Big Data and Hadoop Ecosystem Tutorial
Bem-vindos à primeira lição ‘Big Data and Hadoop Ecosystem’ do tutorial ‘Big Data Hadoop’ que faz parte do ‘Big Data Hadoop and Spark Developer Certification course’ oferecido pelo Simplilearn. Esta lição é uma introdução ao Big Data e ao ecossistema do Hadoop. Na próxima seção, vamos discutir os objetivos desta lição.
Objetivos
Após completar esta lição, você será capaz de:
-
Entender o conceito de Grandes Dados e seus desafios
-
Explicar o que são Grandes Dados
>
-
Explicar o que é o Hadoop e como ele aborda os desafios dos Grandes Dados
-
Descreva o ecossistema Hadoop
Deixe-nos agora uma visão geral dos Grandes Dados e do Hadoop.
Visão geral dos Grandes Dados e Hadoop
Antes do ano 2000, os dados eram relativamente pequenos do que são atualmente; entretanto, o cálculo dos dados era complexo. Todo o cálculo de dados dependia do poder de processamento dos computadores disponíveis.
A medida que os dados cresciam, a solução era ter computadores com memória grande e processadores rápidos. No entanto, depois de 2000, os dados continuaram a crescer e a solução inicial não podia mais ajudar.
Nos últimos anos, houve uma explosão incrível no volume de dados. A IBM relatou que 2,5 exabytes, ou 2,5 bilhões de gigabytes de dados, foram gerados todos os dias em 2012.
Aqui estão algumas estatísticas indicando a proliferação de dados da Forbes, setembro de 2015. 40.000 consultas de pesquisa são realizadas no Google a cada segundo. Até 300 horas de vídeo são carregadas no YouTube a cada minuto.
No Facebook, 31,25 milhões de mensagens são enviadas pelos usuários e 2,77 milhões de vídeos são vistos a cada minuto. Até 2017, quase 80% das fotos serão tiradas em smartphones.
Até 2020, pelo menos um terço de todos os dados passará pela Nuvem (uma rede de servidores conectados através da Internet). Até 2020, cerca de 1,7 megabytes de novas informações serão criadas a cada segundo para cada ser humano no planeta.
Os dados estão crescendo mais rápido do que nunca. Você pode usar mais computadores para gerenciar esses dados sempre crescentes. Em vez de uma máquina a executar o trabalho, você pode usar várias máquinas. Isto é chamado um sistema distribuído.
Você pode verificar o Big Data Hadoop e o Spark Developer Certification Course Preview aqui!
Deixe-nos ver um exemplo para entender como funciona um sistema distribuído.
Como funciona um sistema distribuído?
Suponha que você tenha uma máquina que tenha quatro canais de entrada/saída. A velocidade de cada canal é 100 MB/seg e você quer processar um terabyte de dados nele.
Levará 45 minutos para que uma máquina processe um terabyte de dados. Agora, vamos assumir que um terabyte de dados é processado por 100 máquinas com a mesma configuração.
Levará apenas 45 segundos para que 100 máquinas processem um terabyte de dados. Sistemas distribuídos levam menos tempo para processar Grandes Dados.
Agora, vamos olhar para os desafios de um sistema distribuído.
Desafios dos Sistemas Distribuídos
Desde que múltiplos computadores são usados em um sistema distribuído, há grandes chances de falha do sistema. Há também um limite na largura de banda.
A complexidade da programação também é alta porque é difícil sincronizar dados e processos. Hadoop pode enfrentar estes desafios.
Deixe-nos entender o que Hadoop é na próxima seção.
O que é Hadoop?
Hadoop é uma estrutura que permite o processamento distribuído de grandes conjuntos de dados entre clusters de computadores usando modelos simples de programação. É inspirado em um documento técnico publicado pelo Google.
A palavra Hadoop não tem nenhum significado. Doug Cutting, que descobriu o Hadoop, deu-lhe o nome do seu filho elefante de cor amarela.
