Handledning om Big Data och Hadoops ekosystem
Välkommen till den första lektionen ”Big Data och Hadoops ekosystem” i handledningen om Big Data och Hadoop, som är en del av certifieringskursen för utvecklare av Big Data Hadoop och Spark som erbjuds av Simplilearn. Den här lektionen är en introduktion till Big Data och Hadoop-ekosystemet. I nästa avsnitt kommer vi att diskutera målen för den här lektionen.
Mål
När du har slutfört den här lektionen kommer du att kunna:
-
Förstå begreppet Big Data och dess utmaningar
-
Förklara vad Big Data är
-
Förklara vad Hadoop är. och hur det hanterar Big Data-utmaningar
-
Beskriv Hadoops ekosystem
Låt oss nu ta en titt på en översikt över Big Data och Hadoop.
Översikt över Big Data och Hadoop
För år 2000 var data relativt sett mindre än vad de är idag, men databeräkningen var komplex. All databeräkning var beroende av bearbetningskraften hos de tillgängliga datorerna.
Senare när data växte var lösningen att ha datorer med stort minne och snabba processorer. Efter 2000 fortsatte dock data att växa och den ursprungliga lösningen kunde inte längre hjälpa.
Under de senaste åren har det skett en otrolig explosion av datamängden. IBM rapporterade att 2,5 exabyte, eller 2,5 miljarder gigabyte, data genererades varje dag 2012.
Här är några statistiska uppgifter som visar på spridningen av data från Forbes, september 2015. 40 000 sökfrågor utförs på Google varje sekund. Upp till 300 timmars video laddas upp till YouTube varje minut.
I Facebook skickas 31,25 miljoner meddelanden av användarna och 2,77 miljoner videor ses varje minut. År 2017 kommer nästan 80 % av fotona att tas med smartphones.
För 2020 kommer minst en tredjedel av alla data att passera genom molnet (ett nätverk av servrar som är anslutna via Internet). År 2020 kommer cirka 1,7 megabyte ny information att skapas varje sekund för varje människa på planeten.
Data växer snabbare än någonsin tidigare. Du kan använda fler datorer för att hantera denna ständigt växande data. Istället för att en maskin utför jobbet kan du använda flera maskiner. Detta kallas ett distribuerat system.
Du kan kolla in Big Data Hadoop and Spark Developer Certification course Preview här!
Låt oss titta på ett exempel för att förstå hur ett distribuerat system fungerar.
Hur fungerar ett distribuerat system?
Antag att du har en maskin som har fyra in-/utgångskanaler. Hastigheten för varje kanal är 100 MB/s och du vill bearbeta en terabyte data på den.
Det tar 45 minuter för en maskin att bearbeta en terabyte data. Låt oss nu anta att en terabyte data behandlas av 100 maskiner med samma konfiguration.
Det tar bara 45 sekunder för 100 maskiner att behandla en terabyte data. Distribuerade system tar mindre tid att bearbeta Big Data.
Nu ska vi titta på utmaningarna med ett distribuerat system.
Utmaningar med distribuerade system
Då flera datorer används i ett distribuerat system finns det stora risker för systemfel. Det finns också en gräns för bandbredden.
Programmeringskomplexiteten är också hög eftersom det är svårt att synkronisera data och processer. Hadoop kan hantera dessa utmaningar.
Låt oss förstå vad Hadoop är i nästa avsnitt.
Vad är Hadoop?
Hadoop är ett ramverk som möjliggör distribuerad behandling av stora datamängder över kluster av datorer med hjälp av enkla programmeringsmodeller. Det är inspirerat av ett tekniskt dokument som publicerats av Google.
Ordet Hadoop har ingen betydelse. Doug Cutting, som upptäckte Hadoop, namngav det efter sin sons gulfärgade leksakselefant.
Låt oss diskutera hur Hadoop löser de tre utmaningarna med distribuerade system, såsom stora chanser till systemfel, begränsning av bandbredd och programmeringskomplexitet.
De fyra viktigaste egenskaperna hos Hadoop är:
-
Ekonomiskt: Dess system är mycket ekonomiska eftersom vanliga datorer kan användas för databehandling.
-
Pålitligt: Det är tillförlitligt eftersom det lagrar kopior av data på olika maskiner och är motståndskraftigt mot hårdvarufel.
-
Skalerbart: Den är lätt skalbar både horisontellt och vertikalt. Några extra noder hjälper till att skala upp ramverket.
-
Flexibel: Det är flexibelt och du kan lagra så mycket strukturerade och ostrukturerade data som du behöver och bestämma dig för att använda dem senare.
