Tutoriel sur les réseaux neuronaux convolutifs
L’intelligence artificielle a parcouru un long chemin et a comblé de manière transparente le fossé entre le potentiel des humains et des machines. Et les passionnés de données du monde entier travaillent sur de nombreux aspects de l’IA et transforment les visions en réalité – et l’un de ces domaines étonnants est celui de la vision par ordinateur. Ce domaine vise à permettre et à configurer les machines pour qu’elles voient le monde comme les humains, et à utiliser ces connaissances pour plusieurs tâches et processus (tels que la reconnaissance d’images, l’analyse et la classification d’images, etc.) Et les avancées dans la vision par ordinateur avec le Deep Learning ont connu un succès considérable, notamment avec l’algorithme du réseau neuronal convolutif.
Dans ce tutoriel, vous apprendrez :
- Introduction au CNN
- Qu’est-ce qu’un réseau neuronal convolutif ?
- Comment les CNN reconnaissent-ils les images ?
- Couches dans le CNN
- Mise en œuvre de cas d’utilisation utilisant le CNN
Introduction au CNN
Yann LeCun, directeur du groupe de recherche en IA de Facebook, est le pionnier des réseaux de neurones convolutifs. Il a construit le premier réseau de neurones convolutifs appelé LeNet en 1988. LeNet était utilisé pour des tâches de reconnaissance de caractères comme la lecture de codes postaux et de chiffres.
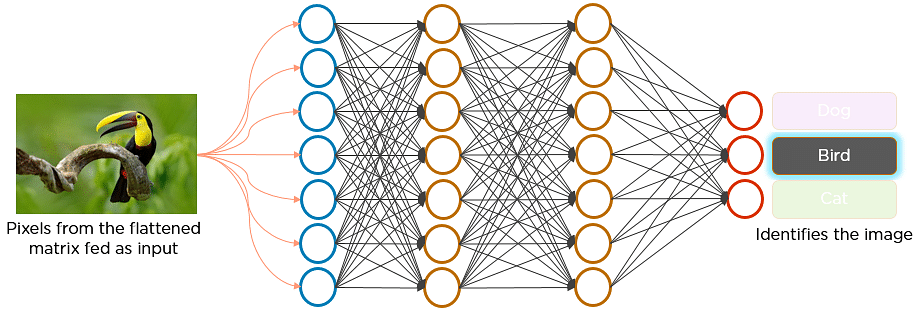
Vous êtes-vous déjà demandé comment fonctionne la reconnaissance faciale sur les médias sociaux, ou comment la détection d’objets aide à construire des voitures à conduite autonome, ou encore comment la détection des maladies se fait à l’aide d’images visuelles dans le domaine de la santé ? Tout cela est possible grâce aux réseaux de neurones convolutifs (CNN). Voici un exemple de réseaux de neurones convolutifs qui illustre leur fonctionnement :
Imaginez qu’il y a une image d’un oiseau, et que vous voulez identifier si c’est vraiment un oiseau ou un autre objet. La première chose que vous faites est d’alimenter les pixels de l’image sous forme de tableaux à la couche d’entrée du réseau neuronal (réseaux multicouches utilisés pour classer les choses). Les couches cachées effectuent l’extraction des caractéristiques en effectuant différents calculs et manipulations. Il existe plusieurs couches cachées, comme la couche de convolution, la couche ReLU et la couche de mise en commun, qui effectuent l’extraction de caractéristiques de l’image. Enfin, il y a une couche entièrement connectée qui identifie l’objet dans l’image.
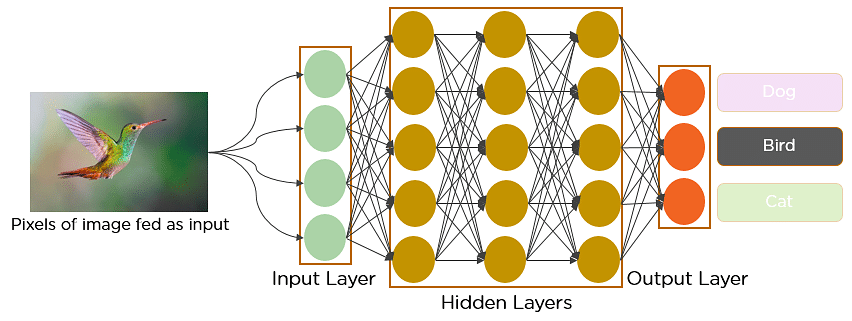
Fig : Réseau neuronal convolutif pour identifier l’image d’un oiseau
Cours d’apprentissage profond (avec TensorFlow & Keras)
Maîtriser les concepts et modèles d’apprentissage profondVoir cours
Qu’est-ce qu’un réseau neuronal convolutif ?
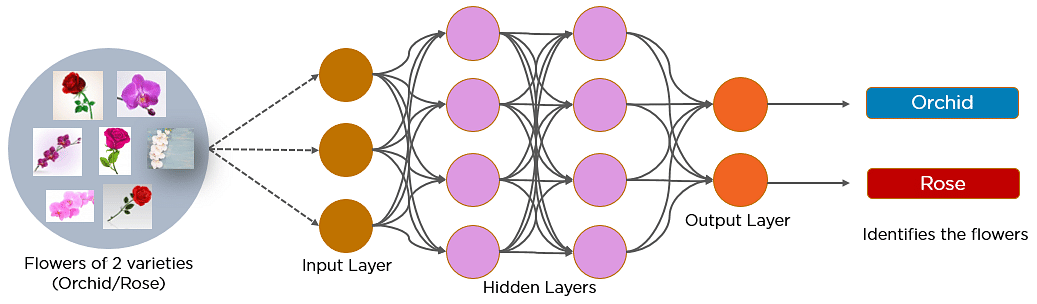
Un réseau de neurones convolutif est un réseau de neurones feed-forward qui est généralement utilisé pour analyser les images visuelles en traitant les données avec une topologie en forme de grille. Il est également connu sous le nom de ConvNet. Un réseau neuronal convolutif est utilisé pour détecter et classer des objets dans une image.
Vous trouverez ci-dessous un réseau neuronal qui identifie deux types de fleurs : Orchidée et Rose.
En CNN, chaque image est représentée sous la forme d’un tableau de valeurs de pixels.
![]()
L’opération de convolution constitue la base de tout réseau neuronal convolutif. Comprenons l’opération de convolution en utilisant deux matrices, a et b, de 1 dimension.
a =
b =
Dans l’opération de convolution, les matrices sont multipliées par éléments, et le produit est additionné pour créer une nouvelle matrice, qui représente a*b.
Les trois premiers éléments de la matrice a sont multipliés avec les éléments de la matrice b. Le produit est additionné pour obtenir le résultat.