Vamos discutir como o Hadoop resolve os três desafios do sistema distribuído, tais como as grandes chances de falha do sistema, o limite de largura de banda, e a complexidade da programação.
As quatro características chave do Hadoop são:
-
Econômico: Seus sistemas são altamente econômicos, pois computadores comuns podem ser usados para processamento de dados.
-
Relável: É confiável porque armazena cópias dos dados em diferentes máquinas e é resistente a falhas de hardware.
-
Scalável: É facilmente escalável, tanto na horizontal como na vertical. Alguns nós extra ajudam a aumentar a escala da estrutura.
-
Flexível: É flexível e você pode armazenar tantos dados estruturados e não estruturados quanto precisar e decidir usá-los mais tarde.
Tradicionalmente, os dados eram armazenados em um local central, e eram enviados para o processador em tempo de execução. Este método funcionou bem para dados limitados.
No entanto, os sistemas modernos recebem terabytes de dados por dia, e é difícil para os computadores tradicionais ou Sistema de Gerenciamento de Banco de Dados Relacionais (RDBMS) empurrar grandes volumes de dados para o processador.
Hadoop trouxe uma abordagem radical. No Hadoop, o programa vai para os dados, e não o contrário. Inicialmente ele distribui os dados para múltiplos sistemas e depois executa o cálculo onde quer que os dados estejam localizados.
Na seção seguinte, vamos falar sobre como o Hadoop difere do Sistema de Banco de Dados Tradicional.
Diferença entre Sistema de Banco de Dados Tradicional e Hadoop
A tabela abaixo ajudará a distinguir entre Sistema de Banco de Dados Tradicional e Hadoop.
|
Sistema de Base de Dados Tradicional |
Hadoop |
|
Os dados são armazenados em um local central e enviados ao processador em tempo de execução. |
No Hadoop, o programa vai para os dados. Inicialmente ele distribui os dados para múltiplos sistemas e depois executa o cálculo onde quer que os dados estejam localizados. |
|
Sistemas de Banco de Dados Tradicionais não podem ser usados para processar e armazenar uma quantidade significativa de dados (dados grandes). |
Hadoop funciona melhor quando o tamanho dos dados é grande. Ele pode processar e armazenar uma grande quantidade de dados de forma eficiente e eficaz. |
|
Tradicional RDBMS é usado para gerenciar apenas dados estruturados e semi-estruturados. Ele não pode ser usado para controlar dados não estruturados. |
Hadoop pode processar e armazenar uma variedade de dados, sejam eles estruturados ou não estruturados. > |
Deixe-nos discutir a diferença entre RDBMS tradicional e Hadoop com a ajuda de uma analogia.
Você teria notado a diferença no estilo de alimentação de um ser humano e de um tigre. Um humano come comida com a ajuda de uma colher, onde a comida é levada à boca. Enquanto, um tigre traz a boca para a comida.
Agora, se a comida é dados e a boca é um programa, o estilo de comer de um humano retrata o RDBMS tradicional e o do tigre retrata o Hadoop.
Deixe-nos ver o Ecossistema Hadoop na próxima secção.
Ecosistema Hadoop
Ecosistema Hadoop O Hadoop tem um ecossistema que evoluiu a partir dos seus três componentes principais processamento, gestão de recursos e armazenamento. Neste tópico, você aprenderá os componentes do ecossistema do Hadoop e como eles desempenham suas funções durante o processamento de Grandes Dados. O ecossistema Hadoop está crescendo continuamente para atender as necessidades dos Grandes Dados. Ele compreende os doze componentes a seguir:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop MapReduce
-
Porco
-
Impala
-
Colme
-
Pesquisa de Cloudera
-
Oozie
>
-
Hue.
Vocês aprenderão sobre o papel de cada componente do ecossistema Hadoop nas próximas seções.
>
Deixe-nos entender o papel de cada componente do ecossistema Hadoop.