Traditionellt sett lagrades data på en central plats och skickades till processorn vid körning. Den här metoden fungerade bra för begränsade data.
Moderna system tar dock emot terabyte av data per dag, och det är svårt för de traditionella datorerna eller RDBMS (Relational Database Management System) att skjuta stora datamängder till processorn.
Hadoop förde med sig ett radikalt tillvägagångssätt. I Hadoop går programmet till data, inte tvärtom. Det distribuerar initialt data till flera system och kör senare beräkningen där data finns.
I följande avsnitt kommer vi att tala om hur Hadoop skiljer sig från det traditionella databassystemet.
Skillnaden mellan traditionella databassystem och Hadoop
Tabellen nedan kommer att hjälpa dig att skilja mellan traditionella databassystem och Hadoop.
|
Traditionellt databassystem |
Hadoop |
|
Data lagras på en central plats och skickas till processorn vid körning. |
I Hadoop går programmet till data. Det distribuerar initialt data till flera system och kör senare beräkningen där data finns. |
|
Traditionella databassystem kan inte användas för att bearbeta och lagra en betydande mängd data(big data). |
Hadoop fungerar bättre när datastorleken är stor. Det kan behandla och lagra en stor mängd data effektivt och ändamålsenligt. |
|
Traditionella RDBMS används endast för att hantera strukturerade och halvstrukturerade data. Det kan inte användas för att kontrollera ostrukturerade data. |
Hadoop kan bearbeta och lagra en mängd olika data, oavsett om de är strukturerade eller ostrukturerade. |
Låt oss diskutera skillnaden mellan traditionella RDBMS och Hadoop med hjälp av en analogi.
Du har säkert lagt märke till skillnaden i matsättet hos en människa och en tiger. En människa äter mat med hjälp av en sked, där maten förs till munnen. Medan en tiger för munnen mot maten.
Om maten är data och munnen är ett program, så beskriver människans ätande stil traditionella RDBMS och tigerns Hadoop.
Låt oss titta på Hadoops ekosystem i nästa avsnitt.
Hadoops ekosystem
Hadoops ekosystem Hadoop har ett ekosystem som har utvecklats från dess tre kärnkomponenter bearbetning, resurshantering och lagring. I det här ämnet får du lära dig komponenterna i Hadoops ekosystem och hur de utför sina roller under Big Data-bearbetning. Ekosystemet
Hadoop växer kontinuerligt för att möta behoven av Big Data. Det består av följande tolv komponenter:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop. MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
Du kommer att lära dig mer om rollen för varje komponent i Hadoop-ekosystemet i de kommande avsnitten.

Låt oss förstå rollen för varje komponent i Hadoop-ekosystemet.
Komponenter i Hadoops ekosystem
Låt oss börja med den första komponenten HDFS i Hadoops ekosystem.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS är ett lagringslager för Hadoop.
-
HDFS lämpar sig för distribuerad lagring och bearbetning, det vill säga medan data lagras distribueras de först och bearbetas sedan.
-
HDFS ger Streaming-åtkomst till filsystemdata.
-
HDFS ger filbehörighet och autentisering.
-
HDFS använder ett kommandoradsgränssnitt för att interagera med Hadoop.
Vad lagrar då data i HDFS? Det är HBase som lagrar data i HDFS.
HBase
-
HBase är en NoSQL-databas eller icke-relationell databas.
-
HBase är viktig och används främst när du behöver slumpmässig, realtids-, läs- eller skrivåtkomst till dina Big Data.
-
Den ger stöd för en stor mängd data och hög genomströmning.
-
I en HBase kan en tabell ha tusentals kolumner.
Vi diskuterade hur data distribueras och lagras. Nu ska vi förstå hur dessa data tas in eller överförs till HDFS. Sqoop gör exakt detta.
Vad är Sqoop?
-
Sqoop är ett verktyg som är utformat för att överföra data mellan Hadoop och relationella databasservrar.
-
Det används för att importera data från relationsdatabaser (t.ex. Oracle och MySQL) till HDFS och exportera data från HDFS till relationsdatabaser.
Om du vill ta emot händelsedata, t.ex. strömmande data, sensordata eller loggfiler, kan du använda Flume. Vi kommer att titta på Flume i nästa avsnitt.
Flume
-
Flume är en distribuerad tjänst som samlar in händelsedata och överför den till HDFS.
-
Den är idealisk för händelsedata från flera olika system.
När datan har överförts till HDFS behandlas den. Ett av ramverken som behandlar data är Spark.
Vad är Spark?
-
Spark är ett ramverk för klusterdrift med öppen källkod.
-
Det ger upp till 100 gånger snabbare prestanda för ett fåtal tillämpningar med primitiver i minnet jämfört med det tvåstegs diskbaserade MapReduce-paradigmet i Hadoop.
