Tutorial de Redes Neuronales Convolucionales
La Inteligencia Artificial ha recorrido un largo camino y ha ido cerrando la brecha entre el potencial de los humanos y el de las máquinas. Y los entusiastas de los datos de todo el mundo trabajan en numerosos aspectos de la IA y convierten las visiones en realidad, y una de esas áreas sorprendentes es el dominio de la visión por ordenador. El objetivo de este campo es capacitar y configurar las máquinas para que vean el mundo como lo hacen los humanos y utilicen los conocimientos para diversas tareas y procesos (como el reconocimiento de imágenes, el análisis y la clasificación de imágenes, etc.). Y los avances en Visión por Computador con el Aprendizaje Profundo han sido un éxito considerable, particularmente con el algoritmo de la Red Neural Convolucional.
En este tutorial, aprenderás sobre:
- Introducción a la CNN
- ¿Qué es una red neuronal convolucional?
- ¿Cómo reconocen las CNN las imágenes?
- Capas en CNN
- Implementación de casos de uso con CNN
Introducción a las CNN
Yann LeCun, director del Grupo de Investigación de IA de Facebook, es el pionero de las redes neuronales convolucionales. Construyó la primera red neuronal convolucional llamada LeNet en 1988. LeNet se utilizó para tareas de reconocimiento de caracteres, como la lectura de códigos postales y dígitos.
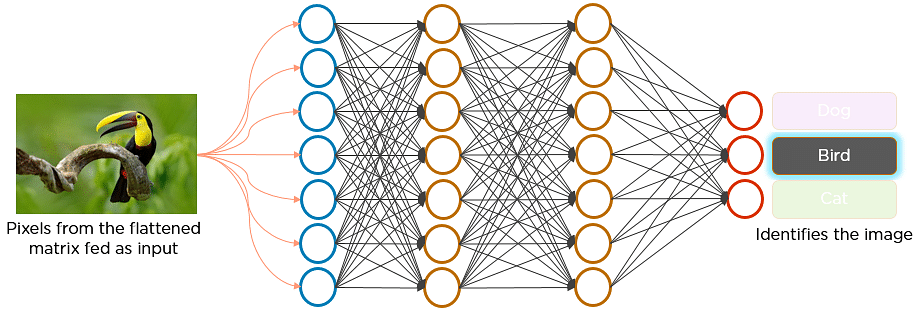
