NGINX und HAProxy: Testen der Benutzerfreundlichkeit in der Cloud
Viele Leistungsbenchmarks messen den Spitzendurchsatz oder die Anfragen pro Sekunde (RPS), aber diese Metriken können die Leistung an realen Standorten zu stark vereinfachen. Nur wenige Unternehmen betreiben ihre Dienste bei oder nahe dem Spitzendurchsatz, bei dem eine Leistungsänderung von 10 % in beide Richtungen einen erheblichen Unterschied ausmachen kann. Der Durchsatz oder RPS, den ein Standort benötigt, ist nicht unbegrenzt, sondern wird durch externe Faktoren wie die Anzahl der gleichzeitig zu bedienenden Benutzer und das Aktivitätsniveau der einzelnen Benutzer bestimmt. Letztendlich kommt es darauf an, dass Ihre Nutzer den bestmöglichen Service erhalten. Den Endnutzern ist es egal, wie viele andere Personen Ihre Website besuchen. Sie interessieren sich nur für den Service, den sie erhalten, und entschuldigen eine schlechte Leistung nicht damit, dass das System überlastet ist.
Dies führt uns zu der Feststellung, dass es vor allem darauf ankommt, dass ein Unternehmen allen Benutzern eine konsistente Leistung mit geringer Latenzzeit bietet, selbst bei hoher Last. Beim Vergleich von NGINX und HAProxy, die auf Amazon Elastic Compute Cloud (EC2) als Reverse Proxies laufen, haben wir uns zwei Dinge vorgenommen:
- Bestimmen, welche Last jeder Proxy bequem bewältigen kann
- Erfassen der Latenz-Perzentil-Verteilung, die unserer Meinung nach die Metrik ist, die am direktesten mit der Benutzererfahrung korreliert
Testprotokolle und erfasste Metriken
Wir verwendeten das Lastgenerierungsprogramm wrk2, um einen Client zu emulieren, der während eines bestimmten Zeitraums kontinuierliche Anfragen über HTTPS stellt. Das getestete System – HAProxy oder NGINX – fungierte als Reverse-Proxy, der verschlüsselte Verbindungen mit den von wrk-Threads simulierten Clients herstellte, die Anfragen an einen Backend-Webserver mit NGINX Plus R22 weiterleitete und die vom Webserver generierte Antwort (eine Datei) an den Client zurückgab.
Jede der drei Komponenten (Client, Reverse Proxy und Webserver) lief unter Ubuntu 20.04.1 LTS auf einem c5n.2xlarge Amazon Machine Image (AMI) in EC2.
Wie bereits erwähnt, haben wir die vollständige Latenz-Perzentil-Verteilung von jedem Testlauf gesammelt. Die Latenz ist definiert als die Zeitspanne zwischen der Erstellung der Anfrage durch den Client und dem Erhalt der Antwort. Eine Latenz-Perzentil-Verteilung sortiert die während des Testzeitraums erfassten Latenzmessungen vom höchsten (höchste Latenz) zum niedrigsten Wert.
Testmethodik
Client
Unter Verwendung von wrk2 (Version 4.0.0) haben wir das folgende Skript auf der Amazon EC2-Instanz ausgeführt:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Um zu simulieren, dass viele Clients auf eine Webanwendung zugreifen, wurden 4 wrk Threads erzeugt, die zusammen 100 Verbindungen zum Reverse-Proxy aufbauten. Während des 30-sekündigen Testlaufs erzeugte das Skript eine bestimmte Anzahl von RPS. Diese Parameter entsprechen den folgenden wrk2 Optionen:
-
‑tOption – Anzahl der zu erstellenden Threads (4) -
‑cOption – Anzahl der zu erstellenden TCP-Verbindungen (100) -
‑dOption – Anzahl der Sekunden im Testzeitraum (30 Sekunden) -
‑ROption – Anzahl der RPS, die vom Client ausgegeben wurden. Anzahl der vom Client ausgegebenen RPS -
‑‑latencyOption – Die Ausgabe enthält korrigierte Latenzperzentil-Informationen
Wir haben die Anzahl der RPS über die Testläufe hinweg schrittweise erhöht, bis einer der Proxys eine CPU-Auslastung von 100 % erreichte. Weitere Informationen finden Sie unter Leistungsergebnisse.
