NGINX et HAProxy : Tester l’expérience utilisateur dans le cloud
De nombreux benchmarks de performance mesurent le débit de pointe ou les demandes par seconde (RPS), mais ces mesures peuvent simplifier à l’excès l’histoire des performances sur les sites du monde réel. Peu d’organisations exécutent leurs services à un débit maximal ou presque, alors qu’une variation de 10 % des performances dans un sens ou dans l’autre peut faire une différence significative. Le débit ou le RPS requis par un site n’est pas infini, mais est fixé par des facteurs externes tels que le nombre d’utilisateurs simultanés qu’ils doivent servir et le niveau d’activité de chaque utilisateur. Au final, ce qui compte le plus, c’est que vos utilisateurs reçoivent le meilleur niveau de service. Les utilisateurs finaux ne se soucient pas du nombre de personnes qui visitent votre site. Ils se soucient juste du service qu’ils reçoivent et n’excusent pas les mauvaises performances parce que le système est surchargé.
Ceci nous amène à l’observation que ce qui importe le plus est qu’une organisation fournisse des performances cohérentes et à faible latence à tous ses utilisateurs, même sous une charge élevée. En comparant NGINX et HAProxy fonctionnant sur Amazon Elastic Compute Cloud (EC2) en tant que reverse proxies, nous avons entrepris de faire deux choses :
- Déterminer le niveau de charge que chaque proxy gère confortablement
- Collecter la distribution des percentiles de latence, qui, selon nous, est la métrique la plus directement corrélée à l’expérience utilisateur
Protocoles de test et métriques collectées
Nous avons utilisé le programme de génération de charge wrk2 pour émuler un client, en effectuant des requêtes continues sur HTTPS pendant une période définie. Le système testé – HAProxy ou NGINX – a agi comme un reverse proxy, établissant des connexions cryptées avec les clients simulés par wrk threads, transmettant les demandes à un serveur web backend exécutant NGINX Plus R22, et renvoyant la réponse générée par le serveur web (un fichier) au client.
Chacun des trois composants (client, reverse proxy et serveur web) a exécuté Ubuntu 20.04.1 LTS sur une image de machine Amazon (AMI) c5n.2xlarge dans EC2.
Comme mentionné, nous avons recueilli la distribution complète des percentiles de latence de chaque exécution de test. La latence est définie comme la quantité de temps entre le client générant la demande et la réception de la réponse. Une distribution de percentile de latence trie les mesures de latence collectées pendant la période de test du plus élevé (le plus de latence) au plus bas.
Méthodologie de test
Client
Utilisant wrk2 (version 4.0.0), nous avons exécuté le script suivant sur l’instance Amazon EC2 :
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Pour simuler de nombreux clients accédant à une application web, 4 wrk threads ont été engendrés qui ont établi ensemble 100 connexions au reverse proxy. Pendant l’exécution du test de 30 secondes, le script a généré un nombre spécifié de RPS. Ces paramètres correspondent aux wrk2 options suivantes :
-
‑toption – Nombre de threads à créer (4) -
‑coption – Nombre de connexions TCP à créer (100) -
‑doption – Nombre de secondes dans la période de test (30 secondes) -
‑Roption -. Nombre de RPS émis par le client -
‑‑latencyoption – La sortie comprend des informations corrigées sur le percentile de latence
Nous avons augmenté de manière incrémentielle le nombre de RPS sur l’ensemble des tests jusqu’à ce qu’un des proxys atteigne une utilisation du CPU de 100 %. Pour une discussion plus approfondie, voir Résultats des performances.
Toutes les connexions entre le client et le proxy ont été effectuées sur HTTPS avec TLSv1.3. Nous avons utilisé ECC avec une taille de clé de 256 bits, Perfect Forward Secrecy et la suite de chiffrement TLS_AES_256_GCM_SHA384. (Parce que TLSv1.2 est encore couramment utilisé sur Internet, nous avons relancé les tests avec lui également ; les résultats étaient si similaires à ceux de TLSv1.3 que nous ne les incluons pas ici.)
HAProxy : Configuration et versionnement
Nous avons provisionné HAProxy version 2.3 (stable) comme proxy inverse.
Le nombre d’utilisateurs simultanés sur un site Web populaire peut être énorme. Pour gérer ce grand volume de trafic, votre reverse proxy doit pouvoir évoluer pour tirer parti de plusieurs cœurs. Il existe deux méthodes de base pour faire évoluer le système : le multitraitement et le multithreading. NGINX et HAProxy prennent tous deux en charge le multitraitement, mais il existe une différence importante : dans l’implémentation de HAProxy, les processus ne partagent pas la mémoire (alors que dans NGINX, ils le font). L’incapacité de partager l’état entre les processus a plusieurs conséquences pour HAProxy :
- Les paramètres de configuration – y compris les limites, les statistiques et les taux – doivent être définis séparément pour chaque processus.