¿Te has preguntado alguna vez cómo funciona el reconocimiento facial en las redes sociales, o cómo la detección de objetos ayuda en la construcción de coches autoconducidos, o cómo la detección de enfermedades se realiza utilizando imágenes visuales en la atención sanitaria? Todo es posible gracias a las redes neuronales convolucionales (CNN). He aquí un ejemplo de redes neuronales convolucionales que ilustra su funcionamiento:
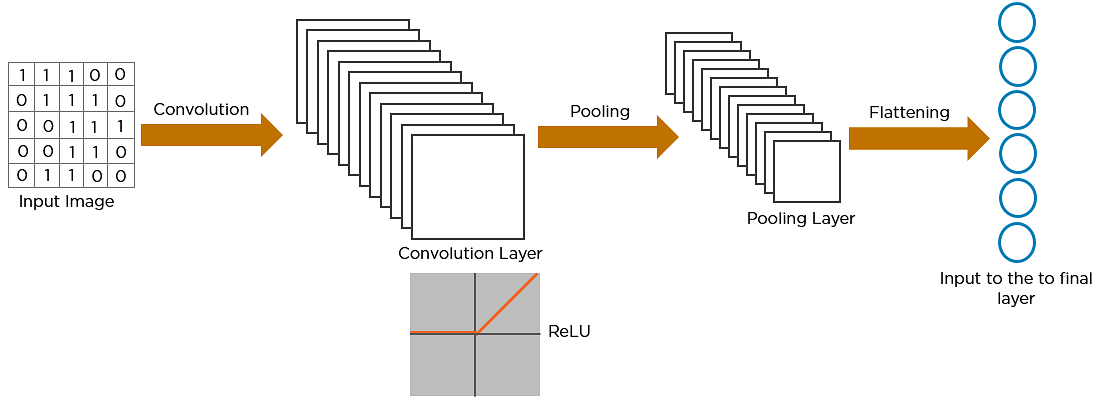
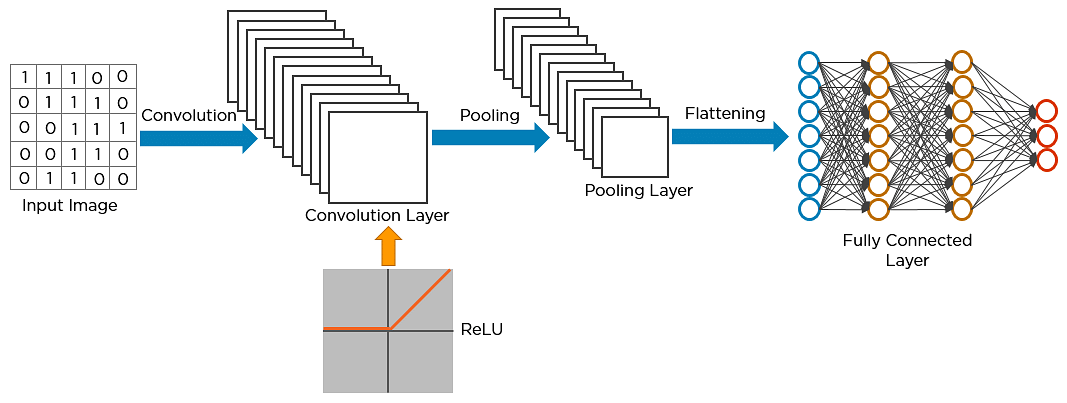
Imagina que hay una imagen de un pájaro y quieres identificar si es realmente un pájaro o algún otro objeto. Lo primero que se hace es alimentar los píxeles de la imagen en forma de matrices a la capa de entrada de la red neuronal (redes multicapa utilizadas para clasificar cosas). Las capas ocultas llevan a cabo la extracción de características realizando diferentes cálculos y manipulaciones. Hay varias capas ocultas, como la capa de convolución, la capa ReLU y la capa de agrupación, que realizan la extracción de características de la imagen. Finalmente, hay una capa totalmente conectada que identifica el objeto en la imagen.
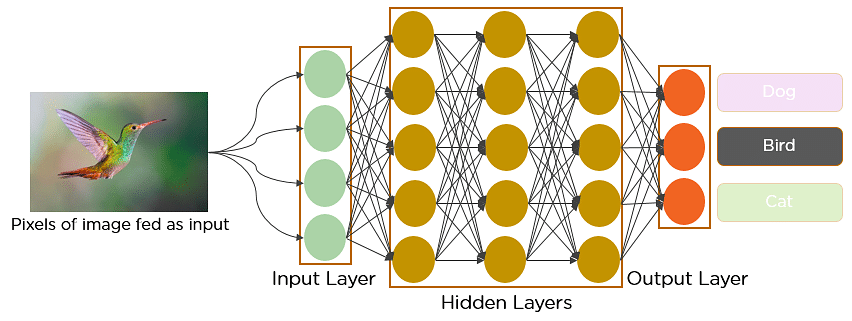
Fig: Red Neural Convolucional para identificar la imagen de un pájaro
Curso de Aprendizaje Profundo (con TensorFlow & Keras)
Dominar los conceptos y modelos de Aprendizaje ProfundoVer Curso
¿Qué es la Red Neural Convolucional?
Una red neuronal convolucional es una red neuronal feed-forward que se utiliza generalmente para analizar imágenes visuales mediante el procesamiento de datos con topología de cuadrícula. También se conoce como ConvNet. Una red neuronal convolucional se utiliza para detectar y clasificar objetos en una imagen.
