NGINX și HAProxy: Testarea experienței utilizatorilor în cloud
Multe repere de performanță măsoară debitul maxim sau solicitările pe secundă (RPS), dar aceste măsurători pot simplifica prea mult povestea performanței pe site-urile din lumea reală. Puține organizații își rulează serviciile la debitul maxim sau aproape de acesta, unde o schimbare de 10% în performanță în ambele sensuri poate face o diferență semnificativă. Debitul sau RPS-ul de care are nevoie un site nu este infinit, ci este stabilit de factori externi, cum ar fi numărul de utilizatori simultani pe care trebuie să îi deservească și nivelul de activitate al fiecărui utilizator. În cele din urmă, ceea ce contează cel mai mult este ca utilizatorii dvs. să primească cel mai bun nivel de servicii. Utilizatorilor finali nu le pasă cât de mulți alți oameni vă vizitează site-ul. Le pasă doar de serviciul pe care îl primesc și nu scuză performanțele slabe pentru că sistemul este supraîncărcat.
Acest lucru ne conduce la observația că ceea ce contează cel mai mult este ca o organizație să ofere performanțe consistente și cu latență redusă tuturor utilizatorilor săi, chiar și în condiții de sarcină ridicată. Comparând NGINX și HAProxy care rulează pe Amazon Elastic Compute Cloud (EC2) ca proxy invers, ne-am propus să facem două lucruri:
- Determinarea nivelului de încărcare pe care fiecare proxy îl gestionează confortabil
- Colectarea distribuției percentilelor de latență, despre care am constatat că este metrica cea mai direct corelată cu experiența utilizatorilor
Protocoale de testare și măsurători colectate
Am folosit programul de generare a încărcăturii wrk2 pentru a emula un client, făcând cereri continue prin HTTPS pe parcursul unei perioade definite. Sistemul testat – HAProxy sau NGINX – a acționat ca un proxy invers, stabilind conexiuni criptate cu clienții simulați de firele wrk, redirecționând cererile către un server web backend care rulează NGINX Plus R22 și returnând răspunsul generat de serverul web (un fișier) către client.
Care dintre cele trei componente (client, proxy invers și server web) a rulat Ubuntu 20.04.1 LTS pe un c5n.2xlarge Amazon Machine Image (AMI) în EC2.
După cum am menționat, am colectat distribuția completă a percentilelor de latență de la fiecare execuție de test. Latența este definită ca fiind timpul scurs între momentul în care clientul generează cererea și cel în care primește răspunsul. O distribuție a percentilelor de latență ordonează măsurătorile de latență colectate în timpul perioadei de testare de la cea mai mare (cea mai mare latență) la cea mai mică.
Metodologie de testare
Client
Utilizând wrk2 (versiunea 4.0.0), am rulat următorul script pe instanța Amazon EC2:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Pentru a simula mai mulți clienți care accesează o aplicație web, au fost generate 4 fire de execuție wrk care împreună au stabilit 100 de conexiuni la proxy-ul invers. În timpul rulării testului de 30 de secunde, scriptul a generat un număr specificat de RPS. Acești parametri corespund următoarelor opțiuni wrk2:
-
‑topțiune – Numărul de fire de execuție de creat (4) -
‑copțiune – Numărul de conexiuni TCP de creat (100) -
‑dopțiune – Numărul de secunde din perioada de testare (30 de secunde) -
‑Ropțiune Numărul de RPS emise de client -
‑‑latencyoption – Output-ul include informații corectate privind percentila de latență
Am crescut incremental numărul de RPS pe parcursul setului de testări până când unul dintre proxy-uri a atins 100% din utilizarea CPU. Pentru o discuție suplimentară, consultați Rezultatele performanței.
Toate conexiunile dintre client și proxy au fost realizate prin HTTPS cu TLSv1.3. Am folosit ECC cu o dimensiune a cheii de 256 de biți, Perfect Forward Secrecy și suita de cifrare TLS_AES_256_GCM_SHA384. (Deoarece TLSv1.2 este încă utilizat în mod obișnuit pe Internet, am refăcut testele și cu acesta; rezultatele au fost atât de asemănătoare cu cele pentru TLSv1.3 încât nu le includem aici.)
HAProxy: Configuration and Versioning
Am provizionat HAProxy versiunea 2.3 (stabilă) ca proxy invers.
Numărul de utilizatori simultani pe un site web popular poate fi uriaș. Pentru a face față volumului mare de trafic, proxy-ul dvs. invers trebuie să fie capabil să se scaleze pentru a profita de mai multe nuclee. Există două modalități de bază de scalare: multi-procesare și multi-threading. Atât NGINX, cât și HAProxy acceptă multiprocesarea, dar există o diferență importantă – în implementarea HAProxy, procesele nu împart memoria (în timp ce în NGINX o fac). Incapacitatea de a partaja starea între procese are mai multe consecințe pentru HAProxy:
- Parametrii de configurare – inclusiv limitele, statisticile și ratele – trebuie să fie definiți separat pentru fiecare proces.