-
Spark kan köras i Hadoop-klustret och behandla data i HDFS.
-
Det har också stöd för en mängd olika arbetsuppgifter, bland annat maskininlärning, Business Intelligence, streaming och batchbehandling.
Spark har följande huvudkomponenter:
-
Spark Core and Resilient Distributed datasets eller RDD
-
Spark SQL
-
Spark streaming
-
Machine learning library eller Mlib
-
Graphx.
Spark används nu i stor utsträckning, och du kommer att lära dig mer om det i efterföljande lektioner.
Hadoop MapReduce
-
Hadoop MapReduce är det andra ramverket som behandlar data.
-
Det är den ursprungliga Hadoop-bearbetningsmotorn, som främst är Java-baserad.
-
Den bygger på programmeringsmodellen map and reduces.
-
Många verktyg som Hive och Pig bygger på en map-reduce-modell.
-
Den har en omfattande och mogen feltolerans inbyggd i ramverket.
-
Den används fortfarande mycket ofta, men tappar terräng till Spark.
När datan är bearbetad analyseras den. Det kan göras med hjälp av ett dataflödessystem på hög nivå med öppen källkod som heter Pig. Det används främst för analys.
Låt oss nu förstå hur Pig används för analys.
Pig
-
Pig omvandlar sina skript till Map- och Reduce-kod, vilket gör att användaren slipper skriva komplexa MapReduce-program.
-
Ad hoc-förfrågningar som Filter och Join, som är svåra att utföra i MapReduce, kan enkelt göras med Pig.
-
Du kan också använda Impala för att analysera data.
-
Det är en högpresterande SQL-motor med öppen källkod som körs på Hadoop-klustret.
-
Den är idealisk för interaktiv analys och har mycket låg latens som kan mätas i millisekunder.
Impala
-
Impala har stöd för en dialekt av SQL, så data i HDFS modelleras som en databastabell.
-
Du kan också utföra dataanalyser med HIVE. Det är ett abstraktionslager ovanpå Hadoop.
-
Det är mycket likt Impala. Det är dock att föredra för databehandling och Extract Transform Load, även känt som ETL, operationer.
-
Impala är att föredra för ad hoc-frågor.
HIVE
-
HIVE utför frågor med hjälp av MapReduce; användaren behöver dock inte skriva någon kod i MapReduce på lågnivå.
-
Hive är lämplig för strukturerade data. När data har analyserats är de färdiga för användarna att få tillgång till.
När vi nu vet vad Hive gör ska vi diskutera vad som stöder sökning av data. Datasökning sker med hjälp av Cloudera Search.
Cloudera Search
-
Search är en av Clouderas produkter för åtkomst i nära realtid. Den gör det möjligt för icke-tekniska användare att söka och utforska data som lagras i eller tas in i Hadoop och HBase.
-
Användare behöver inte ha SQL- eller programmeringskunskaper för att använda Cloudera Search eftersom den tillhandahåller ett enkelt fulltextgränssnitt för sökning.
-
En annan fördel med Cloudera Search jämfört med fristående söklösningar är den helt integrerade databehandlingsplattformen.
-
Cloudera Search använder det flexibla, skalbara och robusta lagringssystemet som ingår i CDH eller Cloudera Distribution, inklusive Hadoop. Detta eliminerar behovet av att flytta stora datamängder mellan olika infrastrukturer för att hantera affärsuppgifter.
-
Hadoop-jobb som MapReduce, Pig, Hive och Sqoop har arbetsflöden.
Oozie
-
Oozie är ett arbetsflödes- eller samordningssystem som du kan använda för att hantera Hadoop-jobb.
Oozie-applikationens livscykel visas i diagrammet nedan.
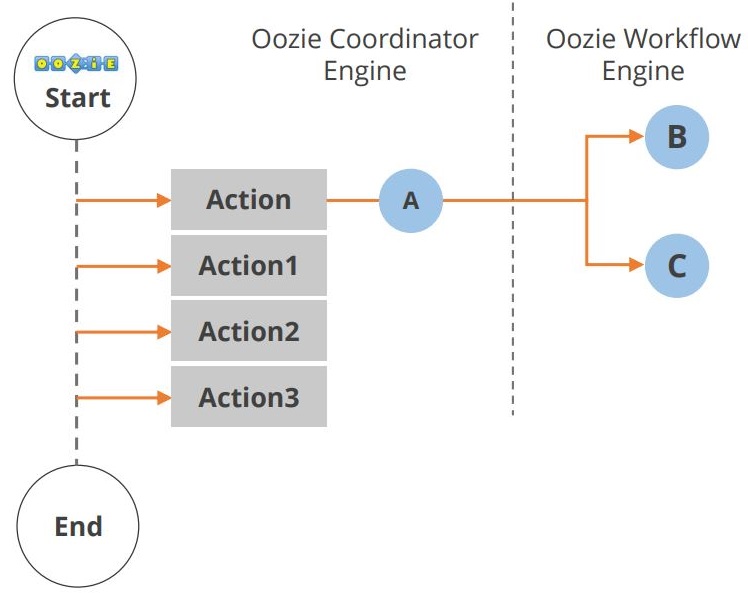 Som du kan se sker flera åtgärder mellan arbetsflödets början och slut. En annan komponent i Hadoops ekosystem är Hue. Låt oss titta på Hue nu.
