NGINX i HAProxy: Testing User Experience in the Cloud
Wiele benchmarków wydajności mierzy szczytową przepustowość lub liczbę żądań na sekundę (RPS), ale te wskaźniki mogą zbytnio upraszczać historię wydajności w rzeczywistych lokalizacjach. Niewiele organizacji uruchamia swoje usługi z lub blisko szczytowej przepustowości, gdzie zmiana wydajności o 10% w jedną lub drugą stronę może stanowić znaczącą różnicę. Przepustowość lub RPS wymagane przez witrynę nie są nieskończone, ale są ustalane przez czynniki zewnętrzne, takie jak liczba jednoczesnych użytkowników, których muszą obsłużyć i poziom aktywności każdego użytkownika. Ostatecznie, najważniejsze jest to, że Twoi użytkownicy otrzymują najlepszy poziom usług. Użytkownicy końcowi nie dbają o to, ile osób odwiedza Twoją stronę. Zależy im tylko na usłudze, którą otrzymują i nie usprawiedliwiają słabej wydajności, ponieważ system jest przeciążony.
To prowadzi nas do spostrzeżenia, że najważniejsze jest to, że organizacja dostarcza spójną wydajność o niskich opóźnieniach dla wszystkich swoich użytkowników, nawet przy dużym obciążeniu. Porównując NGINX i HAProxy działające na Amazon Elastic Compute Cloud (EC2) jako odwrotne serwery proxy, postanowiliśmy zrobić dwie rzeczy:
- Określić, jaki poziom obciążenia każdy proxy wygodnie obsługuje
- Zebrać rozkład percentylowy latencji, który według nas jest metryką najbardziej bezpośrednio skorelowaną z doświadczeniem użytkownika
Protokoły testowe i zebrane metryki
Użyliśmy programu do generowania obciążenia wrk2, aby emulować klienta, wykonującego ciągłe żądania przez HTTPS w określonym czasie. Testowany system – HAProxy lub NGINX – działał jako odwrotne proxy, nawiązując szyfrowane połączenia z klientami symulowanymi przez wrk wątków, przekazując żądania do backendowego serwera WWW działającego pod kontrolą NGINX Plus R22 i zwracając odpowiedź wygenerowaną przez serwer WWW (plik) do klienta.
Każdy z trzech komponentów (klient, odwrotne proxy i serwer WWW) działał pod Ubuntu 20.04.1 LTS na c5n.2xlarge Amazon Machine Image (AMI) w EC2.
Jak wspomniano, zebraliśmy pełny rozkład percentyli latencji z każdego przebiegu testu. Latencja jest definiowana jako ilość czasu pomiędzy wygenerowaniem żądania przez klienta a otrzymaniem odpowiedzi. Rozkład percentylowy latencji sortuje pomiary latencji zebrane podczas okresu testowego od najwyższej (największej latencji) do najniższej.
Metodyka testowania
Klient
Używając wrk2 (wersja 4.0.0), uruchomiliśmy następujący skrypt na instancji Amazon EC2:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Aby zasymulować wielu klientów uzyskujących dostęp do aplikacji internetowej, zrodzono 4 wrk wątki, które razem nawiązały 100 połączeń z odwrotnym proxy. Podczas 30-sekundowego testu skrypt generował określoną liczbę RPS. Parametry te odpowiadają następującym wrk2 opcjom: Number of RPS issued by the client
‑‑latency option – Output includes corrected latency percentile informationWe incrementally increased the number of RPS over the set of test runs until one of the proxies hit 100% CPU utilization. Aby uzyskać więcej informacji na ten temat, zobacz Wyniki wydajności.
Wszystkie połączenia między klientem a serwerem proxy były realizowane za pośrednictwem protokołu HTTPS z TLSv1.3. Użyliśmy ECC z 256-bitowym rozmiarem klucza, Perfect Forward Secrecy, oraz zestawu szyfrów TLS_AES_256_GCM_SHA384. (Ponieważ TLSv1.2 jest nadal powszechnie używany w Internecie, przeprowadziliśmy ponownie testy również z nim; wyniki były tak podobne do tych dla TLSv1.3, że nie zamieszczamy ich tutaj.)
HAProxy: Configuration and Versioning
Zastosowaliśmy HAProxy w wersji 2.3 (stable) jako reverse proxy.
Liczba jednoczesnych użytkowników na popularnej stronie internetowej może być ogromna. Aby obsłużyć duży wolumen ruchu, twój odwrotny proxy musi być w stanie skalować, aby skorzystać z wielu rdzeni. Istnieją dwa podstawowe sposoby skalowania: wieloprocesowość i wielowątkowość. Zarówno NGINX jak i HAProxy wspierają wieloprocesowość, ale jest istotna różnica – w implementacji HAProxy procesy nie współdzielą pamięci (podczas gdy w NGINX tak). Niezdolność do dzielenia stanu pomiędzy procesami ma kilka konsekwencji dla HAProxy:
- Parametry konfiguracyjne – w tym limity, statystyki i stawki – muszą być zdefiniowane oddzielnie dla każdego procesu.
