NGINX y HAProxy: Probando la experiencia del usuario en la nube
Muchos puntos de referencia de rendimiento miden el rendimiento máximo o las solicitudes por segundo (RPS), pero esas métricas pueden simplificar demasiado la historia del rendimiento en los sitios del mundo real. Pocas organizaciones ejecutan sus servicios a un rendimiento máximo o cerca de él, donde un cambio del 10% en el rendimiento puede suponer una diferencia significativa. El rendimiento o RPS que necesita un sitio no es infinito, sino que viene determinado por factores externos como el número de usuarios simultáneos a los que hay que dar servicio y el nivel de actividad de cada usuario. Al final, lo que más importa es que sus usuarios reciban el mejor nivel de servicio. A los usuarios finales no les importa cuántas personas visitan su sitio. Sólo les importa el servicio que reciben y no excusan un mal rendimiento porque el sistema esté sobrecargado.
Esto nos lleva a la observación de que lo que más importa es que una organización ofrezca un rendimiento consistente y de baja latencia a todos sus usuarios, incluso bajo alta carga. Al comparar NGINX y HAProxy ejecutados en Amazon Elastic Compute Cloud (EC2) como proxies inversos, nos propusimos hacer dos cosas:
- Determinar qué nivel de carga maneja cómodamente cada proxy
- Recoger la distribución del percentil de latencia, que encontramos que es la métrica más directamente correlacionada con la experiencia del usuario
Protocolos de prueba y métricas recogidas
Utilizamos el programa de generación de carga wrk2 para emular a un cliente, realizando peticiones continuas sobre HTTPS durante un periodo definido. El sistema bajo prueba – HAProxy o NGINX – actuó como un proxy inverso, estableciendo conexiones encriptadas con los clientes simulados por hilos wrk, reenviando las peticiones a un servidor web backend que ejecutaba NGINX Plus R22, y devolviendo la respuesta generada por el servidor web (un archivo) al cliente.
Cada uno de los tres componentes (cliente, proxy inverso y servidor web) ejecutó Ubuntu 20.04.1 LTS en una Imagen de Máquina de Amazon (AMI) c5n.2xlarge en EC2.
Como se mencionó, recopilamos la distribución percentil de latencia completa de cada ejecución de prueba. La latencia se define como la cantidad de tiempo entre que el cliente genera la solicitud y recibe la respuesta. Una distribución de percentiles de latencia ordena las mediciones de latencia recopiladas durante el periodo de prueba de mayor (mayor latencia) a menor.
Metodología de prueba
Cliente
Usando wrk2 (versión 4.0.0), ejecutamos el siguiente script en la instancia de Amazon EC2:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Para simular que muchos clientes acceden a una aplicación web, se generaron 4 hilos wrkque en conjunto establecieron 100 conexiones al proxy inverso. Durante los 30 segundos de ejecución de la prueba, el script generó un número determinado de RPS. Estos parámetros corresponden a las siguientes opciones wrk2:
-
‑topción – Número de hilos a crear (4) -
‑copción – Número de conexiones TCP a crear (100) -
‑dopción – Número de segundos en el periodo de prueba (30 segundos) -
‑Ropción -. Número de RPS emitidos por el cliente -
‑‑latencyopción – La salida incluye información corregida del percentil de latencia
Aumentamos gradualmente el número de RPS a lo largo del conjunto de pruebas hasta que uno de los proxies alcanzó el 100% de utilización de la CPU. Para más información, véase Resultados de rendimiento.
Todas las conexiones entre el cliente y el proxy se realizaron sobre HTTPS con TLSv1.3. Usamos ECC con un tamaño de clave de 256 bits, Perfect Forward Secrecy y el conjunto de cifrado TLS_AES_256_GCM_SHA384. (Dado que TLSv1.2 todavía se usa comúnmente en Internet, volvimos a realizar las pruebas con él también; los resultados fueron tan similares a los de TLSv1.3 que no los incluimos aquí.)
HAProxy: Configuración y versionado
Provisionamos HAProxy versión 2.3 (estable) como proxy inverso.
El número de usuarios simultáneos en un sitio web popular puede ser enorme. Para manejar el gran volumen de tráfico, su proxy inverso necesita ser capaz de escalar para aprovechar múltiples núcleos. Hay dos formas básicas de escalar: el multiprocesamiento y el multihilo. Tanto NGINX como HAProxy soportan el multiprocesamiento, pero hay una diferencia importante: en la implementación de HAProxy, los procesos no comparten memoria (mientras que en NGINX sí lo hacen). La incapacidad de compartir estado entre procesos tiene varias consecuencias para HAProxy:
- Los parámetros de configuración -incluyendo límites, estadísticas y tasas- deben definirse por separado para cada proceso.
