Big Data és Hadoop Ecosystem Tutorial
Köszöntöm önöket a Simplilearn által kínált ‘Big Data Hadoop és Spark Developer Certification course’ részeként elérhető Big Data Hadoop tutorial első leckéjén, a ‘Big Data Hadoop and Hadoop Ecosystem’ című leckén. Ez a lecke a Big Data és a Hadoop ökoszisztéma bemutatása. A következő részben a lecke céljait tárgyaljuk.
Célkitűzések
A lecke elvégzése után Ön képes lesz:
-
megérti a Big Data fogalmát és a vele kapcsolatos kihívásokat
-
Magyarázza, mi a Big Data
-
Magyarázza, mi a Hadoop. és hogyan kezeli a Big Data kihívásait
-
Írd le a Hadoop ökoszisztémát
Vessünk most egy pillantást a Big Data és a Hadoop áttekintésére.
Áttekintés a Big Data és a Hadoop
A 2000-es év előtt az adatok viszonylag kisebbek voltak, mint jelenleg; az adatok számítása azonban összetett volt. Minden adatszámítás a rendelkezésre álló számítógépek feldolgozási teljesítményétől függött.
Az adatok növekedésével később a megoldást a nagy memóriával és gyors processzorokkal rendelkező számítógépek jelentették. 2000 után azonban az adatok tovább nőttek, és a kezdeti megoldás már nem tudott segíteni.
Az elmúlt néhány évben hihetetlenül megugrott az adatok mennyisége. Az IBM jelentése szerint 2012-ben naponta 2,5 exabájt, azaz 2,5 milliárd gigabájtnyi adat keletkezett.
Az adatok burjánzását jelző néhány statisztika a Forbes 2015. szeptemberi számából. Másodpercenként 40 000 keresési lekérdezést hajtanak végre a Google-on. A YouTube-ra percenként akár 300 órányi videót töltenek fel.
A Facebookon 31,25 millió üzenetet küldenek a felhasználók és 2,77 millió videót néznek meg percenként. 2017-re a fényképek közel 80%-át okostelefonokkal készítik.
2020-ra az összes adat legalább egyharmada a felhőn (az interneten keresztül összekapcsolt szerverek hálózatán) keresztül fog áramlani. 2020-ra a bolygón élő minden egyes ember számára másodpercenként mintegy 1,7 megabájtnyi új információ keletkezik.
Az adatok minden eddiginél gyorsabban növekednek. Több számítógépet lehet használni ennek az egyre növekvő adatmennyiségnek a kezelésére. Ahelyett, hogy egyetlen gép végezné el a feladatot, több gépet is használhat. Ezt nevezzük elosztott rendszernek.
A Big Data Hadoop and Spark Developer Certification tanfolyam előzetesét itt nézheti meg!
Nézzünk egy példát, hogy megértsük, hogyan működik egy elosztott rendszer.
Hogyan működik egy elosztott rendszer?
Tegyük fel, hogy van egy gépünk, amely négy be- és kimeneti csatornával rendelkezik. Az egyes csatornák sebessége 100 MB/sec, és egy terabájtnyi adatot szeretnénk feldolgozni rajta.
Egy gépnek 45 percbe telik egy terabájtnyi adat feldolgozása. Most tegyük fel, hogy egy terabájtnyi adatot 100 gép dolgoz fel ugyanazzal a konfigurációval.
Egy terabájtnyi adat feldolgozása 100 gépnek mindössze 45 másodpercig tart. Az elosztott rendszerek kevesebb időt vesznek igénybe a nagy adatok feldolgozásához.
Most nézzük meg az elosztott rendszerek kihívásait.
Az elosztott rendszerek kihívásai
Mivel több számítógépet használnak egy elosztott rendszerben, nagy az esélye a rendszerhibának. A sávszélesség is korlátozott.
A programozás bonyolultsága is magas, mivel nehéz az adatok és a folyamatok szinkronizálása. A Hadoop képes kezelni ezeket a kihívásokat.
A következő részben értsük meg, mi is a Hadoop.
Mi a Hadoop?
A Hadoop egy olyan keretrendszer, amely lehetővé teszi nagy adathalmazok elosztott feldolgozását számítógépfürtökben, egyszerű programozási modellek segítségével. A Google által közzétett technikai dokumentum ihlette.
A Hadoop szónak nincs jelentése. Doug Cutting, a Hadoop felfedezője a fiáról, a sárga színű játékelefántról nevezte el.