Componentes do Ecossistema Hadoop
Deixe-nos começar com o primeiro componente HDFS do Ecossistema Hadoop.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS é uma camada de armazenamento para o Hadoop.
-
HDFS é adequado para armazenamento distribuído e processamento, ou seja, enquanto os dados estão sendo armazenados, eles são primeiro distribuídos e depois processados.
-
HDFS fornece acesso em streaming aos dados do sistema de arquivos.
-
HDFS fornece permissão e autenticação de arquivos.
-
HDFS usa uma interface de linha de comando para interagir com o Hadoop.
> Então o que armazena os dados no HDFS? É o HBase que armazena dados no HDFS.
HBase
-
HBase é um banco de dados NoSQL ou banco de dados não-relacional.
-
HBase é importante e usado principalmente quando você precisa de acesso aleatório, em tempo real, leitura ou escrita aos seus Grandes Dados.
-
Fornece suporte a um alto volume de dados e alto rendimento.
-
Em um HBase, uma tabela pode ter milhares de colunas.
Discutimos como os dados são distribuídos e armazenados. Agora, vamos entender como esses dados são ingeridos ou transferidos para HDFS. Sqoop faz exatamente isto.
O que é Sqoop?
-
Sqoop é uma ferramenta projetada para transferir dados entre Hadoop e servidores de banco de dados relacionais.
-
É usado para importar dados de bases de dados relacionais (como Oracle e MySQL) para HDFS e exportar dados de HDFS para bases de dados relacionais.
Se você quiser ingerir dados de eventos como dados de streaming, dados de sensores ou arquivos de log, então você pode usar o Flume. Vamos ver o Flume na próxima seção.
Flume
-
Flume é um serviço distribuído que coleta dados de eventos e os transfere para HDFS.
-
É ideal para dados de eventos de múltiplos sistemas.
Após os dados serem transferidos para o HDFS, eles são processados. Uma das estruturas que processam dados é Spark.
O que é Spark?
-
Spark é uma estrutura de computação em cluster de código aberto.
-
Provê um desempenho até 100 vezes mais rápido para algumas aplicações com primitivas in-memory em comparação com o paradigma MapReduce de dois estágios baseado em disco do Hadoop.
-
Spark pode rodar no cluster Hadoop e processar dados no HDFS.
>
-
Também suporta uma grande variedade de carga de trabalho, que inclui Aprendizagem de máquina, Business intelligence, Streaming e processamento em lote.
Spark tem os seguintes componentes principais:
>
-
Spark Core e conjuntos de dados distribuídos resistentes ou RDD
-
Spark SQL
>
-
Spark streaming
>
-
Machine learning library ou Mlib
>
-
Graphx.
>
>
>
>
Spark é agora amplamente utilizado, e você aprenderá mais sobre ele nas lições subsequentes.
Hadoop MapReduce
-
Hadoop MapReduce é a outra estrutura que processa os dados.
-
É o motor original de processamento Hadoop, que é principalmente baseado em Java.
-
É baseado no mapa e reduz o modelo de programação.
-
Muitas ferramentas como Hive e Pig são construídas sobre um modelo de redução de mapa.
-
Tem uma tolerância a falhas extensa e madura incorporada na estrutura.
-
Ainda é muito comumente usado, mas perde terreno para Spark.
Após os dados serem processados, eles são analisados. Pode ser feito por um sistema de código aberto de fluxo de dados de alto nível chamado Pig. Ele é usado principalmente para análise.
Deixe-nos agora entender como Pig é usado para análise.
Pig
-
Pig converte seus scripts para o código MapReduce e Reduce, salvando assim o usuário de escrever programas complexos MapReduce.
-
Perguntas ad-hoc como Filtro e Join, que são difíceis de realizar no MapReduce, podem ser facilmente feitas usando Pig.
-
Pode também usar o Impala para analisar os dados.
-
É um motor SQL de código aberto de alto desempenho, que roda no cluster Hadoop.