- Las métricas de rendimiento se recogen por proceso; combinarlas requiere una configuración adicional, que puede ser bastante compleja.
- Cada proceso maneja las comprobaciones de salud por separado, por lo que los servidores de destino son sondeados por proceso en lugar de por servidor como se esperaba.
- La persistencia de la sesión no es posible.
- Un cambio de configuración dinámica realizado a través de la API de tiempo de ejecución de HAProxy se aplica a un solo proceso, por lo que debe repetir la llamada a la API para cada proceso.
Debido a estos problemas, HAProxy desaconseja encarecidamente el uso de su implementación de multiprocesamiento. Citando directamente el manual de configuración de HAProxy:
Usar múltiples procesos es más difícil de depurar y está realmente desaconsejado.
HAProxy introdujo el multihilo en la versión 1.8 como alternativa al multiproceso. El multihilo resuelve en su mayor parte el problema de compartir el estado, pero como comentamos en Resultados de rendimiento, en modo multihilo HAProxy no rinde tanto como en modo multiproceso.
Nuestra configuración de HAProxy incluyó el aprovisionamiento para el modo multihilo (HAProxy MT) y el modo multiproceso (HAProxy MP). Para alternar entre los modos en cada nivel de RPS durante las pruebas, comentamos y descomentamos el conjunto apropiado de líneas y reiniciamos HAProxy para que la configuración surtiera efecto:
$ sudo service haproxy restartAquí está la configuración con HAProxy MT aprovisionado: se crean cuatro hilos bajo un proceso y cada hilo se fija a una CPU. Para HAProxy MP (comentado aquí), hay cuatro procesos cada uno anclado a una CPU.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Configuración y Versionado
Desplegamos la versión 1.18.0 de NGINX Open Source como proxy inverso.
Para utilizar todos los núcleos disponibles en la máquina (cuatro en este caso), incluimos el parámetro auto a la directiva worker_processes, que es también la configuración en el archivo nginx.conf por defecto distribuido desde nuestro repositorio. Además, la directiva worker_cpu_affinity se incluyó para fijar cada proceso de trabajador a una CPU (cada 1 en el segundo parámetro denota una CPU en la máquina).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Resultados de rendimiento
Como extremo frontal de su aplicación, el rendimiento de su proxy inverso es crítico.
Probamos cada proxy inverso (NGINX, HAProxy MP y HAProxy MT) en un número creciente de RPS hasta que uno de ellos alcanzó el 100% de utilización de la CPU. Los tres se comportaron de forma similar en los niveles de RPS en los que la CPU no se agotó.
Alcanzar el 100% de utilización de la CPU ocurrió primero para HAProxy MT, a 85.000 RPS, y en ese punto el rendimiento empeoró drásticamente tanto para HAProxy MT como para HAProxy MP. Aquí presentamos la distribución del percentil de latencia de cada proxy inverso a ese nivel de carga. El gráfico se trazó a partir de la salida del script wrk utilizando el programa HdrHistogram disponible en GitHub.
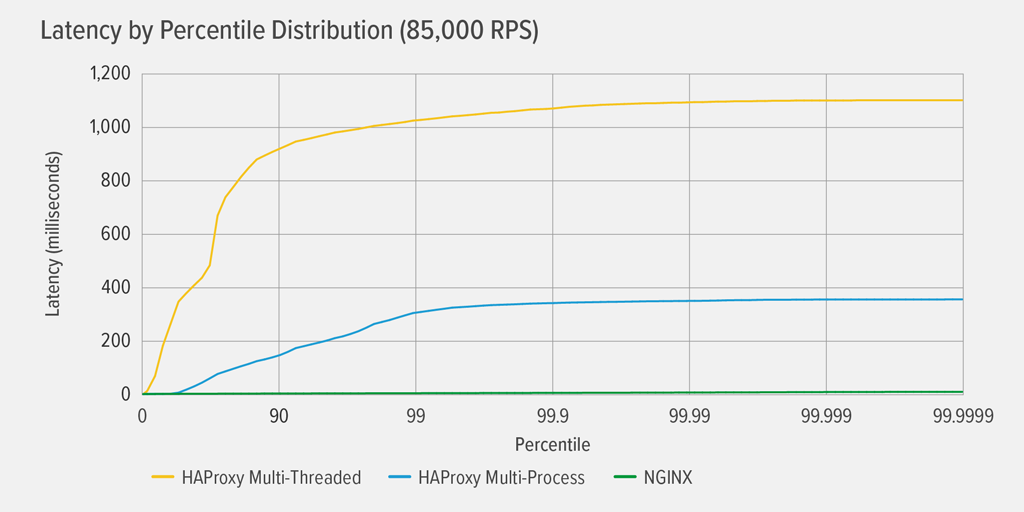
A los 85.000 RPS, la latencia con HAProxy MT sube abruptamente hasta el percentil 90, y luego se nivela gradualmente a aproximadamente 1100 milisegundos (ms).
