NGINX and HAProxy: クラウドでのユーザー エクスペリエンスをテストする
多くのパフォーマンス ベンチマークはピーク スループットまたはリクエスト/秒 (RPS) を測定しますが、これらのメトリックは現実のサイトでのパフォーマンスの話を過度に単純化する可能性があります。 ピーク スループットまたはそれに近い状態でサービスを実行する組織はほとんどなく、パフォーマンスが 10% 変化するだけで、大きな違いになる可能性があります。 サイトが必要とするスループットまたはRPSは無限ではなく、サービスを提供しなければならない同時実行ユーザー数や各ユーザーのアクティビティレベルなどの外部要因によって固定されます。 結局のところ、最も重要なのは、ユーザーが最高のレベルのサービスを受けることです。 エンドユーザーは、他のユーザーが何人あなたのサイトを訪れているかなんて気にしません。 このことから、最も重要なことは、組織が、高負荷下でも、すべてのユーザーに一貫した低遅延のパフォーマンスを提供することであるという見解に至ります。 リバース プロキシとして Amazon Elastic Compute Cloud (EC2) 上で動作する NGINX と HAProxy を比較するにあたり、私たちは 2 つのことを行うことにしました。
- 各プロキシが快適に処理できる負荷のレベルを決定すること
- ユーザー体験に最も直接関連するメトリックである待ち時間パーセンタイル分布を集めること
テスト プロトコルと収集したメトリック
負荷発生プログラム wrk2 を使用して、クライアントを模倣し、定められた期間に HTTPS で継続的にリクエストを行いました。 テスト対象のシステム (HAProxy または NGINX) はリバース プロキシとして動作し、wrk スレッドによってシミュレートされたクライアントと暗号化された接続を確立し、NGINX Plus R22 を実行しているバックエンド Web サーバーにリクエストを転送し、Web サーバーが生成した応答(ファイル)をクライアントに返送しました。
3 つのコンポーネント (クライアント、リバース プロキシ、および Web サーバー) のそれぞれは、EC2 の c5n.2xlarge Amazon Machine Image (AMI) 上の Ubuntu 20.04.1 LTS を実行しました。
前述のように、各テスト実行から遅延パーセンティルの全分布を収集しました。 レイテンシとは、クライアントがリクエストを生成してからレスポンスを受け取るまでの時間として定義されます。 遅延のパーセンタイル分布は、テスト期間中に収集した遅延の測定値を最高 (最も遅延が大きい) から最低にソートします。
テスト方法
Client
wrk2 (バージョン 4.0.0) を使用し、Amazon EC2 インスタンスで次のスクリプトを実行します。
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/Web アプリケーションにアクセスする多数のクライアントをシミュレートするために、4 つの wrk スレッドが生成され、一緒にリバースプロキシへの 100 の接続が確立されました。 30秒間のテスト実行中に、スクリプトは指定された数のRPSを生成しました。 これらのパラメータは、次のwrk2オプションに対応しています。
-
‑tオプション – 作成するスレッド数 (4) -
‑cオプション – 作成するTCP接続数 (100) -
‑dオプション – テスト期間の秒数 (30 seconds) -
‑Rオプション – テスト期間の秒数 (30 seconds) -
‑‑latencyオプション – 出力には、補正されたレイテンシパーセンタイル情報 - 制限、統計、および速度を含む設定パラメーターは、各プロセスに対して個別に定義する必要があります。
- 各プロセスはヘルスチェックを個別に処理するため、ターゲットサーバーは期待されるサーバーごとではなく、プロセスごとにプローブされる。
- セッションの永続化は不可能。 HAProxy 設定マニュアルから直接引用すると、
USING MULTIPLE PROCESSES IS HARDER TO DEBUG AND IS REALLY DISCOURAGED.