-
É ideal para análise interativa e tem latência muito baixa, que pode ser medida em milissegundos.
Impala
-
Impala suporta um dialecto de SQL, por isso os dados em HDFS são modelados como uma tabela de base de dados.
-
Também pode efectuar análise de dados usando HIVE. É uma camada de abstração no topo do Hadoop.
-
É muito semelhante ao Impala. Entretanto, é preferível para processamento de dados e Carga de Transformação de Extrato, também conhecido como ETL, operações.
-
Impala é preferível para consultas ad-hoc.
HIVE
-
HIVE executa consultas usando o MapReduce; contudo, um usuário não precisa escrever nenhum código no MapReduce de baixo nível.
-
Hive é adequado para dados estruturados. Após os dados serem analisados, está pronto para os usuários acessarem.
Agora sabemos o que o HIVE faz, vamos discutir o que suporta a busca de dados. A pesquisa de dados é feita usando Cloudera Search.
Cloudera Search
-
Search é um dos produtos de acesso quase em tempo real da Cloudera. Ele permite que usuários não técnicos pesquisem e explorem dados armazenados ou ingeridos no Hadoop e HBase.
-
Os usuários não precisam de SQL ou habilidades de programação para usar a Cloudera Search porque ela fornece uma interface simples, de texto completo para a pesquisa.
-
Outro benefício da Cloudera Search em comparação com as soluções de busca autônoma é a plataforma de processamento de dados totalmente integrada.
-
Cloudera Search utiliza o sistema de armazenamento flexível, escalável e robusto incluído com CDH ou Cloudera Distribution, incluindo Hadoop. Isto elimina a necessidade de mover grandes conjuntos de dados através de infra-estruturas para tratar de tarefas empresariais.
-
Hadoop trabalhos como MapReduce, Pig, Hive, e Sqoop têm fluxos de trabalho.
Oozie
-
Oozie é um fluxo de trabalho ou sistema de coordenação que você pode usar para gerenciar os trabalhos do Hadoop.
O ciclo de vida da aplicação Oozie é mostrado no diagrama abaixo.
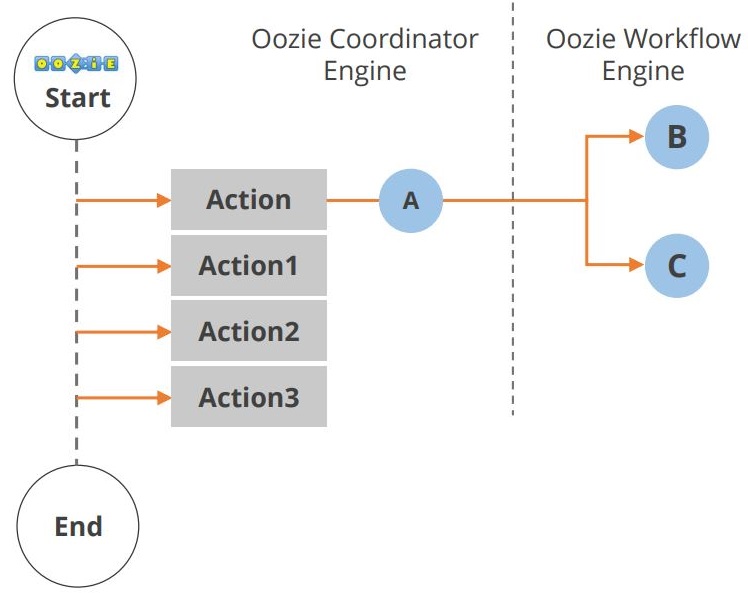 Como você pode ver, múltiplas ações ocorrem entre o início e o fim do fluxo de trabalho. Outro componente no ecossistema do Hadoop é o Hue. Vejamos agora a Matriz.
Como você pode ver, múltiplas ações ocorrem entre o início e o fim do fluxo de trabalho. Outro componente no ecossistema do Hadoop é o Hue. Vejamos agora a Matriz.