Tárgyaljuk meg, hogyan oldja meg a Hadoop az elosztott rendszer három kihívását, mint a rendszerhiba nagy esélye, a sávszélesség korlátja és a programozás bonyolultsága.
A Hadoop négy fő jellemzője a következő:
-
Gazdaságosság: Rendszerei rendkívül gazdaságosak, mivel az adatfeldolgozáshoz közönséges számítógépek is használhatók.
-
megbízhatóság: Megbízható, mivel az adatok másolatait különböző gépeken tárolja, és ellenáll a hardverhibáknak.
-
Skálázható: Könnyen skálázható mind horizontálisan, mind vertikálisan. Néhány extra csomópont segít a keretrendszer skálázásában.
-
Flexibilis: Rugalmas, és annyi strukturált és strukturálatlan adatot tárolhat, amennyit csak akar, és később dönthet a felhasználásukról.
Tradicionálisan az adatokat egy központi helyen tárolták, és futásidőben küldték el a processzornak. Ez a módszer jól működött korlátozott mennyiségű adat esetén.
A modern rendszerek azonban naponta terabájtnyi adatot fogadnak, és a hagyományos számítógépek vagy a relációs adatbázis-kezelő rendszer (RDBMS) nehezen tudnak nagy mennyiségű adatot a processzorra tolni.
A Hadoop radikális megközelítést hozott. A Hadoopban a program megy az adatokhoz, nem pedig fordítva. Kezdetben több rendszerre osztja szét az adatokat, és később ott végzi el a számításokat, ahol az adatok találhatók.
A következő részben arról lesz szó, hogy miben különbözik a Hadoop a hagyományos adatbázisrendszertől.
Különbség a hagyományos adatbázisrendszer és a Hadoop között
Az alábbi táblázat segít megkülönböztetni a hagyományos adatbázisrendszert és a Hadoopot.
|
Hagyományos adatbázisrendszer |
Hadoop |
|
Az adatokat egy központi helyen tárolják, és futáskor küldik a processzornak. |
A Hadoopban a program az adatokhoz megy. Kezdetben szétosztja az adatokat több rendszerben, és később a számítást ott végzi, ahol az adatok találhatók. |
|
A hagyományos adatbázis-rendszerek nem használhatók jelentős mennyiségű adat (big data) feldolgozására és tárolására. |
A Hadoop jobban működik, ha az adatok mérete nagy. Nagy mennyiségű adatot képes hatékonyan és eredményesen feldolgozni és tárolni. |
|
A hagyományos RDBMS-t csak strukturált és félig strukturált adatok kezelésére használják. Nem használható strukturálatlan adatok kezelésére. |
A Hadoop képes a legkülönbözőbb adatok feldolgozására és tárolására, legyenek azok strukturáltak vagy strukturálatlanok. |
A hagyományos RDBMS és a Hadoop közötti különbséget egy hasonlat segítségével tárgyaljuk.
Elképzelhető, hogy észrevetted a különbséget egy ember és egy tigris étkezési stílusa között. Az ember egy kanál segítségével eszik, ahol az ételt a szájához viszik. Míg a tigris a száját az étel felé viszi.
Most, ha az étel az adat, a száj pedig egy program, akkor az ember evési stílusa a hagyományos RDBMS-t, a tigrisé pedig a Hadoopot ábrázolja.
A következő részben nézzük meg a Hadoop ökoszisztémát.
Hadoop ökoszisztéma
Hadoop ökoszisztéma A Hadoop ökoszisztémája a három fő komponenséből, a feldolgozásból, az erőforrás-kezelésből és a tárolásból alakult ki. Ebben a témakörben megismerheti a Hadoop ökoszisztéma összetevőit és azt, hogy azok hogyan töltik be szerepüket a Big Data feldolgozás során. A
Hadoop ökoszisztéma folyamatosan növekszik, hogy megfeleljen a Big Data igényeinek. A következő tizenkét komponensből áll:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop. MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
A következő fejezetekben megismerhetjük a Hadoop ökoszisztéma egyes összetevőinek szerepét.

Magyarázzuk el a Hadoop ökoszisztéma egyes összetevőinek szerepét.
A Hadoop ökoszisztéma összetevői
Kezdjük a Hadoop ökoszisztéma első komponensével, a HDFS-szel.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
A HDFS a Hadoop tárolási rétege.
