NGINX e HAProxy: Testare l’esperienza dell’utente nel cloud
Molti benchmark delle prestazioni misurano il throughput di picco o le richieste al secondo (RPS), ma queste metriche possono semplificare eccessivamente la storia delle prestazioni nei siti del mondo reale. Poche organizzazioni eseguono i loro servizi al picco di velocità o vicino ad esso, dove un cambiamento del 10% nelle prestazioni può fare una differenza significativa. Il throughput o RPS richiesto da un sito non è infinito, ma è fissato da fattori esterni come il numero di utenti concorrenti che devono servire e il livello di attività di ciascun utente. Alla fine, ciò che conta di più è che i vostri utenti ricevano il miglior livello di servizio. Agli utenti finali non importa quante altre persone stanno visitando il vostro sito. Si preoccupano solo del servizio che ricevono e non scusano le scarse prestazioni perché il sistema è sovraccarico.
Questo ci porta all’osservazione che ciò che conta di più è che un’organizzazione fornisca prestazioni coerenti e a bassa latenza a tutti i suoi utenti, anche sotto carico elevato. Nel confrontare NGINX e HAProxy in esecuzione su Amazon Elastic Compute Cloud (EC2) come reverse proxy, ci siamo proposti di fare due cose:
- Determinare quale livello di carico ogni proxy gestisce comodamente
- Raccogliere la distribuzione percentile della latenza, che troviamo essere la metrica più direttamente correlata all’esperienza dell’utente
Protocolli di test e metriche raccolte
Abbiamo usato il programma di generazione di carico wrk2 per emulare un client, facendo richieste continue su HTTPS durante un periodo definito. Il sistema sotto test – HAProxy o NGINX – ha agito come un reverse proxy, stabilendo connessioni criptate con i client simulati dai thread wrk, inoltrando le richieste a un server web backend che esegue NGINX Plus R22, e restituendo la risposta generata dal server web (un file) al client.
Ognuno dei tre componenti (client, reverse proxy e server web) ha eseguito Ubuntu 20.04.1 LTS su una c5n.2xlarge Amazon Machine Image (AMI) in EC2.
Come detto, abbiamo raccolto la distribuzione percentile completa della latenza da ogni test. La latenza è definita come la quantità di tempo tra il client che genera la richiesta e la ricezione della risposta. Una distribuzione percentile della latenza ordina le misure di latenza raccolte durante il periodo di test dal più alto (più latenza) al più basso.
Metodologia del test
Client
Utilizzando wrk2 (versione 4.0.0), abbiamo eseguito il seguente script sull’istanza Amazon EC2:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Per simulare molti clienti che accedono a un’applicazione web, sono stati generati 4 wrk thread che insieme hanno stabilito 100 connessioni al reverse proxy. Durante i 30 secondi di test, lo script ha generato un numero specificato di RPS. Questi parametri corrispondono alle seguenti wrk2 opzioni:
-
‑topzione – Numero di thread da creare (4) -
‑copzione – Numero di connessioni TCP da creare (100) -
‑dopzione – Numero di secondi nel periodo di test (30 secondi) -
‑Ropzione – Numero di RPS emessi dal client -
‑‑latencyopzione – L’output include informazioni corrette sui percentili di latenza
Abbiamo aumentato progressivamente il numero di RPS durante il set di test fino a quando uno dei proxy ha raggiunto il 100% di utilizzo della CPU. Per ulteriori discussioni, vedere Risultati delle prestazioni.
Tutte le connessioni tra client e proxy sono state effettuate su HTTPS con TLSv1.3. Abbiamo usato ECC con una chiave a 256 bit, Perfect Forward Secrecy e la suite di cifratura TLS_AES_256_GCM_SHA384 (poiché TLSv1.2 è ancora comunemente usato su Internet, abbiamo ripetuto i test anche con esso; i risultati erano così simili a quelli di TLSv1.3 che non li includiamo qui: Configurazione e Versioning
Abbiamo fornito HAProxy versione 2.3 (stabile) come reverse proxy.
Il numero di utenti simultanei di un sito web popolare può essere enorme. Per gestire il grande volume di traffico, il tuo reverse proxy deve essere in grado di scalare per sfruttare più core. Ci sono due modi di base per scalare: multi-processing e multi-threading. Sia NGINX che HAProxy supportano il multiprocessing, ma c’è un’importante differenza: nell’implementazione di HAProxy, i processi non condividono la memoria (mentre in NGINX sì). L’incapacità di condividere lo stato tra i processi ha diverse conseguenze per HAProxy:
- I parametri di configurazione – compresi i limiti, le statistiche e i tassi – devono essere definiti separatamente per ogni processo.
