NGINX en HAProxy: Testing User Experience in the Cloud
Veel prestatiebenchmarks meten piekdoorvoer of verzoeken per seconde (RPS), maar deze cijfers kunnen het prestatieverhaal op echte sites te simplificeren. Weinig organisaties draaien hun diensten op of rond de piek doorvoer, waar een 10% verandering in de prestaties van beide kanten een significant verschil kan maken. De verwerkingscapaciteit of RPS die een site nodig heeft is niet oneindig, maar wordt bepaald door externe factoren zoals het aantal gelijktijdige gebruikers dat ze moeten bedienen en het activiteitsniveau van elke gebruiker. Wat uiteindelijk het belangrijkste is, is dat uw gebruikers het beste serviceniveau krijgen. Het maakt eindgebruikers niet uit hoeveel andere mensen uw site bezoeken. Ze geven alleen om de service die ze krijgen en excuseren geen slechte performance omdat het systeem overbelast is.
Dit leidt ons tot de observatie dat het belangrijkste is dat een organisatie consistente, low-latency performance levert aan al hun gebruikers, zelfs onder hoge belasting. Bij het vergelijken van NGINX en HAProxy die draaien op Amazon Elastic Compute Cloud (EC2) als reverse proxies, wilden we twee dingen doen:
- Bepalen welk niveau van belasting elke proxy comfortabel aankan
- Verzamel de latency percentile distributie, waarvan we vinden dat het de metric is die het meest direct gecorreleerd is met gebruikerservaring
Testprotocollen en verzamelde metrics
We gebruikten het load-generatie programma wrk2 om een client na te bootsen, die continu verzoeken via HTTPS deed gedurende een gedefinieerde periode. Het geteste systeem – HAProxy of NGINX – fungeerde als een reverse proxy, maakte versleutelde verbindingen met de door wrk gesimuleerde clienten, stuurde verzoeken door naar een backend webserver met NGINX Plus R22, en stuurde het antwoord van de webserver (een bestand) terug naar de client.
Elk van de drie componenten (client, reverse proxy, en webserver) draaide Ubuntu 20.04.1 LTS op een c5n.2xlarge Amazon Machine Image (AMI) in EC2.
Zoals vermeld, verzamelden we de volledige latency percentiel verdeling van elke test run. Latency wordt gedefinieerd als de hoeveelheid tijd tussen het genereren van het verzoek door de client en het ontvangen van het antwoord. Een latentie percentiel verdeling sorteert de latentie metingen verzameld tijdens de test periode van hoogste (meeste latentie) naar laagste.
Test Methodologie
Client
Met behulp van wrk2 (versie 4.0.0), draaiden we het volgende script op de Amazon EC2 instance:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Om veel clients te simuleren die een webapplicatie benaderen, werden 4 wrk threads gespawned die samen 100 verbindingen tot stand brachten met de reverse proxy. Gedurende de 30-seconden test run, genereerde het script een gespecificeerd aantal RPS. Deze parameters komen overeen met de volgende wrk2 opties:
-
‑toptie – Aantal threads om aan te maken (4) -
‑coptie – Aantal TCP verbindingen om aan te maken (100) -
‑doptie – Aantal seconden in de test periode (30 seconden) -
‑Roptie – Aantal RPS uitgegeven door de client -
‑‑latencyoptie – Output bevat gecorrigeerde latentie percentiel informatie
We verhoogden het aantal RPS stapsgewijs over de set van test runs totdat een van de proxies 100% CPU gebruik bereikte. Voor verdere discussie, zie Prestatie resultaten.
Alle verbindingen tussen client en proxy werden gemaakt over HTTPS met TLSv1.3. We gebruikten ECC met een 256-bit sleutelgrootte, Perfect Forward Secrecy, en de TLS_AES_256_GCM_SHA384 cipher suite. (Omdat TLSv1.2 nog steeds veel gebruikt wordt op het Internet, hebben we de tests daarmee ook opnieuw uitgevoerd; de resultaten waren zo gelijk aan die voor TLSv1.3 dat we ze hier niet opnemen.)
HAProxy: Configuration and Versioning
We hebben HAProxy versie 2.3 (stable) als reverse proxy ingesteld.
Het aantal gelijktijdige gebruikers op een populaire website kan enorm zijn. Om dit grote verkeersvolume aan te kunnen, moet uw reverse proxy schaalbaar zijn en gebruik kunnen maken van meerdere cores. Er zijn twee basis manieren om te schalen: multi-processing en multi-threading. Zowel NGINX als HAProxy ondersteunen multi-processing, maar er is een belangrijk verschil – in HAProxy’s implementatie delen processen geen geheugen (terwijl ze dat in NGINX wel doen). Het onvermogen om state te delen tussen processen heeft verschillende consequenties voor HAProxy:
- Configuratie parameters – inclusief limieten, statistieken, en snelheden – moeten apart worden gedefinieerd voor elk proces.