Alle Verbindungen zwischen Client und Proxy wurden über HTTPS mit TLSv1.3 hergestellt. Wir haben ECC mit einer Schlüsselgröße von 256 Bit, Perfect Forward Secrecy und die TLS_AES_256_GCM_SHA384 Cipher Suite verwendet. (Da TLSv1.2 im Internet immer noch häufig verwendet wird, haben wir die Tests auch damit durchgeführt; die Ergebnisse waren denen für TLSv1.3 so ähnlich, dass wir sie hier nicht aufführen: Konfiguration und Versionierung
Wir haben HAProxy Version 2.3 (stable) als Reverse-Proxy bereitgestellt.
Die Anzahl der gleichzeitigen Benutzer einer beliebten Website kann enorm sein. Um das große Verkehrsaufkommen zu bewältigen, muss Ihr Reverse-Proxy skalierbar sein, um die Vorteile mehrerer Kerne nutzen zu können. Es gibt zwei grundlegende Möglichkeiten der Skalierung: Multiprocessing und Multi-Threading. Sowohl NGINX als auch HAProxy unterstützen Multiprocessing, aber es gibt einen wichtigen Unterschied: In der HAProxy-Implementierung teilen sich die Prozesse keinen Speicher (während sie dies in NGINX tun). Die Unfähigkeit, den Status zwischen Prozessen zu teilen, hat mehrere Konsequenzen für HAProxy:
- Konfigurationsparameter – einschließlich Limits, Statistiken und Raten – müssen für jeden Prozess separat definiert werden.
- Leistungsmetriken werden pro Prozess gesammelt; ihre Kombination erfordert eine zusätzliche Konfiguration, die ziemlich komplex sein kann.
- Jeder Prozess handhabt Gesundheitsprüfungen separat, so dass Zielserver pro Prozess und nicht wie erwartet pro Server geprüft werden.
- Sitzungspersistenz ist nicht möglich.
- Eine dynamische Konfigurationsänderung, die über die HAProxy Runtime API vorgenommen wird, gilt für einen einzelnen Prozess, so dass Sie den API-Aufruf für jeden Prozess wiederholen müssen.
Aufgrund dieser Probleme rät HAProxy dringend von der Verwendung seiner Multiprozess-Implementierung ab. Um direkt aus dem HAProxy-Konfigurationshandbuch zu zitieren:
BENUTZUNG MEHRERER PROZESSE IST SCHWIERIGER ZU DEBUGEN UND WIRKLICH ABGERATEN.
HAProxy führte Multi-Threading in Version 1.8 als Alternative zu Multi-Processing ein. Multi-Threading löst größtenteils das State-Sharing-Problem, aber wie wir in den Leistungsergebnissen diskutieren, ist HAProxy im Multi-Threading-Modus nicht so leistungsfähig wie im Multi-Prozess-Modus.
Unsere HAProxy-Konfiguration umfasste die Bereitstellung sowohl für den Multi-Thread-Modus (HAProxy MT) als auch für den Multiprozess-Modus (HAProxy MP). Um während der Tests auf jeder RPS-Ebene zwischen den Modi zu wechseln, haben wir die entsprechenden Zeilen auskommentiert und wieder auskommentiert und HAProxy neu gestartet, damit die Konfiguration wirksam wird:
$ sudo service haproxy restartHier ist die Konfiguration mit HAProxy MT: vier Threads werden unter einem Prozess erstellt und jeder Thread wird an eine CPU angeheftet. Für HAProxy MP (hier auskommentiert) gibt es vier Prozesse, die jeweils an eine CPU gebunden sind.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Konfiguration und Versionierung
Wir haben NGINX Open Source Version 1.18.0 als Reverse-Proxy eingesetzt.