Les trois éléments suivants de la matrice a sont multipliés par les éléments de la matrice b, et le produit est additionné.

Ce processus se poursuit jusqu’à ce que l’opération de convolution soit terminée.
Comment le CNN reconnaît-il les images ?
Considérez les images suivantes :
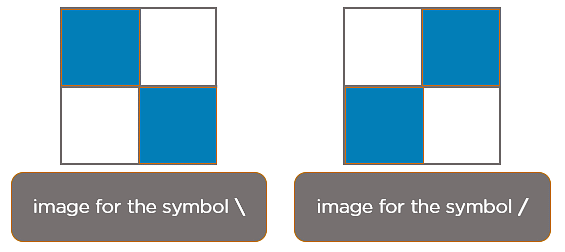
Les cases qui sont colorées représentent une valeur de pixel de 1, et 0 si elles ne sont pas colorées.
Lorsque vous appuyez sur la touche backslash (\), l’image ci-dessous est traitée.

Lorsque vous appuyez sur la barre oblique (/), l’image ci-dessous est traitée:

Voici un autre exemple pour décrire comment CNN reconnaît une image:
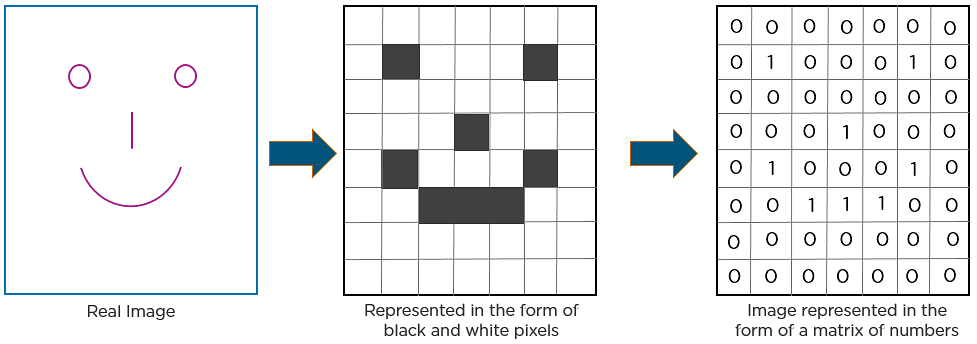
Comme vous pouvez le voir dans le diagramme ci-dessus, seules les valeurs sont allumées qui ont une valeur de 1.
Couches dans un réseau neuronal à convolution
Un réseau neuronal à convolution possède plusieurs couches cachées qui aident à extraire des informations d’une image. Les quatre couches importantes du CNN sont :
- Couche de convolution
- Couche ReLU
- Couche de pooling
- Couche entièrement connectée
Couche de convolution
C’est la première étape du processus d’extraction de caractéristiques précieuses d’une image. Une couche de convolution comporte plusieurs filtres qui effectuent l’opération de convolution. Chaque image est considérée comme une matrice de valeurs de pixels.
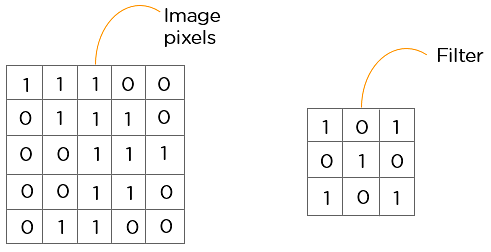
Considérez l’image 5×5 suivante dont les valeurs de pixels sont soit 0 soit 1. Il y a aussi une matrice de filtre avec une dimension de 3×3. Faites glisser la matrice de filtre sur l’image et calculez le produit scalaire pour obtenir la matrice de caractéristiques convoluée.