>
Matriz
Matriz é um acrônimo para Experiência do Usuário Hadoop. É uma interface web open-source para o Hadoop. Você pode realizar as seguintes operações usando Hue:
>
-
Carregar e pesquisar dados
-
Perguntar uma tabela em HIVE e Impala
-
Executar trabalhos e fluxos de trabalho de Centelha e Porco Pesquisar dados
>
-
Tudo-em-tudo, Hue torna o Hadoop mais fácil de usar.
>
-
Provê também editor SQL para HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL e Solr SQL.
>
>
>
Após esta breve visão geral dos doze componentes do ecossistema Hadoop, discutiremos agora como estes componentes trabalham juntos para processar Big Data.
Estágio de processamento de Big Data
Existem quatro estágios de processamento de Big Data: Ingest, Processing, Analyze, Access. Vamos vê-los em detalhes.
Ingest
A primeira etapa do processamento de Dados Grandes é o Ingest. Os dados são ingeridos ou transferidos para o Hadoop a partir de várias fontes, como bases de dados relacionais, sistemas ou arquivos locais. O Sqoop transfere dados de RDBMS para HDFS, enquanto o Flume transfere dados de eventos.
Processamento
O segundo estágio é o Processamento. Nesta etapa, os dados são armazenados e processados. Os dados são armazenados no sistema de arquivo distribuído, HDFS, e no NoSQL distribuído, HBase. Spark e MapReduce realizam o processamento dos dados.
Analisar
O terceiro estágio é Analyze. Aqui, os dados são analisados por frameworks de processamento como Pig, Hive, e Impala.
Pig converte os dados usando um mapa e os reduz e depois os analisa. A colmeia também se baseia no mapa e reduz a programação e é mais adequada para dados estruturados.
Acesso
A quarta etapa é o Access, que é realizado por ferramentas como Hue e Cloudera Search. Nesta etapa, os dados analisados podem ser acessados pelos usuários.
Hue é a interface web, enquanto Cloudera Search fornece uma interface de texto para explorar dados.
Check out the Big Data Hadoop and Spark Developer Certification Course Here!
Resumo
Deixe-nos agora resumir o que aprendemos nesta lição.
>
-
Hadoop é um framework para armazenamento e processamento distribuído.
-
Os componentes principais do Hadoop incluem HDFS para armazenamento, YARN para gerenciamento de recursos de cluster e MapReduce ou Spark para processamento.
-
O ecossistema Hadoop inclui múltiplos componentes que suportam cada etapa do processamento de Grandes Dados.
-
Flume and Sqoop ingest data, HDFS and HBase store data, Spark and MapReduce process data, Pig, Hive, and Impala analysis data, Hue and Cloudera Search help to explore data.
-
Oozie gerencia o fluxo de trabalho dos trabalhos Hadoop.
Conclusão
Concluímos assim a lição sobre Grandes Dados e o Ecossistema Hadoop. Na próxima lição, vamos discutir HDFS e YARN.
Conheça nossas aulas de treinamento em Big Data Hadoop e Spark Developer Online Classroom nas principais cidades:
| Nome | Data | Lugar | |
|---|---|---|---|
| Dados Grandes Hadoop e Spark Developer | 3 Abr -15 Maio 2021, Lote de fim de semana | Sua Cidade | Ver Detalhes |
| Big Data Hadoop and Spark Developer | 12 Abr -4 Maio 2021, Lote de dias da semana | Sua Cidade | Ver Detalhes |
| Big Data Hadoop and Spark Developer | 24 Abr -5 Jun 2021, Lote de fim-de-semana | Sua Cidade | Ver Detalhes |
{{lectureCoursePreviewTitle}}} Ver Transcript Watch Video
Para aprender mais, faça o Curso
Big Data Hadoop and Spark Developer Certification Training
Ir para o Curso
Para aprender mais, Faça o Curso
Big Data Hadoop and Spark Developer Certification Training Vá ao Curso