-
A HDFS alkalmas elosztott tárolásra és feldolgozásra, azaz az adatok tárolása közben először elosztásra kerülnek, majd feldolgozásra.
-
A HDFS Streaming hozzáférést biztosít a fájlrendszer adataihoz.
-
A HDFS fájlengedélyezést és hitelesítést biztosít.
-
A HDFS parancssori felületet használ a Hadooppal való interakcióhoz.
Mi tárolja az adatokat a HDFS-ben? A HBase az, ami a HDFS-ben tárolja az adatokat.
HBase
-
A HBase egy NoSQL adatbázis vagy nem relációs adatbázis.
-
A HBase fontos és főleg akkor használatos, ha véletlenszerű, valós idejű, olvasási vagy írási hozzáférésre van szükség a Big Data-hoz.
-
Támogatást nyújt nagy adatmennyiséghez és nagy áteresztőképességhez.
-
A HBase-ben egy táblának több ezer oszlopa lehet.
Az adatok elosztásáról és tárolásáról beszéltünk. Most pedig értsük meg, hogyan történik ezeknek az adatoknak a bevitele vagy átvitele a HDFS-be. A Sqoop pontosan ezt teszi.
Mi a Sqoop?
-
A Sqoop egy olyan eszköz, amelyet a Hadoop és a relációs adatbázis-kiszolgálók közötti adatátvitelre terveztek.
-
Az adatok relációs adatbázisokból (például Oracle és MySQL) a HDFS-be történő importálására és a HDFS-ből relációs adatbázisokba történő exportálására szolgál.
Ha eseményadatokat, például streaming adatokat, szenzoradatokat vagy naplófájlokat szeretnénk bevinni, akkor használhatjuk a Flume-ot. A flume-ot a következő részben nézzük meg.
Flume
-
A flume egy elosztott szolgáltatás, amely eseményadatokat gyűjt és továbbítja a HDFS-be.
-
Ez ideálisan alkalmas több rendszerből származó eseményadatokra.
Az adatok HDFS-be történő továbbítása után az adatok feldolgozásra kerülnek. Az adatok feldolgozását végző keretrendszerek egyike a Spark.
Mi az a Spark?
-
A Spark egy nyílt forráskódú fürtszámítási keretrendszer.
-
A Hadoop kétlépcsős, lemezalapú MapReduce paradigmájához képest akár százszor gyorsabb teljesítményt biztosít néhány alkalmazás számára az in-memory primitívekkel.
-
A Spark képes a Hadoop fürtben futni és a HDFS-ben lévő adatokat feldolgozni.
-
Támogatja a munkaterhelés széles skáláját is, amely magában foglalja a gépi tanulást, az üzleti intelligenciát, a streaminget és a kötegelt feldolgozást.
A Spark a következő főbb összetevőkből áll:
-
Spark Core és Resilient Distributed datasets vagy RDD
-
Spark SQL
-
Spark streaming
-
Machine learning library vagy Mlib
-
Graphx.
A Sparkot ma már széles körben használják, és a következő leckékben többet fogsz róla megtudni.
Hadoop MapReduce
-
A másik adatfeldolgozó keretrendszer a Hadoop MapReduce.
-
Ez az eredeti Hadoop-feldolgozó motor, amely elsősorban Java-alapú.
-
A map and reduces programozási modellen alapul.
-
Sok eszköz, például a Hive és a Pig is map-reduce modellre épül.
-
Kiterjedt és kiforrott hibatűrés van beépítve a keretrendszerbe.
-
Még mindig nagyon gyakran használják, de veszít a Sparkkal szemben.
Az adatok feldolgozása után az adatok elemzése következik. Ezt egy Pig nevű, nyílt forráskódú, magas szintű adatáramlási rendszerrel lehet elvégezni. Ezt elsősorban analitikára használják.
Magyarázzuk most, hogyan használják a Pig-et analitikára.
Pig
-
A Pig a szkriptjeit Map és Reduce kóddá alakítja, így megkíméli a felhasználót a bonyolult MapReduce programok írásától.
-
Az olyan ad-hoc lekérdezések, mint a Filter és Join, amelyeket MapReduce-ban nehéz végrehajtani, könnyen elvégezhetők a Pig segítségével.
-
Az adatok elemzésére az Impala is használható.