Som du kan se sker flera åtgärder mellan arbetsflödets början och slut. En annan komponent i Hadoops ekosystem är Hue. Låt oss titta på Hue nu.
Hue
Hue är en akronym för Hadoop User Experience. Det är ett webbgränssnitt för Hadoop med öppen källkod. Du kan utföra följande operationer med Hue:
-
Ladda upp och bläddra bland data
-
Sök i en tabell i HIVE och Impala
-
Kör Spark- och Pig-jobb och arbetsflöden Sök i data
-
Totalt sett gör Hue Hadoop enklare att använda.
-
Det ger också SQL-redigerare för HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL och Solr SQL.
Efter denna korta översikt över de tolv komponenterna i Hadoop-ekosystemet kommer vi nu att diskutera hur dessa komponenter samarbetar för att bearbeta Big Data.
Steg i Big Data-bearbetning
Det finns fyra steg i Big Data-bearbetningen: Det finns fyra steg i Big Data: Ingest, Processing, Analyze, Access. Låt oss titta på dem i detalj.
Ingest
Det första steget i Big Data-behandlingen är Ingest. Data tas in eller överförs till Hadoop från olika källor, t.ex. relationsdatabaser, system eller lokala filer. Sqoop överför data från RDBMS till HDFS, medan Flume överför händelsedata.
Processing
Det andra steget är Processing. I det här steget lagras och bearbetas data. Data lagras i det distribuerade filsystemet HDFS och NoSQL-distribuerade data, HBase. Spark och MapReduce utför databehandlingen.
Analysera
Det tredje steget är Analysera. Här analyseras data med hjälp av bearbetningsramar som Pig, Hive och Impala.
Pig omvandlar data med hjälp av map och reduce och analyserar dem sedan. Hive bygger också på map and reduce-programmering och lämpar sig bäst för strukturerade data.
Access
Det fjärde steget är Access, som utförs av verktyg som Hue och Cloudera Search. I det här steget kan användarna få tillgång till de analyserade data.
Hue är webbgränssnittet, medan Cloudera Search tillhandahåller ett textgränssnitt för att utforska data.
Kolla in kursen Big Data Hadoop and Spark Developer Certification här!
Sammanfattning
Låt oss nu sammanfatta vad vi lärt oss i den här lektionen.
-
Hadoop är ett ramverk för distribuerad lagring och bearbetning.
-
Kärnkomponenterna i Hadoop omfattar HDFS för lagring, YARN för hantering av klusterresurser och MapReduce eller Spark för bearbetning.
-
Hadoop-ekosystemet omfattar flera komponenter som stöder varje steg i bearbetningen av stora data.
-
Flume och Sqoop tar in data, HDFS och HBase lagrar data, Spark och MapReduce bearbetar data, Pig, Hive och Impala analyserar data, Hue och Cloudera Search hjälper till att utforska data.
-
Oozie hanterar arbetsflödet för Hadoop-jobb.
Slutsats
Detta avslutar lektionen om Big Data och Hadoop-ekosystemet. I nästa lektion kommer vi att diskutera HDFS och YARN.
Hitta våra Big Data Hadoop and Spark Developer Online Classroom-utbildningar i de bästa städerna:
| Namn | Datum | Plats | |
|---|---|---|---|
| Big Data Hadoop and Spark Developer | 3 apr -15 maj 2021, Weekend batch | Din stad | Se detaljer |
| Big Data Hadoop and Spark Developer | 12 apr -4 maj 2021, Partiet vardagar | Din stad | Se detaljer |
| Big Data Hadoop and Spark Developer | 24 apr -5 jun 2021, Weekend batch | Din stad | Se detaljer |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
För att lära dig mer, gå kursen
Big Data Hadoop and Spark Developer Certification Training
Gå till kursen
För att lära dig mer, gå till kursen
Big Data Hadoop and Spark Developer Certification Training Gå till kursen