Couche ReLU
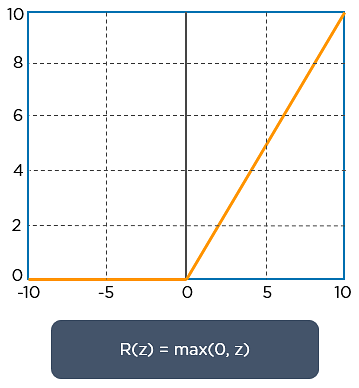
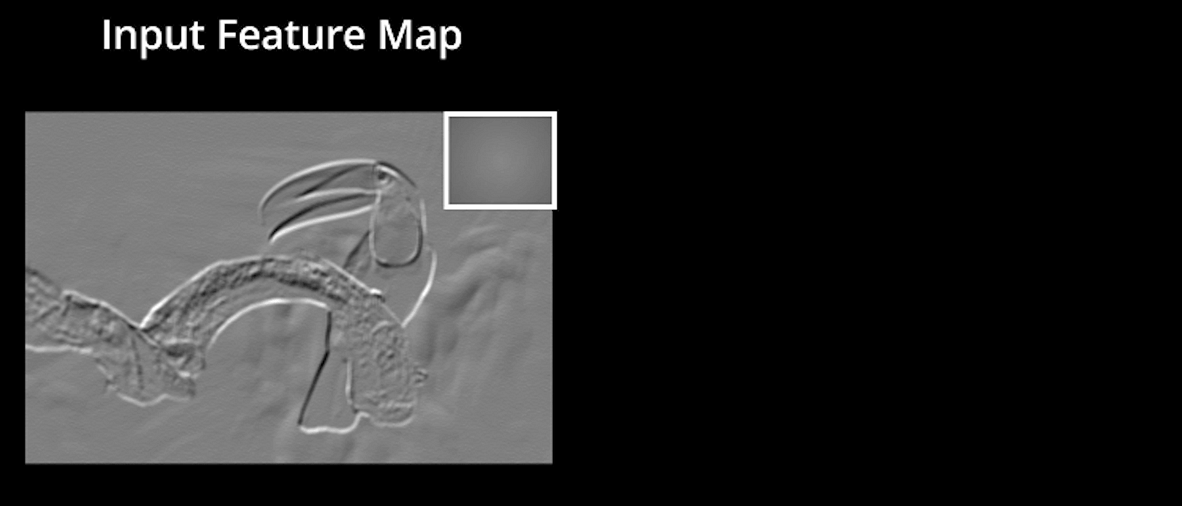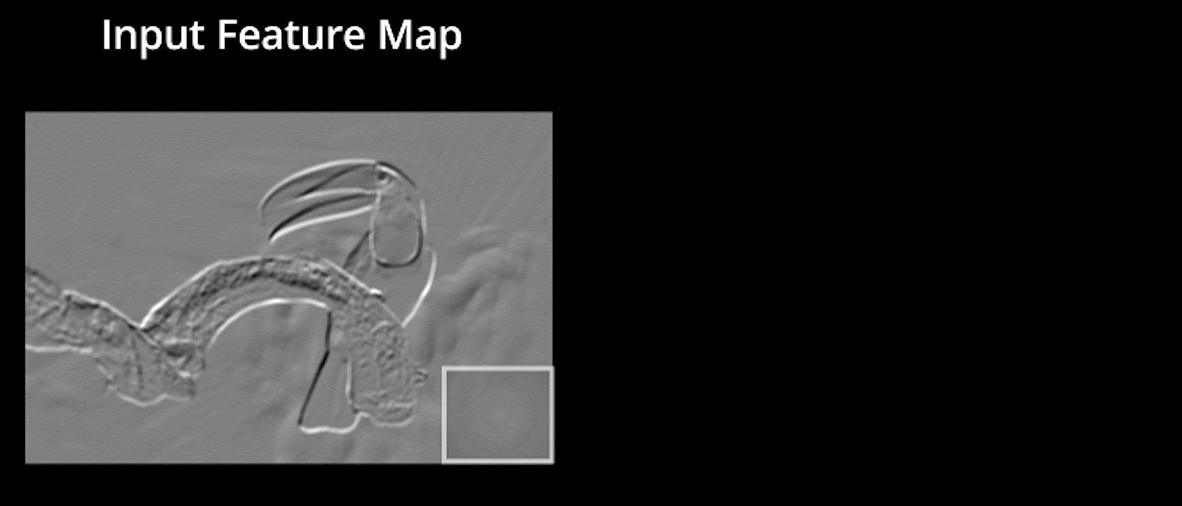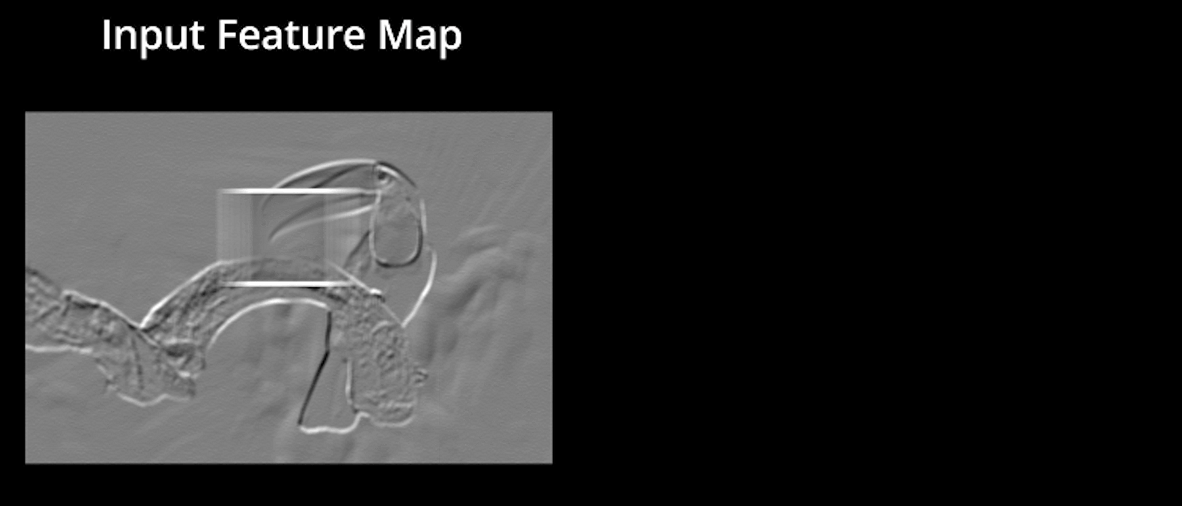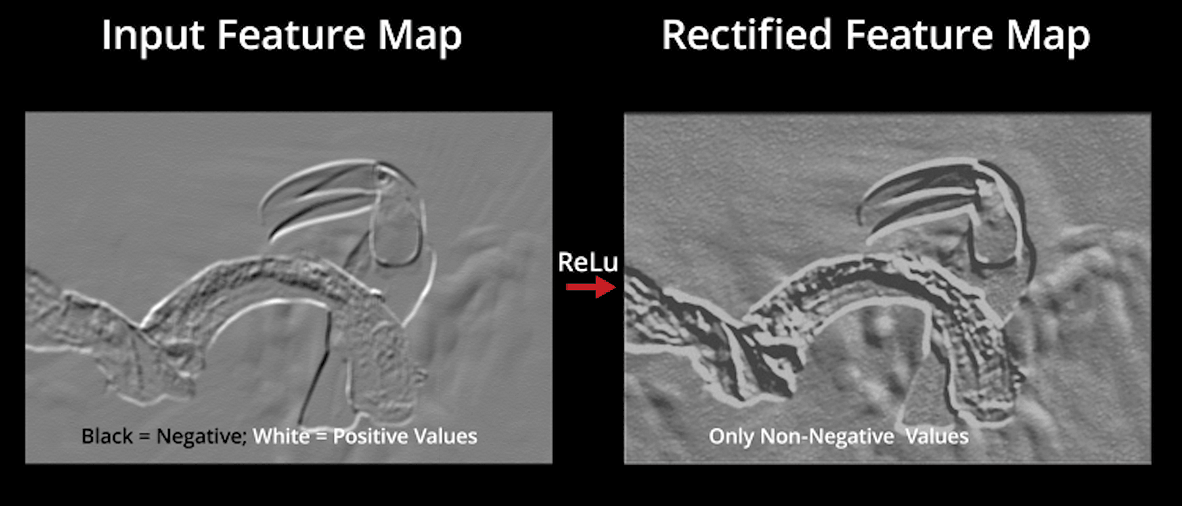
ReLU signifie l’unité linéaire rectifiée. Une fois que les cartes de caractéristiques sont extraites, l’étape suivante consiste à les déplacer vers une couche ReLU.
ReLU effectue une opération par éléments et met tous les pixels négatifs à 0. Il introduit une non-linéarité dans le réseau, et la sortie est une carte de caractéristiques rectifiée. Voici le graphique d’une fonction ReLU:
L’image originale est numérisée avec plusieurs convolutions et couches ReLU pour localiser les caractéristiques.

