Real Time vs Batch Processing vs Stream Processing
Com a constante taxa de inovação, os desenvolvedores podem esperar analisar terabytes e até petabytes de dados em qualquer período de tempo. (Dados, afinal, atraem mais dados.)
Isso permite inúmeras vantagens, é claro. Mas o que fazer com todos esses dados? Pode ser difícil conhecer a melhor maneira de acelerar e acelerar essas tecnologias, especialmente quando as reações devem ocorrer rapidamente.
Para as empresas digital-first, uma questão crescente se tornou a melhor maneira de usar o processamento em tempo real, o processamento em lote e o processamento em fluxo. Este post irá explicar as diferenças básicas entre estes tipos de processamento de dados.
Sistemas Operacionais em Tempo Real
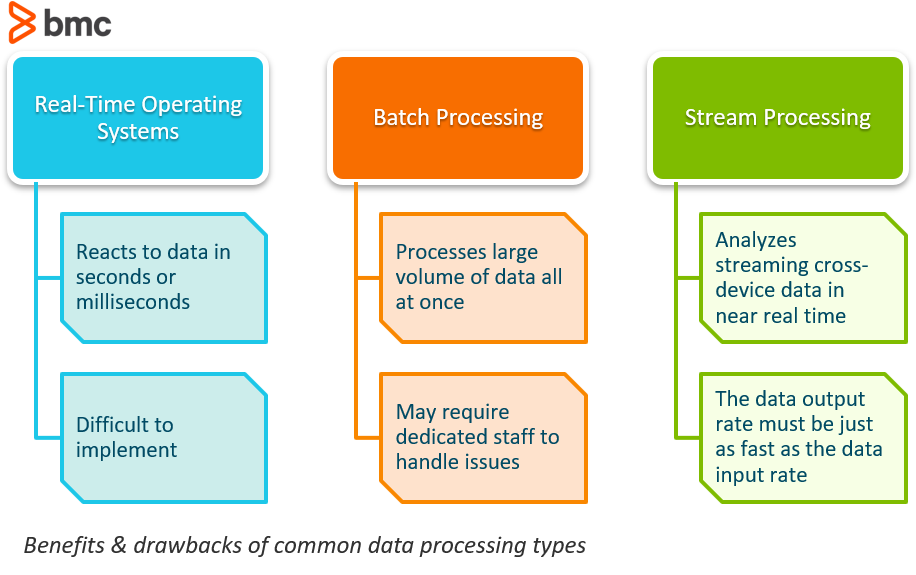
Sistemas Operacionais em Tempo Real normalmente se referem às reações aos dados. Um sistema pode ser categorizado como tempo real se ele puder garantir que a reação estará dentro de um prazo apertado no mundo real, geralmente em questão de segundos ou milissegundos.
Um dos melhores exemplos de um sistema em tempo real são aqueles usados no mercado de ações. Se uma cotação em ações deve vir da rede dentro de 10 milissegundos após ser colocada, isto seria considerado um processo em tempo real. Se isto foi conseguido usando uma arquitetura de software que utilizasse processamento de fluxo ou apenas processamento em hardware é irrelevante; a garantia do prazo apertado é o que o torna em tempo real.
Outras situações em que o uso de sistemas em tempo real seria benéfico são:
- ATMs
- Controle de tráfego aéreo
- Sistemas de freios com bloqueio no carro
Desafios
Embora este tipo de sistema soe como um alterador de jogo, a realidade é que os sistemas em tempo real são extremamente difíceis de implementar através do uso de sistemas de software comuns. Como esses sistemas assumem o controle sobre a execução do programa, isso traz um nível de abstração totalmente novo.
O que isso significa é que a distinção entre o fluxo de controle do seu programa e o código fonte não é mais aparente porque o sistema em tempo real escolhe qual tarefa executar naquele momento. Isto é benéfico, pois permite maior produtividade usando maior abstração e pode facilitar o projeto de sistemas complexos, mas significa menos controle em geral, o que pode ser difícil de depurar e validar.
Um outro desafio comum com sistemas operacionais em tempo real é que as tarefas não são entidades isoladas. O sistema decide quais tarefas devem ser agendadas e envia as de maior prioridade antes das de menor prioridade, atrasando assim sua execução até que todas as tarefas de maior prioridade sejam concluídas.