Um alle auf dem Rechner verfügbaren Kerne zu nutzen (in diesem Fall vier), haben wir den Parameter auto in die worker_processes-Direktive aufgenommen, was auch die Einstellung in der Standarddatei nginx.conf ist, die aus unserem Repository stammt. Zusätzlich wurde die Direktive worker_cpu_affinity eingefügt, um jeden Worker-Prozess an eine CPU zu binden (jedes 1 im zweiten Parameter bezeichnet eine CPU in der Maschine).
user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Leistungsergebnisse
Als Front-End Ihrer Anwendung ist die Leistung Ihres Reverse-Proxys entscheidend.
Wir testeten jeden Reverse-Proxy (NGINX, HAProxy MP und HAProxy MT) mit einer zunehmenden Anzahl von RPS, bis einer von ihnen 100 % CPU-Auslastung erreichte. Alle drei erbrachten ähnliche Leistungen bei den RPS-Levels, bei denen die CPU nicht erschöpft war.
Das Erreichen von 100 % CPU-Auslastung trat zuerst für HAProxy MT bei 85.000 RPS auf, und an diesem Punkt verschlechterte sich die Leistung sowohl für HAProxy MT als auch für HAProxy MP dramatisch. Hier stellen wir die Latenz-Perzentil-Verteilung jedes Reverse-Proxys bei dieser Auslastung dar. Das Diagramm wurde aus der Ausgabe des Skripts wrk mithilfe des auf GitHub verfügbaren Programms HdrHistogram erstellt.
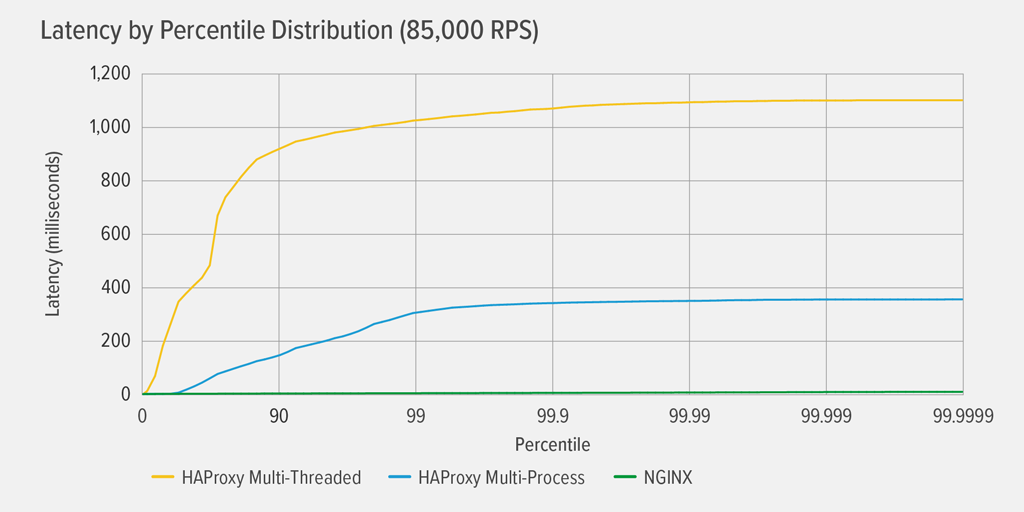
Bei 85.000 RPS steigt die Latenz mit HAProxy MT abrupt bis zum 90. Perzentil an und pendelt sich dann allmählich bei etwa 1100 Millisekunden (ms) ein.
HAProxy MP schneidet besser ab als HAProxy MT – die Latenz steigt langsamer bis zum 99. Perzentil an und pendelt sich dann bei etwa 400 ms ein. (Als Bestätigung dafür, dass HAProxy MP effizienter ist, haben wir beobachtet, dass HAProxy MT auf jeder RPS-Stufe etwas mehr CPU verbraucht als HAProxy MP.)
NGINX hat praktisch bei keinem Perzentil eine Latenz. Die höchste Latenz, die eine signifikante Anzahl von Benutzern erfahren könnte (am 99,9999sten Perzentil), beträgt etwa 8 ms.