-
Ez egy nyílt forráskódú, nagy teljesítményű SQL-motor, amely a Hadoop-klaszteren fut.
-
Ideális interaktív elemzésekhez, és nagyon alacsony, milliszekundumokban mérhető késleltetéssel rendelkezik.
Impala
-
Az Impala támogatja az SQL egy dialektusát, így a HDFS-ben lévő adatokat adatbázis-táblaként modellezi.
-
A HIVE segítségével is végezhetünk adatelemzést. Ez egy absztrakciós réteg a Hadoop tetején.
-
Ez nagyon hasonlít az Impalához. Az adatfeldolgozáshoz és az Extract Transform Load, más néven ETL műveletekhez azonban előnyösebb.
-
Az Impala ad-hoc lekérdezésekhez előnyösebb.
HIVE
-
A HIVE MapReduce segítségével hajtja végre a lekérdezéseket; a felhasználónak azonban nem kell alacsony szintű MapReduce kódot írnia.
-
A Hive strukturált adatokhoz alkalmas. Az adatok elemzése után a felhasználók számára elérhetővé válnak.
Most, hogy tudjuk, mit csinál a HIVE, beszéljünk arról, hogy mi támogatja az adatok keresését. Az adatok keresése a Cloudera Search segítségével történik.
Cloudera Search
-
A keresés a Cloudera egyik közel valós idejű hozzáférési terméke. Lehetővé teszi a nem technikai felhasználók számára a Hadoopban és HBase-ben tárolt vagy oda bevitt adatok keresését és feltárását.
-
A felhasználóknak nincs szükségük SQL- vagy programozási ismeretekre a Cloudera Search használatához, mivel a kereséshez egyszerű, teljes szöveges felületet biztosít.
-
A Cloudera Search további előnye az önálló keresési megoldásokkal szemben a teljesen integrált adatfeldolgozási platform.
-
A Cloudera Search a CDH-hoz vagy a Cloudera Distributionhez tartozó rugalmas, skálázható és robusztus tárolórendszert használja, beleértve a Hadoopot is. Ez kiküszöböli a nagy adathalmazok infrastruktúrák közötti mozgatásának szükségességét az üzleti feladatok megoldásához.
-
A Hadoop-feladatok, például a MapReduce, Pig, Hive és Sqoop munkafolyamatokkal rendelkeznek.
Oozie
-
Az Oozie egy munkafolyamat- vagy koordinációs rendszer, amelyet a Hadoop-munkák kezelésére használhatunk.
Az Oozie alkalmazás életciklusa az alábbi ábrán látható.
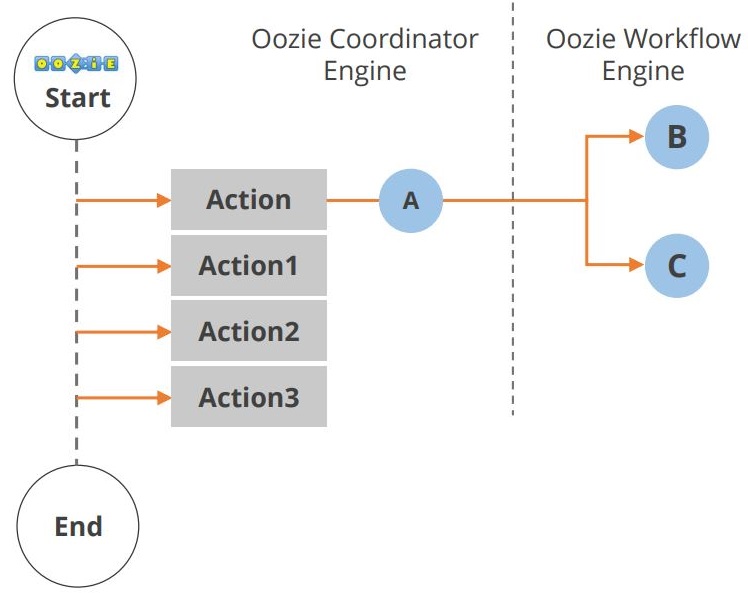 Amint látható, a munkafolyamat kezdete és vége között több művelet történik. A Hadoop ökoszisztéma egy másik összetevője a Hue. Nézzük most a Hue-t.
Amint látható, a munkafolyamat kezdete és vége között több művelet történik. A Hadoop ökoszisztéma egy másik összetevője a Hue. Nézzük most a Hue-t.
