Reddit AmItheAsshole är snällare mot kvinnor än mot män – ett SQL-bevis?
När redditorerna frågar ”är jag en skitstövel?” när de pratar om kvinnor har de större chans att bli dömda som skitstövel. Låt oss kolla in dessa mätvärden – med BigQuery, dbt och Data Studio
Se till att inte ta allt jag skrivit här som den absoluta sanningen. Flera personer på Twitter noterade problem och lade till korrigeringar till den analys jag erbjöd. Att läsa det här inlägget som det ursprungligen presenterades – och reaktionerna – kan vara ett utmärkt sätt för dig att lära dig lika mycket som jag gjorde när jag läste svaren. Du kan hitta många av deras ofiltrerade tankar genom att följa den här Twittertråden.
Context
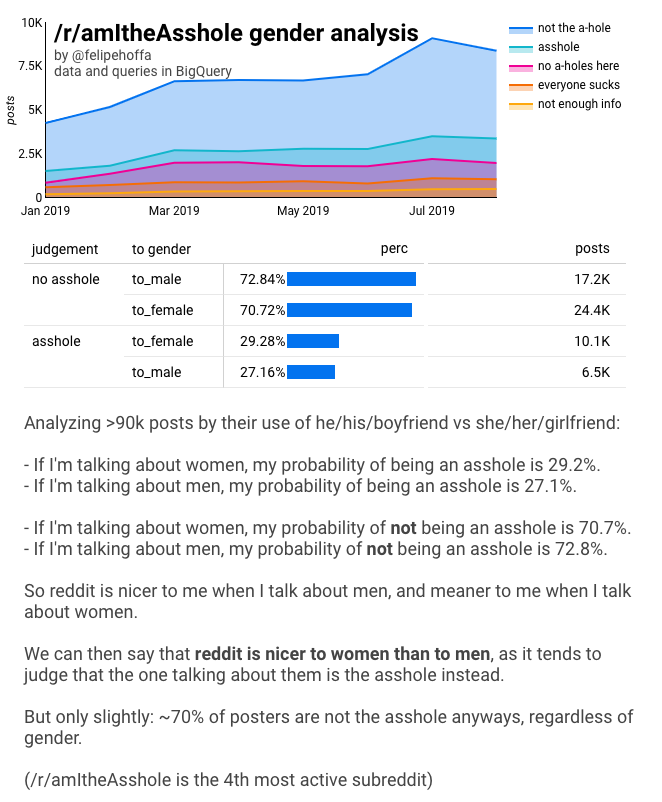
/r/amItheAsshole har vuxit till att vara den fjärde mest aktiva subreddit – sett till antalet kommentarer. Människor kommer till detta subreddit för att berätta sina historier, och de frågar andra redditors ”är det jag som är skitstöveln här?”. Det visar sig att de flesta bedöms som ”inte skitstöveln”, vilket framgår av det här diagrammet:
Min tweet med dessa resultat fick mycket uppmärksamhet:
Inklusive frågan – är reddit trevligare mot kvinnor eller män?
Besluta om kön
Om man tittar på rubriken eller innehållet i ett inlägg kan man ha svårt att avgöra om ”jag” är en man eller en kvinna – men det är ganska lätt att räkna antalet ”hon/han/hon/hans/flickvän/pojkvän” som förekommer i berättelsen.
Låt oss titta på några slumpmässiga inlägg, och räkningen för vart och ett av dessa pronomen och könsord:

Vi kan se att antalet könade pronomen och ord i exemplet stämmer överens med vem berättelsen handlar om. Dessa berättelser handlar om en manlig kund, en kvinnlig flickvän, en manlig granne, en manlig son och en kvinnlig tonårsdotter.
Med dessa siffror kan vi nu fastställa en godtycklig regel: Om det finns mer än dubbelt så många manliga pronomen som kvinnliga, så handlar det inlägget om en man. Vi kan använda den motsatta regeln för att säga att inlägget handlar om en kvinna. Om siffrorna ligger för nära varandra eller är noll kallar vi inlägget för ”neutralt”.
En annan regel som vi kan sätta upp för att förenkla analysen:
- Om bedömningen är ”inte a-hål” eller ”inga a-hål här” kan vi säga att ”affischen är inte ett rövhål”.
- Om bedömningen är ’skitstövel’ eller ’alla är skitstövlar’ så kan vi säga ’affischen är en skitstövel’.
Om vi aggregerar alla dessa inlägg får vi fram siffrorna:

När jag först presenterade de här resultaten fick jag höra ”de här siffrorna ligger för nära varandra, de kan vara ett statistiskt fel”.
Statistisk signifikans?
Hur kan vi veta att siffrorna inte bara är ett statistiskt fel? Låt oss se trenden månad för månad – är den stabil?

Ja! Trenden varierar från månad till månad, men det finns en klart högre chans att vara en skitstövel när man pratar om kvinnor än när man pratar om män. Om den lilla skillnaden bara var en statistisk slump skulle vi förvänta oss att trenden skulle hoppa vilt i stället.
Och observera att dessa resultat är mycket specifika, vilket den här tweeten noterar:
Som jag svarade
Hur man gör
Den här gången använder jag dbt för första gången, och jag lämnade all min kod på GitHub. Tack Claire Carroll för din hjälp att komma igång med detta fantastiska verktyg!
För att extrahera alla /r/AmItheAsshole-inlägg i BigQuery till en ny tabell kan du göra:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Därefter kan kön och omdöme för varje inlägg bestämmas med en fråga som:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
Och slutligen den statistik som presenteras här:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Diskussion
Du hittar massor av insiktsfulla och underhållande svar på twittertråden för det här inlägget:
Deltag gärna i diskussionen (och säg till mig om jag har fel?). Kom ihåg att vara trevliga mot varandra – de flesta är inte skitstövlar ändå.
Vill du ha mer?
Jag täckte bara fram till augusti 2019 eftersom det är då som det nuvarande fullständiga reddit-arkivet i BigQuery slutar – fram till framtida förväntade uppdateringar. Se mitt tidigare inlägg för mer information om hur man samlar in direktdata från pushshift.io. Tack Jason Baumgartner för det ständiga utbudet!
Jag heter Felipe Hoffa och är Developer Advocate för Google Cloud. Följ mig på @felipehoffa, hitta mina tidigare inlägg på medium.com/@hoffa och allt om BigQuery på reddit.com/r/bigquery.