to
Desta vez estou usando dbt pela primeira vez, e deixei todo o meu código no GitHub. Obrigado Claire Carroll pela sua ajuda para começar com esta incrível ferramenta!
Para extrair todos os posts /r/AmItheAsshole em BigQuery para uma nova tabela, você pode fazer:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Então o gênero e julgamento de cada post pode ser determinado com uma consulta como:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
E finalmente as estatísticas apresentadas aqui:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Discussão
Encontrará muitas respostas interessantes e divertidas no twitter para este post:
Sinta-se livre para participar da discussão (e diga-me se eu estiver errado?). Lembre-se de ser gentil uns com os outros – a maioria das pessoas não é o idiota de qualquer forma.
Quer mais?
Só cobri até agosto de 2019, pois é quando o arquivo vermelho completo atual em BigQuery pára – até futuras atualizações esperadas. Verifique meu post anterior para mais detalhes sobre a coleta de dados ao vivo do pushshift.io. Obrigado Jason Baumgartner pelo fornecimento constante!
Eu sou Felipe Hoffa, um desenvolvedor defensor do Google Cloud. Siga-me em @felipehoffa, encontre meus posts anteriores em medium.com/@hoffa, e tudo sobre BigQuery em reddit.com/r/bigquery.