- Le metriche delle prestazioni sono raccolte per processo; combinarle richiede un’ulteriore configurazione, che può essere piuttosto complessa.
- Ogni processo gestisce separatamente i controlli di salute, quindi i server di destinazione sono sondati per processo piuttosto che per server come previsto.
- La persistenza della sessione non è possibile.
- Una modifica dinamica della configurazione fatta tramite l’API di HAProxy Runtime si applica a un singolo processo, quindi è necessario ripetere la chiamata API per ogni processo.
A causa di questi problemi, HAProxy scoraggia fortemente l’uso della sua implementazione multi-processing. Per citare direttamente dal manuale di configurazione di HAProxy:
Utilizzare più processi è più difficile da debuggare ed è veramente sconsigliato.
HAProxy ha introdotto il multi-threading nella versione 1.8 come alternativa al multiprocesso. Il multi-threading risolve per lo più il problema della condivisione dello stato, ma come discutiamo in Risultati delle prestazioni, in modalità multi-thread HAProxy non funziona così bene come in modalità multi-processo.
La nostra configurazione di HAProxy includeva il provisioning sia per la modalità multi-thread (HAProxy MT) che per la modalità multi-processo (HAProxy MP). Per alternare le modalità ad ogni livello RPS durante i test, abbiamo commentato e decommentato l’appropriato set di linee e riavviato HAProxy per far sì che la configurazione avesse effetto:
$ sudo service haproxy restartEcco la configurazione con HAProxy MT predisposto: quattro thread sono creati sotto un processo e ogni thread è appuntato su una CPU. Per HAProxy MP (commentato qui), ci sono quattro processi ciascuno appuntato su una CPU.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Configurazione e Versioning
Abbiamo distribuito NGINX Open Source versione 1.18.0 come reverse proxy.
Per utilizzare tutti i core disponibili sulla macchina (quattro in questo caso), abbiamo incluso il parametro auto alla direttiva worker_processes, che è anche l’impostazione nel file predefinito nginx.conf distribuito dal nostro repository. Inoltre, la direttiva worker_cpu_affinity è stata inclusa per vincolare ogni processo worker a una CPU (ogni 1 nel secondo parametro denota una CPU nella macchina).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Risultati delle prestazioni
Come front end della tua applicazione, le prestazioni del tuo reverse proxy sono critiche.
Abbiamo testato ogni reverse proxy (NGINX, HAProxy MP, e HAProxy MT) con un numero crescente di RPS fino a quando uno di loro ha raggiunto il 100% di utilizzo della CPU. Tutti e tre si sono comportati in modo simile ai livelli RPS in cui la CPU non era esaurita.
Il raggiungimento del 100% di utilizzo della CPU si è verificato prima per HAProxy MT, a 85.000 RPS, e a quel punto le prestazioni sono peggiorate drasticamente sia per HAProxy MT che HAProxy MP. Qui presentiamo la distribuzione percentile della latenza di ogni reverse proxy a quel livello di carico. Il grafico è stato tracciato dall’output dello script wrk utilizzando il programma HdrHistogram disponibile su GitHub.
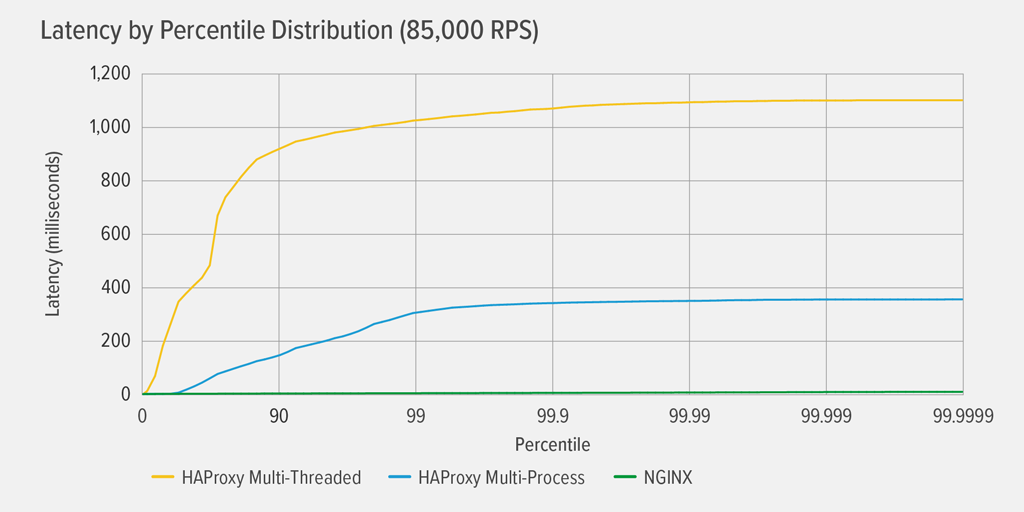
A 85.000 RPS, la latenza con HAProxy MT sale bruscamente fino al 90° percentile, poi gradualmente si stabilizza a circa 1100 millisecondi (ms).