HAProxy MP se comporta mejor que HAProxy MT – la latencia sube a un ritmo más lento hasta el percentil 99, momento en el que comienza a nivelarse en aproximadamente 400 ms. (Como confirmación de que HAProxy MP es más eficiente, observamos que HAProxy MT utilizó ligeramente más CPU que HAProxy MP en cada nivel de RPS.)
NGINX no sufre prácticamente ninguna latencia en ningún percentil. La latencia más alta que podría experimentar cualquier número significativo de usuarios (en el percentil 99,9999) es de aproximadamente 8ms.
¿Qué nos dicen estos resultados sobre la experiencia del usuario? Como se mencionó en la introducción, la métrica que realmente importa es el tiempo de respuesta desde la perspectiva del usuario final, y no el tiempo de servicio del sistema bajo prueba.
Es un error común pensar que la mediana de la latencia en una distribución representa mejor la experiencia del usuario. De hecho, ¡la mediana es el número que supera la mitad de los tiempos de respuesta! Los usuarios suelen hacer muchas peticiones y acceder a muchos recursos por cada carga de página, por lo que varias de sus peticiones están destinadas a experimentar latencias en los percentiles superiores del gráfico (del 99 al 99,9999). Dado que los usuarios son tan intolerantes al bajo rendimiento, las latencias en los percentiles altos son las que más probablemente notarán.
Piénsalo de esta manera: tu experiencia al pagar en una tienda de comestibles está determinada por el tiempo que se tarda en salir de la tienda desde el momento en que te pusiste en la cola de la caja, no sólo por el tiempo que tardó la cajera en cobrar tus artículos. Si, por ejemplo, un cliente que está delante de ti discute el precio de un artículo y la cajera tiene que pedirle a alguien que lo verifique, tu tiempo total en la caja es mucho más largo de lo habitual.
Para tener esto en cuenta en nuestros resultados de latencia, tenemos que corregir algo llamado omisión coordinada, en la que (como se explica en una nota al final del LÉEME de wrk2) «las respuestas de alta latencia hacen que el generador de carga se coordine con el servidor para evitar la medición durante los períodos de alta latencia». Por suerte wrk2 corrige la omisión coordinada por defecto (para más detalles sobre la omisión coordinada, véase el README).
Cuando HAProxy MT agota la CPU a 85.000 RPS, muchas peticiones experimentan una alta latencia. Se incluyen correctamente en los datos porque estamos corrigiendo la omisión coordinada. Basta con una o dos peticiones de alta latencia para retrasar la carga de una página y dar lugar a la percepción de un bajo rendimiento. Dado que un sistema real está sirviendo a múltiples usuarios a la vez, incluso si sólo el 1% de las solicitudes tienen una alta latencia (el valor en el percentil 99), una gran proporción de usuarios se ven potencialmente afectados.
Conclusión
Uno de los puntos principales de la evaluación comparativa del rendimiento es determinar si su aplicación es lo suficientemente sensible para satisfacer a los usuarios y hacer que vuelvan.
Tanto NGINX como HAProxy se basan en el software y tienen arquitecturas basadas en eventos. Aunque HAProxy MP ofrece un mejor rendimiento que HAProxy MT, la falta de compartición de estado entre los procesos hace que la gestión sea más compleja, como detallamos en HAProxy: Configuración y control de versiones. HAProxy MT aborda estas limitaciones, pero a expensas de un menor rendimiento como se demuestra en los resultados.
Con NGINX, no hay compensaciones – porque los procesos comparten el estado, no hay necesidad de un modo multihilo. Se obtiene el rendimiento superior del multiprocesamiento sin las limitaciones que hacen que HAProxy desaconseje su uso.