- Les mesures de performance sont collectées par processus ; les combiner nécessite une configuration supplémentaire, qui peut être assez complexe.
- Chaque processus gère les contrôles de santé séparément, de sorte que les serveurs cibles sont sondés par processus plutôt que par serveur comme prévu.
- La persistance de session n’est pas possible.
- Un changement de configuration dynamique effectué via l’API d’exécution HAProxy s’applique à un seul processus, de sorte que vous devez répéter l’appel API pour chaque processus.
En raison de ces problèmes, HAProxy déconseille fortement l’utilisation de son implémentation multi-processus. Pour citer directement le manuel de configuration de HAProxy :
L’utilisation de plusieurs processus est plus difficile à déboguer et est vraiment déconseillée.
HAProxy a introduit le multi-threading dans la version 1.8 comme alternative au multi-processus. Le multithreading résout principalement le problème du partage d’état, mais comme nous le discutons dans Résultats de performance, en mode multithread, HAProxy n’est pas aussi performant qu’en mode multi-processus.
Notre configuration HAProxy comprenait un provisionnement pour le mode multi-thread (HAProxy MT) et le mode multi-processus (HAProxy MP). Pour alterner entre les modes à chaque niveau de RPS pendant les tests, nous avons commenté et décommenté l’ensemble approprié de lignes et redémarré HAProxy pour que la configuration prenne effet :
$ sudo service haproxy restartVoici la configuration avec HAProxy MT provisionné : quatre threads sont créés sous un processus et chaque thread épinglé à un CPU. Pour HAProxy MP (commenté ici), il y a quatre processus chacun épinglé à un CPU.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX : Configuration et versionnement
Nous avons déployé NGINX Open Source version 1.18.0 comme proxy inverse.
Pour utiliser tous les cœurs disponibles sur la machine (quatre dans ce cas), nous avons inclus le paramètre auto à la directive worker_processes, qui est également le paramètre dans le fichier nginx.conf par défaut distribué depuis notre dépôt. En outre, la directive worker_cpu_affinity a été incluse pour épingler chaque processus de travailleur à un CPU (chaque 1 dans le deuxième paramètre dénote un CPU dans la machine).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Résultats de performance
En tant que front-end de votre application, la performance de votre reverse proxy est critique.
Nous avons testé chaque reverse proxy (NGINX, HAProxy MP et HAProxy MT) à des nombres croissants de RPS jusqu’à ce que l’un d’entre eux atteigne une utilisation de 100% du CPU. Les trois ont eu des performances similaires aux niveaux de RPS où le CPU n’était pas épuisé.
L’atteinte de 100% d’utilisation du CPU s’est produite en premier pour HAProxy MT, à 85 000 RPS, et à ce moment-là, les performances se sont détériorées de façon spectaculaire pour HAProxy MT et HAProxy MP. Nous présentons ici la distribution des percentiles de latence de chaque proxy inverse à ce niveau de charge. Le graphique a été tracé à partir de la sortie du script wrk en utilisant le programme HdrHistogram disponible sur GitHub.
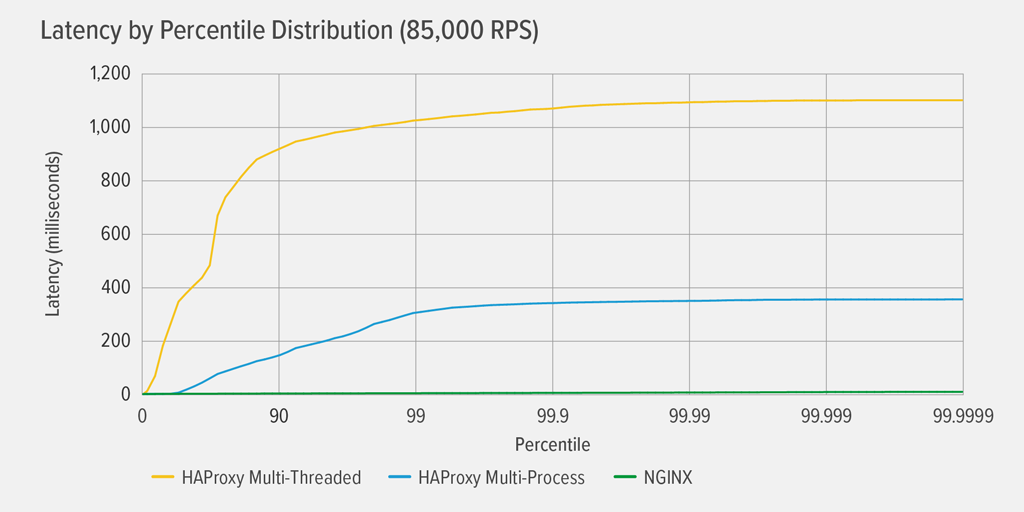
À 85 000 RPS, la latence avec HAProxy MT grimpe brusquement jusqu’au 90e percentile, puis se stabilise progressivement à environ 1100 millisecondes (ms).