HAProxy はバージョン 1.8 でマルチプロセスの代わりとしてマルチスレッドを取り入れました。 マルチスレッドは状態共有の問題をほとんど解決しますが、性能結果で説明するように、マルチスレッドモードでは HAProxy はマルチプロセスモードほど性能はよくありません。
私たちの HAProxy 構成には、マルチスレッド モード (HAProxy MT) とマルチプロセス モード (HAProxy MP) の両方のプロビジョニングが含まれています。 テスト中に各 RPS レベルでモードを交互に切り替えるために、適切な行のセットをコメント化およびコメント解除し、構成を有効にするために HAProxy を再起動しました:
$ sudo service haproxy restartこれは、HAProxy MT が設定された構成です:1 プロセス下に 4 つのスレッドが作成され、各スレッドは CPU に固定されています。 HAProxy MPの場合(ここでコメントアウト)、4つのプロセスがそれぞれCPUにPinされています。
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: 設定とバージョン管理
私たちは、NGINX Open Source バージョン 1.18.0 をリバース プロキシとして展開しました。
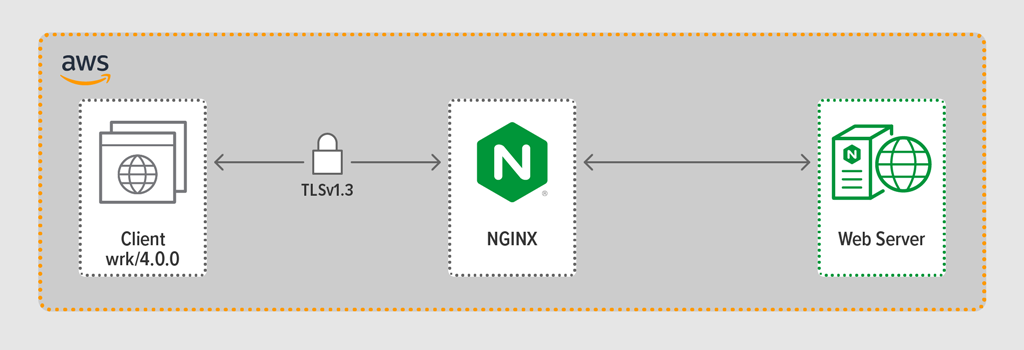
マシン上で利用できるすべてのコア(この場合は 4 コア)を使用するために、
worker_processesディレクティブにautoパラメータを組み込み、これはリポジトリから配信されるデフォルト nginx.conf ファイルでの設定も同じにしました。 さらに、各ワーカー プロセスを CPU に固定するためにworker_cpu_affinityディレクティブが含まれました (第 2 パラメータの各1は、マシン内の CPU を示します)。user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}パフォーマンス結果
アプリケーションのフロントエンドとして、リバースプロキシのパフォーマンスは重要です。
私たちは、RPS 数を上げて、いずれかのリバースプロキシ (NGINX, HAProxy MP, HAProxy MT) が 100% CPU 使用率となるまでテストしました。 3 つとも、CPU を使い果たさない RPS レベルで同様のパフォーマンスを発揮しました。
HAProxy MT で最初に 100% CPU 使用率に達したのは 85,000 RPS で、その時点で HAProxy MT と HAProxy MP の両方でパフォーマンスが劇的に悪化しました。 ここでは、その負荷レベルでの各リバースプロキシのレイテンシパーセンタイル分布を示しました。 このグラフは、GitHub で利用可能な HdrHistogram プログラムを使用して、
wrkスクリプトの出力からプロットされました。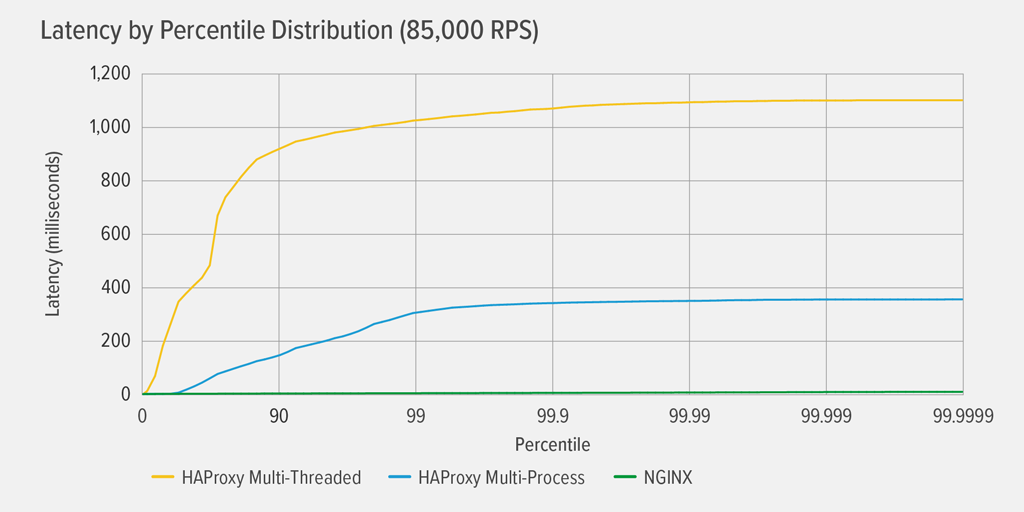
85,000 RPS で、HAProxy MT の待機時間は 90% まで急激に上昇し、約 1100 ミリセカンド (ms) で徐々に平準化されました。
HAProxy MP は HAProxy MT よりも良いパフォーマンスです。待ち時間は 99 パーセンタイルまでゆっくりと増加し、その時点で約 400ms で水平になり始めます (HAProxy MP がより効率的であるという確認として、すべての RPS レベルで、HAProxy MT が HAProxy MP よりわずかに多くの CPU を使用したという観測結果があります。)
NGINX にはどのパーセンタイルでも事実上の遅延がありません。 任意の重要な数のユーザーが経験する可能性のある最高の待ち時間 (99.9999 パーセントile) は、約 8 ミリ秒です。
これらの結果から、ユーザー エクスペリエンスについて何がわかるでしょうか。 冒頭で述べたように、本当に重要な測定基準は、エンドユーザーの視点からの応答時間であり、テスト対象のシステムのサービス時間ではありません。