- Performance metrics są zbierane per-process; łączenie ich wymaga dodatkowego configu, który może być dość złożony.
- Każdy proces obsługuje kontrole zdrowia oddzielnie, więc serwery docelowe są sondowane na proces, a nie na serwer, jak oczekiwano.
- Przetrwanie sesji nie jest możliwe.
- Dynamiczna zmiana konfiguracji dokonana przez HAProxy Runtime API dotyczy pojedynczego procesu, więc musisz powtórzyć wywołanie API dla każdego procesu.
Z powodu tych problemów, HAProxy zdecydowanie odradza używanie swojej implementacji wieloprocesowej. Cytując bezpośrednio z podręcznika konfiguracji HAProxy:
UŻYWANIE WIELU PROCESÓW JEST TRUDNIEJSZE DO DEBUGOWANIA I JEST NAPRAWDĘ ZABRONIONE.
HAProxy wprowadziło wielowątkowość w wersji 1.8 jako alternatywę dla wieloprocesowości. Wielowątkowość w większości rozwiązuje problem dzielenia stanu, ale jak omawiamy w Wynikach wydajności, w trybie wielowątkowym HAProxy nie działa tak dobrze jak w trybie wieloprocesowym.
Nasza konfiguracja HAProxy zawierała provisioning zarówno dla trybu wielowątkowego (HAProxy MT) jak i wieloprocesowego (HAProxy MP). Aby przełączać się między trybami na każdym poziomie RPS podczas testów, komentowaliśmy i odkomentowywaliśmy odpowiedni zestaw linii i restartowaliśmy HAProxy, aby konfiguracja zaczęła działać:
$ sudo service haproxy restartOto konfiguracja z HAProxy MT: cztery wątki są tworzone w ramach jednego procesu i każdy wątek jest przypięty do procesora. Dla HAProxy MP (zakomentowane tutaj), są cztery procesy, każdy przypięty do procesora.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Konfiguracja i wersjonowanie
Wdrożyliśmy NGINX Open Source w wersji 1.18.0 jako odwrotne proxy.
Aby wykorzystać wszystkie rdzenie dostępne na maszynie (w tym przypadku cztery), dołączyliśmy parametr auto do dyrektywy worker_processes, która jest również ustawieniem w domyślnym pliku nginx.conf dystrybuowanym z naszego repozytorium. Dodatkowo, dyrektywa worker_cpu_affinity została dołączona, aby przypiąć każdy proces robotniczy do procesora (każdy 1 w drugim parametrze oznacza procesor w maszynie).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Wyniki
Jako front-end do twojej aplikacji, wydajność twojego reverse proxy jest krytyczna.
Testowaliśmy każdy reverse proxy (NGINX, HAProxy MP, i HAProxy MT) przy rosnącej liczbie RPS, aż jeden z nich osiągnął 100% wykorzystania procesora. Wszystkie trzy działały podobnie na poziomach RPS, gdzie CPU nie był wyczerpany.
Osiągnięcie 100% wykorzystania CPU nastąpiło najpierw dla HAProxy MT, przy 85,000 RPS, i w tym momencie wydajność pogorszyła się dramatycznie zarówno dla HAProxy MT jak i HAProxy MP. Tutaj prezentujemy rozkład percentylowy opóźnień dla każdego serwera proxy przy tym poziomie obciążenia. Wykres został wykreślony na podstawie danych wyjściowych skryptu wrk przy użyciu programu HdrHistogram dostępnego na GitHubie.
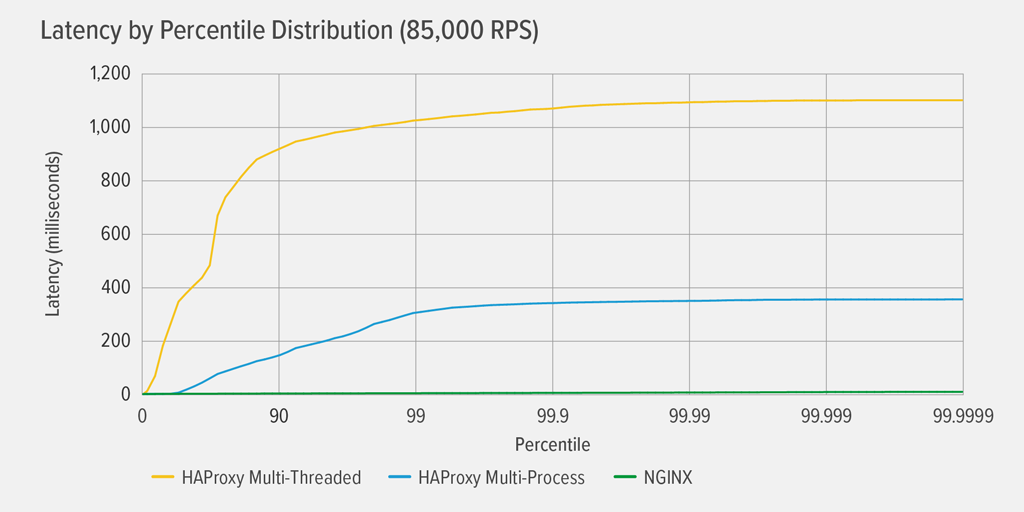
Przy 85 000 RPS opóźnienie w przypadku HAProxy MT gwałtownie wzrasta aż do 90. percentyla, a następnie stopniowo wyrównuje się do około 1100 milisekund (ms).