Couche de regroupement
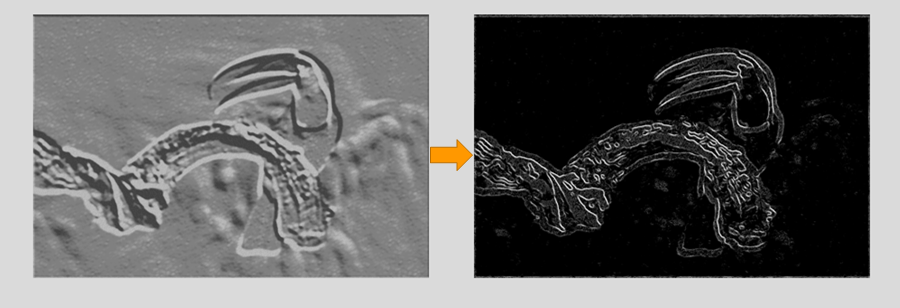
Le regroupement est une opération de sous-échantillonnage qui réduit la dimensionnalité de la carte de caractéristiques. La carte de caractéristiques rectifiée passe maintenant par une couche de mise en commun pour obtenir une carte de caractéristiques mise en commun.

La couche de mise en commun utilise divers filtres pour identifier différentes parties de l’image comme les bords, les coins, le corps, les plumes, les yeux et le bec.
Voici à quoi ressemble la structure du réseau neuronal à convolution jusqu’à présent :

L’étape suivante du processus est appelée aplatissement. L’aplatissement est utilisé pour convertir tous les tableaux bidimensionnels résultants des cartes de caractéristiques regroupées en un seul long vecteur linéaire continu.
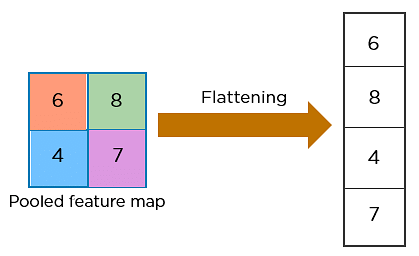
La matrice aplatie est alimentée comme entrée à la couche entièrement connectée pour classer l’image.
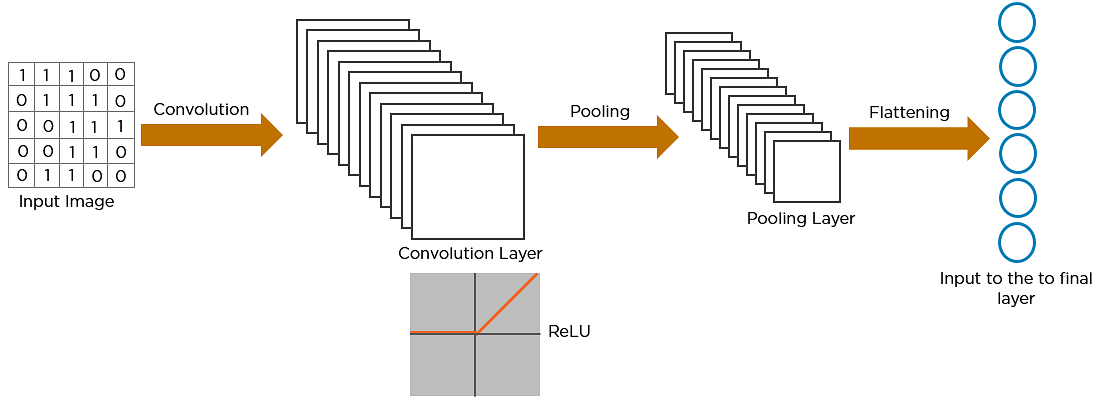
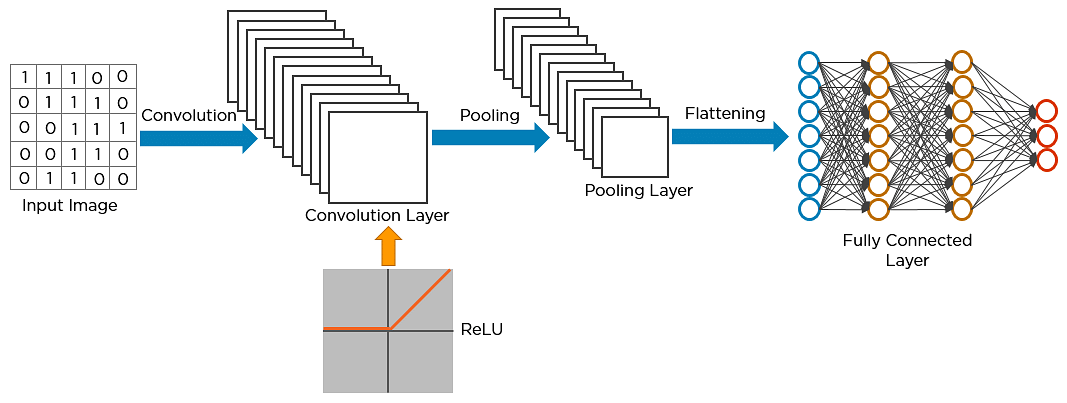
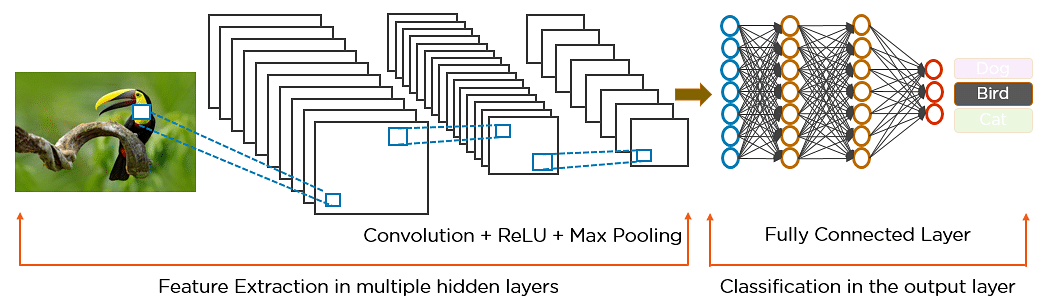
Voici comment exactement CNN reconnaît un oiseau :
- Les pixels de l’image sont introduits dans la couche convolutive qui effectue l’opération de convolution
- Il en résulte une carte convoluée
- La carte convoluée est appliquée à une fonction ReLU pour générer une carte de caractéristiques rectifiées
- L’image est traitée avec plusieurs convolutions et couches ReLU. pour localiser les caractéristiques
- Des couches de mise en commun différentes avec divers filtres sont utilisées pour identifier des parties spécifiques de l’image
- La carte de caractéristiques mise en commun est aplatie et alimentée à une couche entièrement connectée pour obtenir la sortie finale
Cours d’apprentissage automatique GRATUIT
Apprenez des compétences d’apprentissage automatique à la demande.demander des compétences et des outils d’apprentissage automatiqueDémarrer l’apprentissage
Mise en œuvre de cas d’utilisation en utilisant CNN
Nous utiliserons le jeu de données CIFAR-10 de l’Institut canadien de recherche avancée pour classer les images à travers 10 catégories en utilisant CNN.
1. Télécharger le jeu de données:

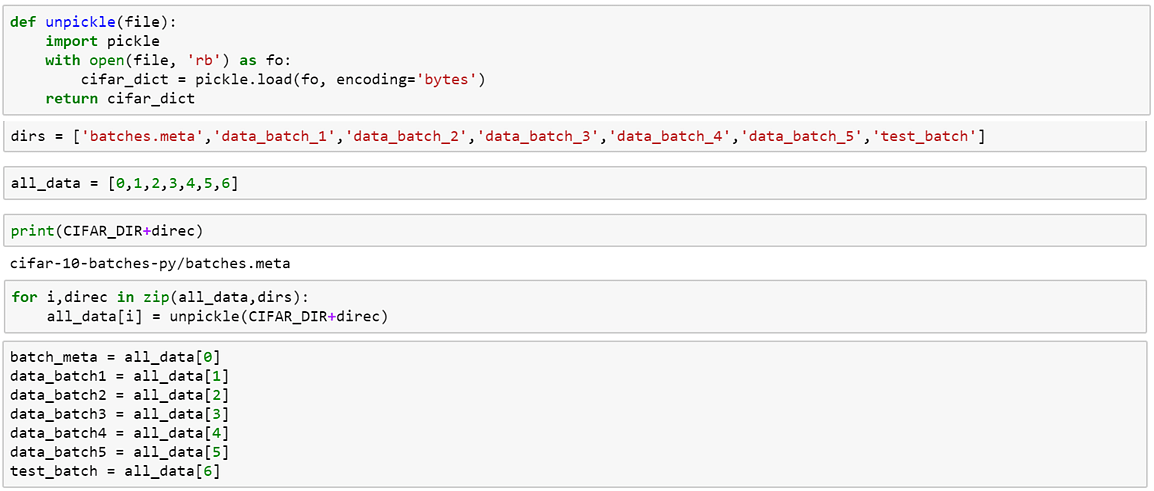
2. Importer le jeu de données CIFAR:
3. Lire les noms des étiquettes:

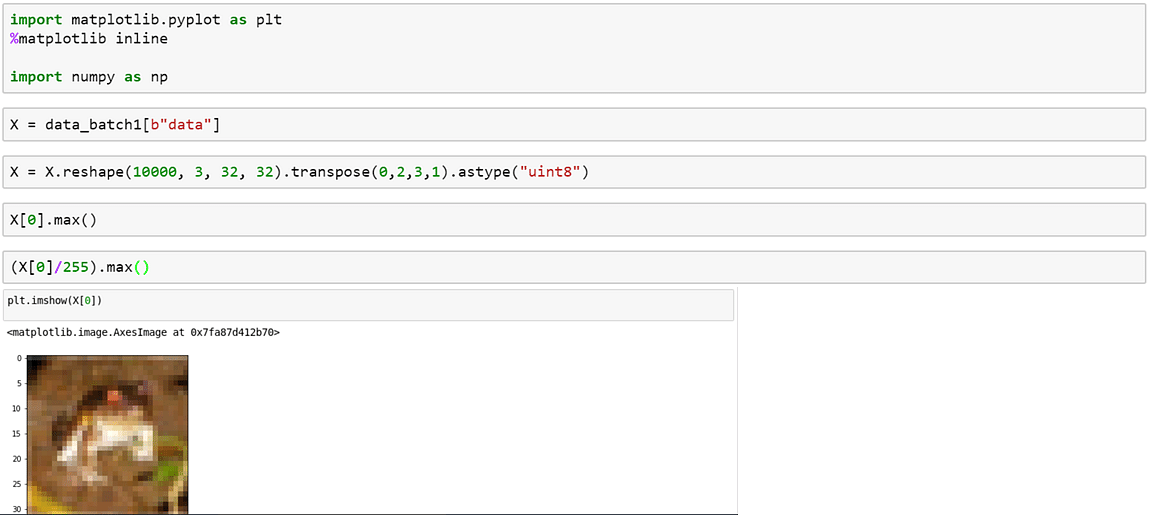
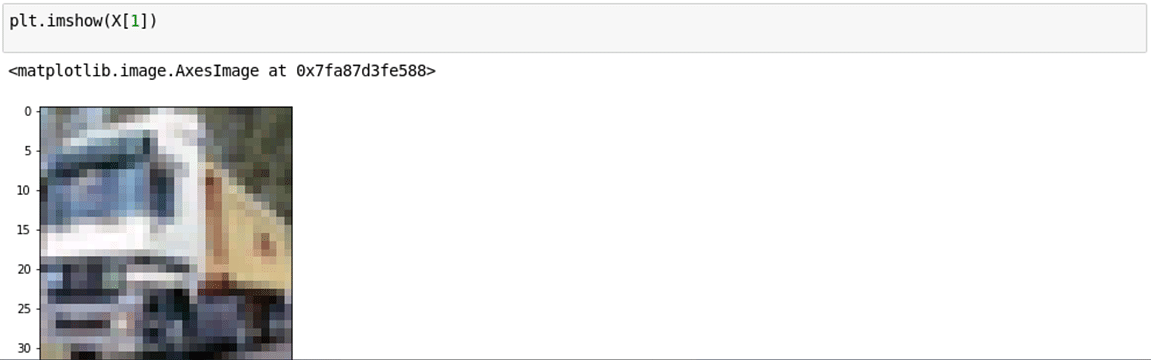
4. Afficher les images en utilisant matplotlib:
5. Utiliser la fonction d’aide pour manipuler les données:


6. Créer le modèle:

7. Appliquer les fonctions d’aide:

8. Créer les couches pour la convolution et la mise en commun:

9. Créer la couche aplatie en remodelant la couche de mise en commun:

10. Créer une couche entièrement connectée:

11. Définir la sortie à la variable y_pred:

12. Appliquer la fonction de perte:
![]()
13. Créer l’optimiseur:
![]()
14. Créer une variable pour initialiser toutes les variables globales:
![]()
15. Exécutez le modèle en créant une session graphique:

Construisez des modèles d’apprentissage profond dans TensorFlow et apprenez le framework open-source TensorFlow avec le cours d’apprentissage profond (avec Keras &TensorFlow). Inscrivez-vous dès maintenant !
Apprenez-en plus sur le CNN et l’apprentissage profond
Vous avez ainsi construit un CNN avec plusieurs couches cachées et identifié un oiseau à l’aide de ses valeurs de pixels. Vous avez également réalisé une démo pour classer des images à travers 10 catégories en utilisant le jeu de données CIFAR.
Vous pouvez également vous inscrire au programme post-universitaire en IA et apprentissage automatique avec l’Université de Purdue et en collaboration avec IBM, et vous transformer en expert des techniques d’apprentissage profond à l’aide de TensorFlow, la bibliothèque logicielle open-source conçue pour mener des recherches sur l’apprentissage automatique et les réseaux neuronaux profonds. Ce programme en IA et apprentissage automatique couvre Python, l’apprentissage automatique, le traitement du langage naturel, la reconnaissance vocale, l’apprentissage profond avancé, la vision par ordinateur et l’apprentissage par renforcement. Il vous préparera à l’une des frontières technologiques les plus passionnantes du monde.