- Performance metrieken worden verzameld per proces; het combineren ervan vereist aanvullende config, die behoorlijk complex kan zijn.
- Elk proces behandelt health checks afzonderlijk, dus doelservers worden per proces onderzocht in plaats van per server zoals verwacht.
- Session persistence is niet mogelijk.
- Een dynamische configuratiewijziging gemaakt via de HAProxy Runtime API geldt voor een enkel proces, dus u moet de API-aanroep voor elk proces herhalen.
Omwille van deze problemen raadt HAProxy het gebruik van zijn multi-processing implementatie ten zeerste af. Om direct uit de configuratiehandleiding van HAProxy te citeren:
MULTIJDPROCES GEBRUIKEN IS HARDER TE DEBUGGEN EN IS ECHT AFGEADRUKT.
HAProxy introduceerde multi-threading in versie 1.8 als een alternatief voor multi-processing. Multi-threading lost meestal het state-sharing probleem op, maar zoals we bespreken in Performance Results, presteert HAProxy in multi-thread mode niet zo goed als in multi-process mode.
Onze HAProxy configuratie bevatte voorzieningen voor zowel multi-thread mode (HAProxy MT) als multi-process mode (HAProxy MP). Om tijdens het testen op elk RPS-niveau tussen de modi te wisselen, hebben we de betreffende regels gecommentarieerd en gedecommentarieerd en HAProxy opnieuw gestart zodat de configuratie van kracht werd:
$ sudo service haproxy restartHier ziet u de configuratie met HAProxy MT provisioned: vier threads worden aangemaakt onder één proces en elke thread wordt vastgepind op een CPU. Voor HAProxy MP (hier uitgecommentarieerd), zijn er vier processen elk vastgepind op een CPU.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Configuratie en Versioning
We hebben NGINX Open Source versie 1.18.0 ingezet als reverse proxy.
Om alle cores te gebruiken die op de machine beschikbaar zijn (vier in dit geval), hebben we de auto parameter toegevoegd aan de worker_processes directive, wat ook de instelling is in het standaard nginx.conf bestand dat vanuit onze repository wordt gedistribueerd. Bovendien werd de worker_cpu_affinity directive toegevoegd om elk werkproces vast te pinnen op een CPU (elke 1 in de tweede parameter duidt op een CPU in de machine).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Prestatie resultaten
Als de front end van je applicatie, is de prestatie van je reverse proxy kritisch.
We hebben elke reverse proxy (NGINX, HAProxy MP, en HAProxy MT) getest op een toenemend aantal RPS totdat een van hen 100% CPU gebruik bereikte. Alle drie presteerden vergelijkbaar op de RPS niveaus waar CPU niet uitgeput was.
Het bereiken van 100% CPU-gebruik deed zich het eerst voor bij HAProxy MT, bij 85.000 RPS, en op dat punt verslechterden de prestaties dramatisch voor zowel HAProxy MT als HAProxy MP. Hier presenteren we de latency percentiel verdeling van elke reverse proxy op dat belastingsniveau. De grafiek is geplot op basis van de uitvoer van het wrk-script met behulp van het HdrHistogram-programma dat beschikbaar is op GitHub.
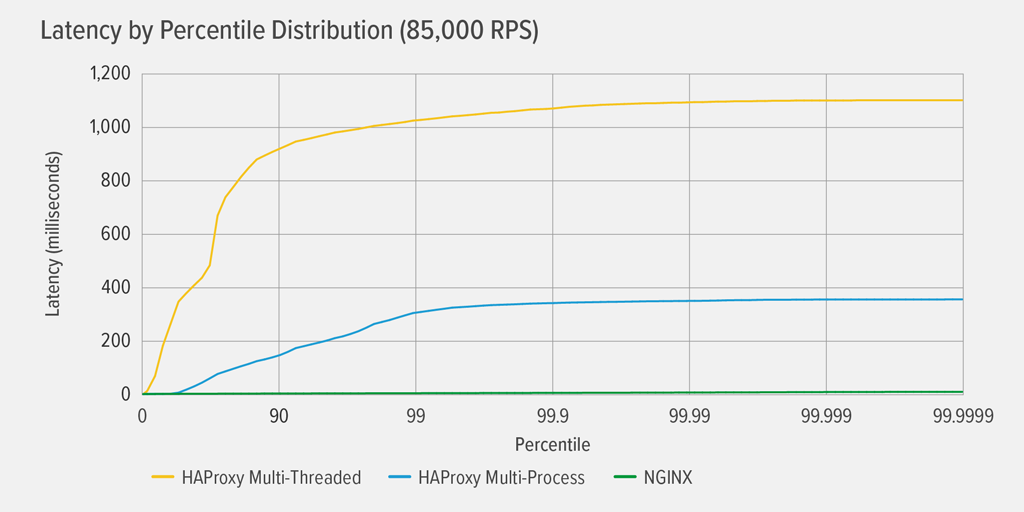
Bij 85.000 RPS stijgt de latentie met HAProxy MT abrupt tot het 90e percentiel, en vlakt dan geleidelijk af bij ongeveer 1100 milliseconden (ms).