Hue
A Hue a Hadoop User Experience rövidítése. Ez egy nyílt forráskódú webes felület a Hadoophoz. A Hue segítségével a következő műveleteket végezheti:
-
Adatok feltöltése és böngészése
-
Táblák lekérdezése a HIVE-ban és az Impalában
-
Spark és Pig feladatok és munkafolyamatok futtatása Adatok keresése
-
Összességében a Hue megkönnyíti a Hadoop használatát.
-
Ez SQL-szerkesztőt is biztosít a HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL és Solr SQL számára.
A Hadoop ökoszisztéma tizenkét összetevőjének rövid áttekintése után most arról lesz szó, hogy ezek az összetevők hogyan működnek együtt a Big Data feldolgozásában.
A Big Data feldolgozásának szakaszai
A Big Data feldolgozásának négy szakasza van: Ingest, Processing, Analyze, Access. Nézzük meg őket részletesen.
Ingest
A Big Data feldolgozás első szakasza az Ingest. Az adatokat különböző forrásokból, például relációs adatbázisokból, rendszerekből vagy helyi fájlokból ingestálják vagy továbbítják a Hadoopba. A Sqoop az adatokat az RDBMS-ből a HDFS-be továbbítja, míg a Flume az eseményadatokat.
Feldolgozás
A második szakasz a feldolgozás. Ebben a szakaszban az adatok tárolása és feldolgozása történik. Az adatok tárolása az elosztott fájlrendszerben, a HDFS-ben és a NoSQL elosztott adatokban, a HBase-ben történik. Az adatfeldolgozást a Spark és a MapReduce végzi.
Analyze
A harmadik szakasz az Analyze. Itt az adatokat olyan feldolgozó keretrendszerek elemzik, mint a Pig, a Hive és az Impala.
A Pig átalakítja az adatokat map és reduce segítségével, majd elemzi azokat. A Hive szintén a map and reduce programozáson alapul, és leginkább strukturált adatokra alkalmas.
Access
A negyedik szakasz a Access, amelyet olyan eszközök végeznek, mint a Hue és a Cloudera Search. Ebben a szakaszban a felhasználók hozzáférhetnek az elemzett adatokhoz.
A Hue a webes felület, míg a Cloudera Search egy szöveges felületet biztosít az adatok feltárásához.
Nézze meg a Big Data Hadoop and Spark Developer Certification tanfolyamot itt!
Összefoglaló
Foglaljuk most össze, amit ebben a leckében tanultunk.
-
A Hadoop egy elosztott tárolásra és feldolgozásra szolgáló keretrendszer.
-
A Hadoop alapkomponensei közé tartozik a HDFS a tároláshoz, a YARN a fürt-erőforráskezeléshez és a MapReduce vagy Spark a feldolgozáshoz.
-
A Hadoop ökoszisztéma több komponenst tartalmaz, amelyek a Big Data feldolgozás minden egyes szakaszát támogatják.
-
A Flume és a Sqoop adatokat vesz fel, a HDFS és a HBase adatokat tárol, a Spark és a MapReduce adatokat dolgoz fel, a Pig, a Hive és az Impala adatokat elemez, a Hue és a Cloudera Search segít az adatok feltárásában.
-
Oozie kezeli a Hadoop-feladatok munkafolyamatát.
Következtetés
Ezzel zárul a Big Data és a Hadoop ökoszisztéma című lecke. A következő leckében a HDFS-t és a YARN-t tárgyaljuk.
Találja meg Big Data Hadoop és Spark fejlesztői online tantermi képzéseinket a legnépszerűbb városokban:
| Name | Date | Place | |
|---|---|---|---|
| Big Data Hadoop and Spark Developer | 3 Apr -15 May 2021, Hétvégi batch | Városod | Nézd meg a részleteket |
| Big Data Hadoop and Spark Developer | 12 ápr -4 május 2021, Hétköznap batch | Az Ön városa | Nézze meg a részleteket |
| Big Data Hadoop and Spark Developer | 24 ápr -5 jún 2021, Weekend batch | Az Ön városa | Nézze meg a részleteket |
{{lectureCoursePreviewTitle}} Átirat megtekintése Videó megtekintése
Továbbképzés
Big Data Hadoop and Spark Developer Certification Training
Go to Course
To learn more, vegyen részt a Tanfolyam
Big Data Hadoop and Spark Developer Certification Training Menj a Tanfolyamra