HAProxy MP a de meilleures performances que HAProxy MT – la latence grimpe à un rythme plus lent jusqu’au 99e percentile, puis commence à se stabiliser à environ 400 ms. (Pour confirmer que HAProxy MP est plus efficace, nous avons observé que HAProxy MT utilisait légèrement plus de CPU que HAProxy MP à chaque niveau de RPS.)
NGINX ne souffre pratiquement d’aucune latence à n’importe quel percentile. La latence la plus élevée qu’un nombre significatif d’utilisateurs pourrait subir (au 99,9999e percentile) est d’environ 8ms.
Que nous disent ces résultats sur l’expérience utilisateur ? Comme mentionné dans l’introduction, la métrique qui compte vraiment est le temps de réponse du point de vue de l’utilisateur final, et non le temps de service du système testé.
C’est une idée fausse courante que la latence médiane dans une distribution représente le mieux l’expérience utilisateur. En fait, la médiane est le nombre auquel environ la moitié des temps de réponse sont inférieurs ! Les utilisateurs émettent généralement de nombreuses requêtes et accèdent à de nombreuses ressources par chargement de page, de sorte que plusieurs de leurs requêtes sont vouées à connaître des latences correspondant aux percentiles supérieurs du graphique (99e à 99,9999e). Parce que les utilisateurs sont si intolérants aux mauvaises performances, les latences aux percentiles élevés sont celles qu’ils sont le plus susceptibles de remarquer.
Pensez-y de la manière suivante : votre expérience du passage en caisse dans une épicerie est déterminée par le temps qu’il faut pour quitter le magasin à partir du moment où vous vous êtes placé dans la file d’attente, et pas seulement par le temps qu’il faut à la caissière pour enregistrer vos articles. Si, par exemple, un client devant vous conteste le prix d’un article et que la caissière doit demander à quelqu’un de le vérifier, votre temps global de passage en caisse est beaucoup plus long que d’habitude.
Pour prendre cela en compte dans nos résultats de latence, nous devons corriger quelque chose appelé omission coordonnée, dans lequel (comme expliqué dans une note à la fin du wrk2 README) « les réponses à latence élevée entraînent le générateur de charge à coordonner avec le serveur pour éviter la mesure pendant les périodes de latence élevée ». Heureusement, wrk2 corrige l’omission coordonnée par défaut (pour plus de détails sur l’omission coordonnée, voir le README).
Lorsque HAProxy MT épuise le CPU à 85 000 RPS, de nombreuses requêtes connaissent une latence élevée. Elles sont légitimement incluses dans les données parce que nous corrigeons l’omission coordonnée. Il suffit d’une ou deux requêtes à forte latence pour retarder le chargement d’une page et donner l’impression de mauvaises performances. Étant donné qu’un système réel sert plusieurs utilisateurs à la fois, même si seulement 1 % des demandes ont une latence élevée (la valeur au 99e percentile), une grande proportion d’utilisateurs est potentiellement affectée.
Conclusion
L’un des principaux points de l’analyse comparative des performances est de déterminer si votre application est suffisamment réactive pour satisfaire les utilisateurs et les inciter à revenir.
Les deux NGINX et HAProxy sont basés sur des logiciels et ont des architectures orientées événements. Si HAProxy MP offre de meilleures performances que HAProxy MT, l’absence de partage d’état entre les processus rend la gestion plus complexe, comme nous l’avons détaillé dans HAProxy : Configuration et gestion des versions. HAProxy MT résout ces limitations, mais au prix de performances inférieures, comme le montrent les résultats.
Avec NGINX, il n’y a pas de compromis – parce que les processus partagent l’état, il n’y a pas besoin d’un mode multithreading. Vous obtenez les performances supérieures du multitraitement sans les limitations qui font que HAProxy décourage son utilisation.
.