HAProxy MP si comporta meglio di HAProxy MT – la latenza sale ad un ritmo più lento fino al 99° percentile, a quel punto inizia a livellarsi a circa 400 ms. (Come conferma che HAProxy MP è più efficiente, abbiamo osservato che HAProxy MT ha usato leggermente più CPU di HAProxy MP ad ogni livello RPS.)
NGINX non soffre praticamente di latenza a nessun percentile. La latenza più alta che un numero significativo di utenti potrebbe sperimentare (al 99,9999° percentile) è di circa 8ms.
Cosa ci dicono questi risultati sull’esperienza dell’utente? Come menzionato nell’introduzione, la metrica che conta veramente è il tempo di risposta dalla prospettiva dell’utente finale, e non il tempo di servizio del sistema sotto test.
È un malinteso comune che la latenza mediana in una distribuzione rappresenti meglio l’esperienza dell’utente. In realtà, la mediana è il numero che circa la metà dei tempi di risposta è peggiore! Gli utenti tipicamente emettono molte richieste e accedono a molte risorse per ogni caricamento di pagina, quindi molte delle loro richieste sono destinate a sperimentare latenze ai percentili superiori del grafico (dal 99° al 99,9999°). Poiché gli utenti sono così intolleranti alle scarse prestazioni, le latenze ai percentili alti sono quelle che più probabilmente noteranno.
Pensatela in questo modo: la vostra esperienza di check-out in un negozio di alimentari è determinata da quanto tempo ci vuole per uscire dal negozio dal momento in cui vi siete messi in coda alla cassa, non solo da quanto tempo ci ha messo il cassiere a registrare i vostri articoli. Se, per esempio, un cliente davanti a voi contesta il prezzo di un articolo e il cassiere deve trovare qualcuno che lo verifichi, il vostro tempo complessivo alla cassa è molto più lungo del solito.
Per tenere conto di questo nei nostri risultati di latenza, abbiamo bisogno di correggere qualcosa chiamato omissione coordinata, in cui (come spiegato in una nota alla fine del wrk2 README) “risposte ad alta latenza risultano nel generatore di carico che si coordina con il server per evitare la misurazione durante periodi di alta latenza”. Fortunatamente wrk2 corregge l’omissione coordinata per impostazione predefinita (per maggiori dettagli sull’omissione coordinata, vedere il README).
Quando HAProxy MT esaurisce la CPU a 85.000 RPS, molte richieste sperimentano una latenza elevata. Sono giustamente incluse nei dati perché stiamo correggendo l’omissione coordinata. Bastano una o due richieste ad alta latenza per ritardare il caricamento di una pagina e provocare la percezione di scarse prestazioni. Dato che un sistema reale serve più utenti alla volta, anche se solo l’1% delle richieste ha una latenza elevata (il valore al 99° percentile), una grande proporzione di utenti è potenzialmente interessata.
Conclusione
Uno dei punti principali del benchmarking delle prestazioni è determinare se la tua app è abbastanza reattiva da soddisfare gli utenti e farli tornare.
Sia NGINX che HAProxy sono basati su software e hanno architetture event-driven. Mentre HAProxy MP offre prestazioni migliori di HAProxy MT, la mancanza di condivisione dello stato tra i processi rende la gestione più complessa, come abbiamo dettagliato in HAProxy: Configurazione e Versioning. HAProxy MT affronta queste limitazioni, ma a spese di prestazioni inferiori, come dimostrato nei risultati.
Con NGINX, non ci sono compromessi: poiché i processi condividono lo stato, non c’è bisogno di una modalità multi-threading. Si ottengono le prestazioni superiori del multiprocesso senza le limitazioni che fanno sì che HAProxy ne scoraggi l’uso.
Si ottiene la prestazione superiore del multiprocesso senza le limitazioni che fanno sì che HAProxy scoraggi il suo uso.