HAProxy MP presteert beter dan HAProxy MT – de latency stijgt langzamer tot het 99e percentiel, en vlakt dan af bij ruwweg 400 ms. (Ter bevestiging dat HAProxy MP efficiënter is, zagen we dat HAProxy MT iets meer CPU gebruikte dan HAProxy MP op elk RPS-niveau.)
NGINX heeft vrijwel geen latency bij elk percentiel. De hoogste latency die een significant aantal gebruikers zou kunnen ervaren (bij het 99,9999e percentiel) is ruwweg 8ms.
Wat vertellen deze resultaten ons over de gebruikerservaring? Zoals in de inleiding al is gezegd, is de responstijd vanuit het perspectief van de eindgebruiker het belangrijkst, en niet de servicetijd van het geteste systeem.
Het is een veel voorkomende misvatting dat de mediane latentie in een verdeling het beste de gebruikerservaring weergeeft. In feite is de mediaan het getal waar ongeveer de helft van de responstijden slechter dan is! Gebruikers doen doorgaans veel verzoeken en raadplegen veel bronnen per geladen pagina, dus verschillende van hun verzoeken zullen zeker vertragingen vertonen bij de bovenste percentielen in de grafiek (99e tot 99,9999e). Omdat gebruikers zo intolerant zijn voor slechte prestaties, zijn latenties bij de hoge percentielen degenen die ze het meest waarschijnlijk zullen opmerken.
Bedenk het zo: uw ervaring met afrekenen bij een kruidenier wordt bepaald door hoe lang het duurt om de winkel te verlaten vanaf het moment dat u in de rij voor de kassa bent gaan staan, niet alleen door hoe lang het duurde voordat de kassière uw artikelen had afgerekend. Als bijvoorbeeld een klant voor u de prijs van een artikel betwist en de kassière moet iemand halen om het te verifiëren, is uw totale kassatijd veel langer dan normaal.
Om dit mee te nemen in onze latency resultaten, moeten we corrigeren voor iets dat gecoördineerde omissie wordt genoemd, waarbij (zoals uitgelegd in een noot aan het eind van de wrk2 README) “hoge latency reacties resulteren in de load generator die coördineert met de server om metingen te vermijden tijdens periodes met hoge latency”. Gelukkig corrigeert wrk2 standaard voor gecoördineerde weglating (voor meer details over gecoördineerde weglating, zie de README).
Wanneer HAProxy MT de CPU uitput bij 85.000 RPS, ervaren veel verzoeken een hoge latency. Ze zijn terecht opgenomen in de gegevens omdat we corrigeren voor gecoördineerde omissie. Er zijn slechts één of twee verzoeken met een hoge latentie nodig om het laden van een pagina te vertragen en de indruk te wekken dat de prestaties slecht zijn. Aangezien een echt systeem meerdere gebruikers tegelijk bedient, zelfs als slechts 1% van de verzoeken een hoge latency heeft (de waarde bij het 99e percentiel), wordt een groot deel van de gebruikers mogelijk beïnvloed.
Conclusie
Een van de belangrijkste punten van prestatiebenchmarking is bepalen of uw app responsief genoeg is om gebruikers tevreden te stellen en ervoor te zorgen dat ze blijven terugkomen.
Zowel NGINX als HAProxy zijn op software gebaseerd en hebben een event-driven architectuur. Hoewel HAProxy MP betere prestaties levert dan HAProxy MT, maakt het gebrek aan state sharing tussen de processen het beheer complexer, zoals we hebben beschreven in HAProxy: Configuration and Versioning. HAProxy MT adresseert deze beperkingen, maar ten koste van lagere prestaties, zoals blijkt uit de resultaten.
Met NGINX, zijn er geen tradeoffs – omdat processen state delen, is er geen noodzaak voor een multi-threading mode. U krijgt de superieure prestaties van multi-processing zonder de beperkingen die HAProxy het gebruik ervan ontmoedigen.