Was sagen uns diese Ergebnisse über die Nutzererfahrung? Wie in der Einleitung erwähnt, ist die Antwortzeit aus der Sicht des Endbenutzers die wirklich wichtige Kennzahl und nicht die Servicezeit des getesteten Systems.
Es ist ein weit verbreiteter Irrglaube, dass der Median der Latenzzeit in einer Verteilung die Benutzererfahrung am besten wiedergibt. Tatsächlich ist der Median die Zahl, unter der etwa die Hälfte der Antwortzeiten liegt! Benutzer stellen in der Regel viele Anfragen und greifen auf viele Ressourcen pro Seitenladevorgang zu, so dass einige ihrer Anfragen zwangsläufig Latenzzeiten an den oberen Perzentilen im Diagramm (99. bis 99,9999.) aufweisen. Da die Benutzer so intolerant gegenüber schlechter Leistung sind, werden sie Latenzen an den hohen Perzentilen am ehesten bemerken.
Stellen Sie sich das so vor: Ihre Erfahrung beim Bezahlen in einem Lebensmittelgeschäft wird dadurch bestimmt, wie lange es dauert, das Geschäft zu verlassen, nachdem Sie sich in die Kassenschlange eingereiht haben, und nicht nur dadurch, wie lange es dauert, bis die Kassiererin Ihre Artikel einträgt. Wenn z. B. ein Kunde vor Ihnen den Preis eines Artikels bestreitet und die Kassiererin jemanden holen muss, um ihn zu überprüfen, ist Ihre Gesamtzeit an der Kasse viel länger als gewöhnlich.
Um dies in unseren Latenz-Ergebnissen zu berücksichtigen, müssen wir etwas korrigieren, das als koordinierte Auslassung bezeichnet wird, bei der (wie in einer Anmerkung am Ende der wrk2 README erklärt) „hohe Latenz-Antworten dazu führen, dass der Lastgenerator sich mit dem Server koordiniert, um Messungen während hoher Latenzzeiten zu vermeiden“. Glücklicherweise korrigiert wrk2 das koordinierte Auslassen standardmäßig (weitere Einzelheiten über koordiniertes Auslassen finden Sie in der README).
Wenn HAProxy MT die CPU mit 85.000 RPS auslastet, haben viele Anfragen eine hohe Latenz. Sie sind zu Recht in den Daten enthalten, denn wir korrigieren die koordinierte Auslassung. Es braucht nur ein oder zwei Anfragen mit hoher Latenz, um das Laden einer Seite zu verzögern und den Eindruck einer schlechten Leistung zu erwecken. Wenn man bedenkt, dass ein reales System mehrere Benutzer gleichzeitig bedient, ist selbst dann, wenn nur 1 % der Anfragen eine hohe Latenz aufweisen (der Wert am 99. Perzentil), ein großer Teil der Benutzer potenziell betroffen.
Schlussfolgerung
Einer der wichtigsten Punkte beim Leistungs-Benchmarking ist die Feststellung, ob Ihre Anwendung reaktionsschnell genug ist, um die Benutzer zufrieden zu stellen und sie zum Wiederkommen zu bewegen.
Bei NGINX und HAProxy handelt es sich um softwarebasierte, ereignisgesteuerte Architekturen. HAProxy MP bietet zwar eine bessere Leistung als HAProxy MT, aber die fehlende gemeinsame Nutzung von Zuständen zwischen den Prozessen macht die Verwaltung komplexer, wie wir in HAProxy beschrieben haben: Konfiguration und Versionierung. HAProxy MT behebt diese Einschränkungen, allerdings auf Kosten einer geringeren Leistung, wie die Ergebnisse zeigen.
Mit NGINX gibt es keine Kompromisse – da die Prozesse den Status gemeinsam nutzen, ist ein Multi-Threading-Modus nicht erforderlich. Sie erhalten die überragende Leistung von Multiprocessing ohne die Einschränkungen, die HAProxy von seiner Verwendung abhalten.