HAProxy MP radzi sobie lepiej niż HAProxy MT – opóźnienie rośnie wolniej aż do 99 percentyla, w którym to momencie zaczyna się wyrównywać w przybliżeniu 400ms. (Jako potwierdzenie, że HAProxy MP jest bardziej wydajny, zaobserwowaliśmy, że HAProxy MT używał nieco więcej CPU niż HAProxy MP na każdym poziomie RPS.)
NGINX praktycznie nie cierpi z powodu opóźnienia w żadnym percentylu. Najwyższe opóźnienie, jakiego może doświadczyć znacząca liczba użytkowników (na 99.9999 percentylu) to około 8ms.
Co te wyniki mówią nam o doświadczeniu użytkownika? Jak wspomniano we wstępie, metryką, która naprawdę ma znaczenie, jest czas odpowiedzi z perspektywy użytkownika końcowego, a nie czas obsługi testowanego systemu.
Jest to powszechne błędne przekonanie, że mediana opóźnienia w rozkładzie najlepiej reprezentuje doświadczenie użytkownika. W rzeczywistości mediana jest liczbą, od której około połowa czasów odpowiedzi jest gorsza! Użytkownicy zazwyczaj wydają wiele żądań i uzyskać dostęp do wielu zasobów na obciążenie strony, więc kilka z ich żądań są zobowiązane do doświadczenia opóźnień w górnych percentyli na wykresie (99th przez 99.9999th). Ponieważ użytkownicy nie tolerują słabej wydajności, opóźnienia na wysokich percentylach są tymi, które najprawdopodobniej zauważą.
Pomyśl o tym w ten sposób: Twoje doświadczenie z wymeldowywaniem się w sklepie spożywczym jest określane przez to, jak długo trwa opuszczenie sklepu od momentu wejścia do kolejki do kasy, a nie tylko to, ile czasu zajęło kasjerowi zaobrączkowanie Twoich przedmiotów. Jeśli, na przykład, klient przed Tobą kwestionuje cenę produktu i kasjer musi poprosić kogoś o jej weryfikację, Twój całkowity czas w kasie jest znacznie dłuższy niż zwykle.
Aby wziąć to pod uwagę w naszych wynikach opóźnień, musimy skorygować coś, co nazywa się skoordynowanym pominięciem, w którym (jak wyjaśniono w notatce na końcu wrk2 README) „odpowiedzi o wysokich opóźnieniach powodują, że generator obciążenia koordynuje się z serwerem, aby uniknąć pomiaru podczas okresów wysokich opóźnień”. Na szczęście wrk2 domyślnie koryguje skoordynowane pomijanie (więcej szczegółów na temat skoordynowanego pomijania, zobacz README).
Gdy HAProxy MT wyczerpuje CPU przy 85,000 RPS, wiele żądań doświadcza wysokich opóźnień. Są one słusznie zawarte w danych, ponieważ poprawiamy skoordynowane pominięcie. Wystarczy jedno lub dwa żądania o wysokiej latencji, aby opóźnić ładowanie strony i spowodować postrzeganie słabej wydajności. Biorąc pod uwagę, że prawdziwy system obsługuje wielu użytkowników w tym samym czasie, nawet jeśli tylko 1% żądań ma wysokie opóźnienia (wartość na 99 percentylu), duża część użytkowników jest potencjalnie dotknięta.
Wniosek
Jednym z głównych punktów benchmarkingu wydajności jest określenie, czy twoja aplikacja jest wystarczająco responsywna, aby zadowolić użytkowników i sprawić, że będą wracać.
Oba NGINX i HAProxy są oparte na oprogramowaniu i mają architekturę sterowaną zdarzeniami. Podczas gdy HAProxy MP zapewnia lepszą wydajność niż HAProxy MT, brak współdzielenia stanu pomiędzy procesami sprawia, że zarządzanie nimi jest bardziej złożone, co opisaliśmy szczegółowo w HAProxy: Configuration and Versioning. HAProxy MT rozwiązuje te ograniczenia, ale kosztem niższej wydajności, jak pokazują wyniki.
W przypadku NGINX nie ma kompromisów – ponieważ procesy współdzielą stan, nie ma potrzeby stosowania trybu wielowątkowego. Otrzymujesz doskonałą wydajność wieloprocesowości bez ograniczeń, które sprawiają, że HAProxy zniechęca do jej stosowania.