- Metricele de performanță sunt colectate per proces; combinarea lor necesită o configurare suplimentară, care poate fi destul de complexă.
- Care proces gestionează verificările de sănătate separat, astfel încât serverele țintă sunt sondate per proces, mai degrabă decât per server, așa cum era de așteptat.
- Persistența sesiunii nu este posibilă.
- O modificare dinamică a configurației efectuată prin intermediul HAProxy Runtime API se aplică unui singur proces, astfel încât trebuie să repetați apelul API pentru fiecare proces.
Din cauza acestor probleme, HAProxy descurajează puternic utilizarea implementării sale multiprocesare. Pentru a cita direct din manualul de configurare HAProxy:
Utilizarea mai multor procese este mai greu de depanat și este cu adevărat descurajată.
HAProxy a introdus multi-threading-ul în versiunea 1.8 ca alternativă la multi-procesare. Multi-threading-ul rezolvă în mare parte problema împărțirii stării, dar, așa cum discutăm în secțiunea Rezultate de performanță, în modul multi-thread, HAProxy nu are performanțe la fel de bune ca în modul multi-proces.
Configurația noastră HAProxy a inclus provizionarea atât pentru modul multi-thread (HAProxy MT), cât și pentru modul multiproces (HAProxy MP). Pentru a alterna între moduri la fiecare nivel RPS în timpul testelor, am comentat și decomentat setul corespunzător de linii și am repornit HAProxy pentru ca configurația să intre în vigoare:
$ sudo service haproxy restartIată configurația cu HAProxy MT provizionat: patru fire de execuție sunt create sub un proces și fiecare fir de execuție este fixat pe o unitate centrală de procesare. Pentru HAProxy MP (comentat aici), există patru procese, fiecare fixat pe un CPU.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Configuration and Versioning
Am implementat NGINX Open Source versiunea 1.18.0 ca reverse proxy.
Pentru a utiliza toate nucleele disponibile pe mașină (patru în acest caz), am inclus parametrul auto la directiva worker_processes, care este, de asemenea, setarea din fișierul implicit nginx.conf distribuit din depozitul nostru. În plus, directiva worker_cpu_affinity a fost inclusă pentru a fixa fiecare proces de lucru la un CPU (fiecare 1 din al doilea parametru denotă un CPU din mașină).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Rezultatele performanței
Ca front-end al aplicației dumneavoastră, performanța proxy-ului invers este critică.
Am testat fiecare proxy invers (NGINX, HAProxy MP și HAProxy MT) la un număr din ce în ce mai mare de RPS până când unul dintre ele a atins 100% din utilizarea CPU. Toate trei au avut performanțe similare la nivelurile de RPS la care CPU nu a fost epuizat.
Atingerea unei utilizări CPU de 100% a avut loc mai întâi pentru HAProxy MT, la 85.000 RPS, iar în acel moment performanța s-a înrăutățit dramatic atât pentru HAProxy MT, cât și pentru HAProxy MP. Prezentăm aici distribuția percentilelor de latență a fiecărui proxy invers la acest nivel de încărcare. Graficul a fost trasat din ieșirea scriptului wrk folosind programul HdrHistogramă disponibil pe GitHub.
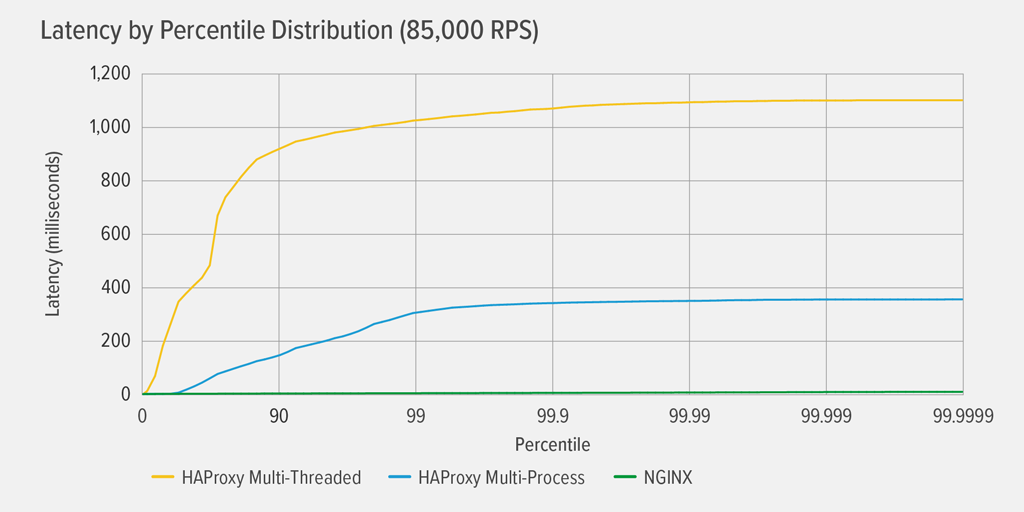
La 85.000 RPS, latența cu HAProxy MT urcă brusc până la percentila 90, apoi se stabilizează treptat la aproximativ 1100 de milisecunde (ms).