Mais e mais, alguns sistemas de software estão começando a ter um sabor de processamento em tempo real onde o prazo não é tão absoluto quanto uma probabilidade. Conhecidos como sistemas soft real-time, eles são capazes de normalmente ou geralmente cumprir seu prazo, embora o desempenho começará a se degradar se muitos prazos forem perdidos.
Processamento em lote
Processamento em lote é o processamento de um grande volume de dados de uma só vez. Os dados consistem facilmente de milhões de registros por dia e podem ser armazenados de várias maneiras (arquivo, registro, etc). Os trabalhos são normalmente completados simultaneamente em ordem sequencial, sem parar.
Um exemplo de um trabalho de processamento em lote são todas as transações que uma empresa financeira pode apresentar ao longo de uma semana. Batching também pode ser usado em:
- Processos de pagamento
- Faturas de itens de linha
- Cadeia de suprimentos e cumprimento
O processamento de dados em lote é uma forma extremamente eficiente de processar grandes quantidades de dados que são coletados ao longo de um período de tempo. Ele também ajuda a reduzir os custos operacionais que as empresas podem gastar em mão-de-obra, uma vez que não requer funcionários especializados em entrada de dados para suportar o seu funcionamento. Ele pode ser usado offline e dá aos gerentes controle completo sobre quando iniciar o processamento, seja durante a noite ou no final de uma semana ou período de pagamento.
Desafios
Como com qualquer coisa, há algumas desvantagens na utilização de software de processamento em lote. Um dos maiores problemas que as empresas vêem é que a depuração destes sistemas pode ser complicada. Se você não tiver uma equipe de TI dedicada ou profissional, tentar corrigir o sistema quando um erro ocorre pode ser prejudicial, causando a necessidade de um consultor externo para ajudar.
Outro problema com o processamento em lote é que as empresas geralmente o implementam para economizar dinheiro, mas o software e o treinamento requerem uma quantidade decente de despesas no início. Os gestores terão de ser treinados para compreender:
- Como agendar um lote
- O que os desencadeia
- O que significam certas notificações
(Saiba mais sobre o processamento em lote moderno.)
Processamento em fluxo
Processamento em fluxo é o processo de ser capaz de analisar quase instantaneamente os dados que estão em fluxo de um dispositivo para outro.
Este método de computação contínua acontece à medida que os dados fluem através do sistema sem limitações de tempo obrigatórias na saída. Com o fluxo quase instantâneo, os sistemas não requerem grandes quantidades de dados para serem armazenados.
O processamento em fluxo é altamente benéfico se os eventos que você deseja rastrear estiverem acontecendo freqüentemente e se fecharem juntos no tempo. Também é melhor utilizar se o evento precisar ser detectado imediatamente e responder rapidamente. O processamento em fluxo, então, é útil para tarefas como detecção de fraude e ciber-segurança. Se os dados de transações são processados em fluxo, transações fraudulentas podem ser identificadas e interrompidas antes mesmo de serem concluídas.
Desafios
Um dos maiores desafios que as organizações enfrentam com o processamento em fluxo é que a taxa de saída de dados a longo prazo do sistema deve ser tão rápida, ou mais rápida, do que a taxa de entrada de dados a longo prazo, caso contrário o sistema começará a ter problemas com armazenamento e memória.
Outro desafio é tentar descobrir a melhor maneira de lidar com a enorme quantidade de dados que estão sendo gerados e movidos. Para manter o fluxo de dados através do sistema operando no nível ideal mais alto, é necessário que as organizações criem um plano de como reduzir o número de cópias, como segmentar os kernels de computação e como utilizar a hierarquia de cache da melhor maneira possível.
Conclusão
Embora todos esses sistemas tenham vantagens, no final do dia as organizações devem considerar os benefícios potenciais de cada um para decidir qual método é mais adequado para o caso de uso.
Recursos adicionais
- BMC Workload Automation Blog
- BMC Big Data Blog
- Guia do iniciante para a automação do local de trabalho
- O que é um trabalho em lote?
- O que é um pipeline de dados?
>
Gerir sl como para os seus serviços batch joe goldberg da BMC Software
Tomar uma abordagem moderna ao processamento batch

Estes lançamentos são meus e não representam necessariamente a posição, estratégias ou opinião da BMC.
Veja um erro ou tenha uma sugestão? Por favor nos informe enviando um e-mail para [email protected].