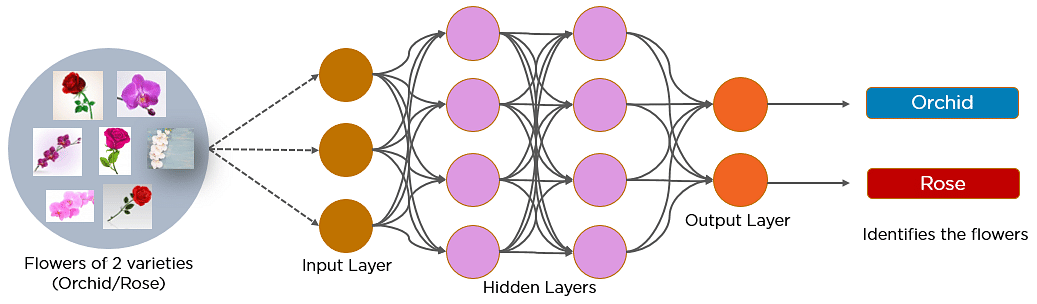
A continuación se muestra una red neuronal que identifica dos tipos de flores: Orquídea y Rosa.
En la CNN, cada imagen se representa en forma de una matriz de valores de píxeles.
![]()
La operación de convolución constituye la base de cualquier red neuronal convolucional. Entendamos la operación de convolución utilizando dos matrices, a y b, de 1 dimensión.
a =
b =
En la operación de convolución, las matrices se multiplican elemento a elemento, y el producto se suma para crear una nueva matriz, que representa a*b.
Los tres primeros elementos de la matriz a se multiplican con los elementos de la matriz b. El producto se suma para obtener el resultado.

Los tres siguientes elementos de la matriz a se multiplican por los elementos de la matriz b, y el producto se suma.

Este proceso continúa hasta completar la operación de convolución.
¿Cómo reconoce la CNN las imágenes?
Considera las siguientes imágenes:
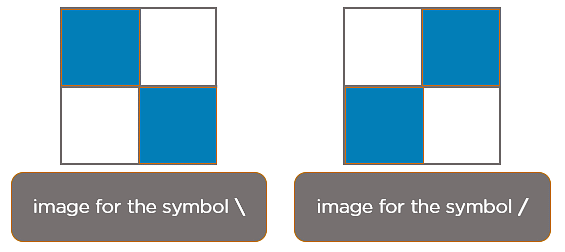
Las casillas que están coloreadas representan un valor de píxel de 1, y 0 si no están coloreadas.
Cuando se pulsa la barra invertida (\), se procesa la siguiente imagen.

Cuando se pulsa la barra diagonal (/), se procesa la siguiente imagen:

Aquí hay otro ejemplo para representar cómo la CNN reconoce una imagen:
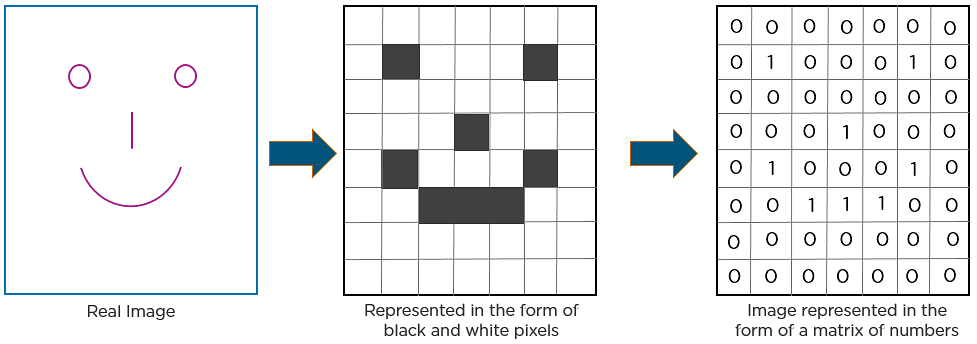
Como se puede ver en el diagrama anterior, sólo se iluminan los valores que tienen un valor de 1.