分布の中央のレイテンシーがユーザー エクスペリエンスを最もよく表すというのは、よくある誤解です。 実際、中央値は、応答時間の約半分がそれより悪い数字です! ユーザーは通常、ページ読み込みごとに多くのリクエストを発行し、多くのリソースにアクセスするため、リクエストのいくつかは、グラフの上位百分位値 (99 ~ 99.9999 位) の遅延を経験することになります。
このように考えてください。食料品店でチェックアウトするときの経験は、レジの列に並んだ瞬間から店を出るまでにかかる時間によって決まりますが、レジ係が商品を鳴らすまでにかかった時間だけではありません。 例えば、あなたの前の客が商品の価格に異議を唱え、レジ係が誰かにそれを確認させなければならない場合、あなたの全体のチェックアウト時間は通常よりずっと長くなります。
遅延の結果にこれを考慮するには、(
wrk2README の末尾の注記にあるように) 「遅延の大きい応答は、負荷発生装置がサーバと協調して遅延の大きい期間の測定を避ける」調整省略と呼ばれるものを補正する必要があります。 幸運にもwrk2はデフォルトで調整された省略を修正します (調整された省略についての詳細は README を参照してください)。HAProxy MT が 85,000 RPS で CPU を消耗するとき、多くの要求は高いレイテンシを経験します。 調整漏れを補正しているため、それらはデータに正しく含まれています。 ページロードを遅延させ、パフォーマンスが悪いという印象を与えるには、1つか2つの高遅延の要求が必要なだけです。 実際のシステムが一度に複数のユーザーにサービスを提供していることを考えると、たとえリクエストの 1% に高い遅延 (99% の値) があったとしても、ユーザーの大部分は潜在的に影響を受けています。
NGINX と HAProxy の両方はソフトウェア ベースで、イベント駆動型アーキテクチャを採用しています。 HAProxy MP は HAProxy MT よりも優れたパフォーマンスを提供しますが、HAProxy で詳述したように、プロセス間の状態共有がないため、管理がより複雑になります。 コンフィギュレーションとバージョニング HAProxy MT はこれらの制限に対処しますが、結果に示されるように、低いパフォーマンスを犠牲にしています。
NGINX では、トレードオフはありません – プロセスは状態を共有するので、マルチスレッド モードは必要ありません。 プロセスが状態を共有するため、マルチスレッド モードは必要ありません。HAProxy がその使用を思いとどまらせるような制限なしに、マルチプロセシングの優れたパフォーマンスを得ることができます。
‑R オプション – テスト期間の秒数 (30 seconds)
‑t オプション – 作成するスレッド数 (4) – 作成するスレッド数 (4) – 作成するスレッド数 (100) クライアントが発行したRPSの数
プロキシのひとつが100%のCPU使用率を達成するまで、一連のテスト実行にわたってRPS数を段階的に増加させました。 詳細については、パフォーマンス結果を参照してください。
クライアントとプロキシ間のすべての接続は、TLSv1.3によるHTTPSで行われました。 256 ビットのキー サイズの ECC、Perfect Forward Secrecy、および TLS_AES_256_GCM_SHA384 暗号スイートを使用しました (TLSv1.2 はインターネット上でまだよく使用されているため、このテストも再実行しました。結果は TLSv1.3 のものと非常に似ていたのでここには掲載しませんでした。)
HAProxy: 構成とバージョン管理
HAProxy version 2.3 (stable) をリバース プロキシとしてプロビジョニングしました。
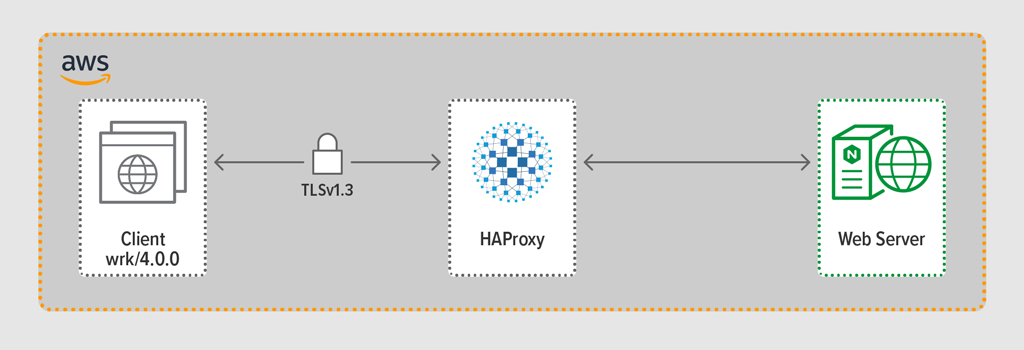
人気サイトの同時ユーザー数は膨大になることがあります。 大量のトラフィックを処理するために、リバース プロキシは複数のコアを利用できるよう拡張できる必要があります。 スケーリングには、マルチプロセシングとマルチスレッディングという 2 つの基本的な方法があります。 NGINX と HAProxy はどちらもマルチプロセッシングをサポートしていますが、重要な違いがあります。HAProxy の実装では、プロセスはメモリを共有しません (NGINX では共有します)。 プロセス間で状態を共有できないことは、HAProxy にいくつかの結果をもたらします。