HAProxy MP se comportă mai bine decât HAProxy MT – latența urcă într-un ritm mai lent până la percentila 99, moment în care începe să se stabilizeze la aproximativ 400 ms. (Ca o confirmare a faptului că HAProxy MP este mai eficient, am observat că HAProxy MT a utilizat puțin mai mult CPU decât HAProxy MP la fiecare nivel RPS.)
NGINX nu suferă practic nicio latență la nicio percentilă. Cea mai mare latență pe care un număr semnificativ de utilizatori ar putea să o experimenteze (la percentila 99,9999) este de aproximativ 8ms.
Ce ne spun aceste rezultate despre experiența utilizatorilor? După cum s-a menționat în introducere, metrica care contează cu adevărat este timpul de răspuns din perspectiva utilizatorului final, și nu timpul de serviciu al sistemului testat.
Este o concepție greșită comună că latența mediană dintr-o distribuție reprezintă cel mai bine experiența utilizatorului. De fapt, mediana este numărul față de care aproximativ jumătate din timpii de răspuns sunt mai slabi! Utilizatorii emit de obicei multe cereri și accesează multe resurse la fiecare încărcare a paginii, astfel încât mai multe dintre cererile lor sunt obligate să înregistreze latențe la percentilele superioare din grafic (de la 99 la 99,9999). Deoarece utilizatorii sunt atât de intoleranți față de performanțele slabe, latențele de la percentilele superioare sunt cele pe care este cel mai probabil să le observe.
Gândiți-vă în felul următor: experiența dvs. de verificare la un magazin alimentar este determinată de timpul necesar pentru a ieși din magazin din momentul în care v-ați așezat la coadă la casă, nu doar de timpul necesar pentru ca casierul să vă înregistreze articolele. Dacă, de exemplu, un client din fața dvs. contestă prețul unui articol și casierul trebuie să cheme pe cineva să verifice acest lucru, timpul total de plată este mult mai lung decât de obicei.
Pentru a ține cont de acest lucru în rezultatele noastre privind latența, trebuie să corectăm pentru ceva numit omisiune coordonată, în care (așa cum se explică într-o notă de la sfârșitul wrk2 README) „răspunsurile cu latență mare au ca rezultat faptul că generatorul de sarcină se coordonează cu serverul pentru a evita măsurarea în timpul perioadelor de latență mare”. Din fericire, wrk2 corectează în mod implicit omisiunea coordonată (pentru mai multe detalii despre omisiunea coordonată, consultați README).
Când HAProxy MT epuizează CPU la 85.000 RPS, multe cereri înregistrează o latență ridicată. Acestea sunt incluse în mod corect în date, deoarece corectăm omisiunea coordonată. Este nevoie doar de una sau două cereri cu latență ridicată pentru a întârzia încărcarea unei pagini și a determina percepția unei performanțe slabe. Având în vedere că un sistem real deservește mai mulți utilizatori în același timp, chiar dacă doar 1% dintre cereri au latență ridicată (valoarea de la percentila 99), o mare parte dintre utilizatori sunt potențial afectați.
Concluzie
Unul dintre punctele principale ale analizei comparative a performanței este de a determina dacă aplicația dvs. este suficient de receptivă pentru a satisface utilizatorii și a-i face să revină.
Atât NGINX cât și HAProxy sunt bazate pe software și au arhitecturi bazate pe evenimente. În timp ce HAProxy MP oferă performanțe mai bune decât HAProxy MT, lipsa partajării stării între procese face ca managementul să fie mai complex, așa cum am detaliat în HAProxy: Configurație și versiuni. HAProxy MT abordează aceste limitări, dar în detrimentul unei performanțe mai scăzute, așa cum se demonstrează în rezultate.
Cu NGINX, nu există compromisuri – deoarece procesele împart starea, nu este nevoie de un mod multi-threading. Obțineți performanța superioară a multiprocesării fără limitările care fac ca HAProxy să descurajeze utilizarea sa.
.