Capas en una red neuronal convolucional
Una red neuronal convolucional tiene múltiples capas ocultas que ayudan a extraer información de una imagen. Las cuatro capas importantes de la CNN son:
- Capa de convolución
- Capa ReLU
- Capa de acumulación
- Capa totalmente conectada
Capa de convolución
Este es el primer paso en el proceso de extracción de características valiosas de una imagen. Una capa de convolución tiene varios filtros que realizan la operación de convolución. Cada imagen se considera como una matriz de valores de píxeles.
Considere la siguiente imagen de 5×5 cuyos valores de píxeles son 0 o 1. También hay una matriz de filtros con una dimensión de 3×3. Desliza la matriz de filtros sobre la imagen y calcula el producto de puntos para obtener la matriz de características convolucionada.
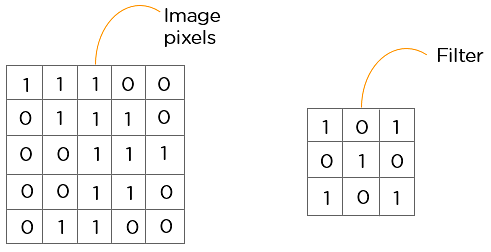

Capa ReLU
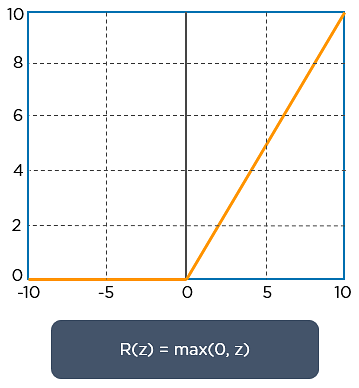
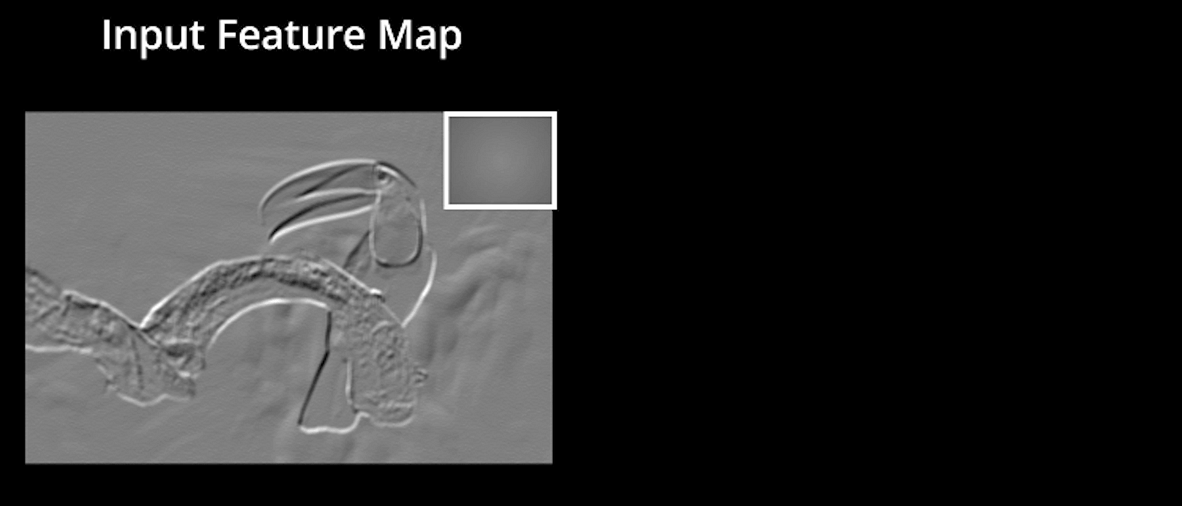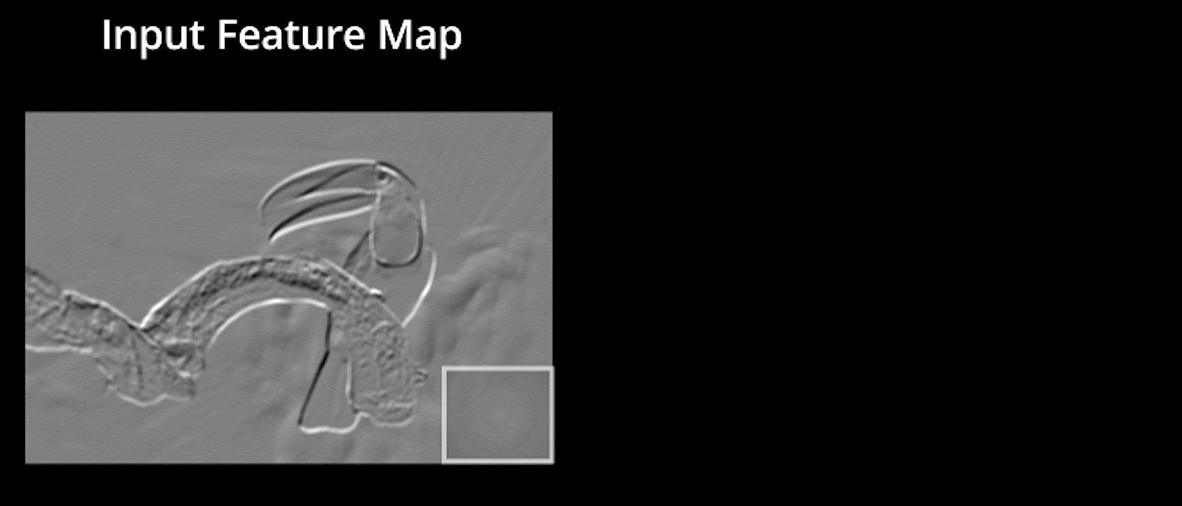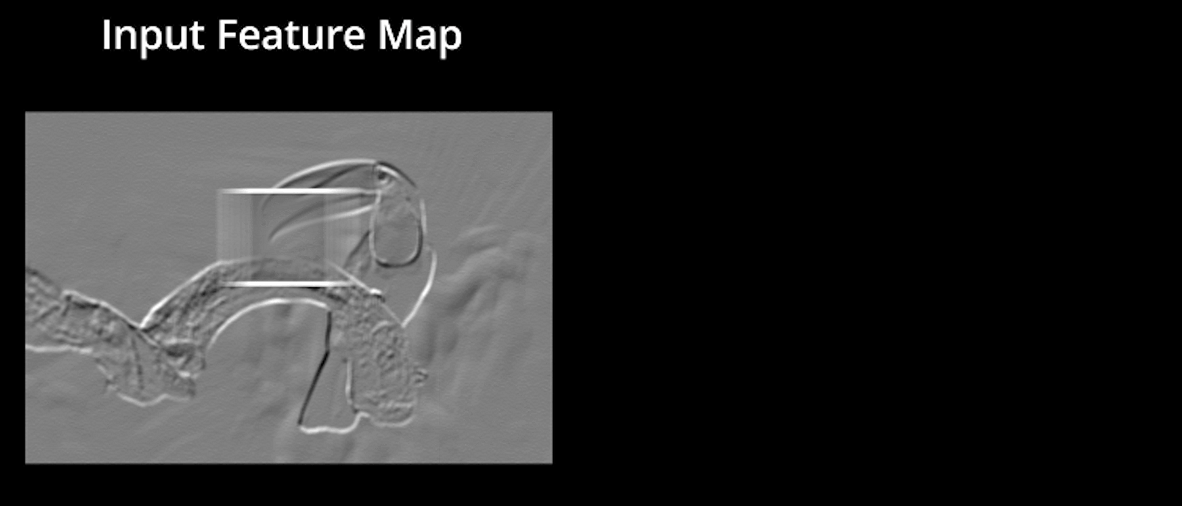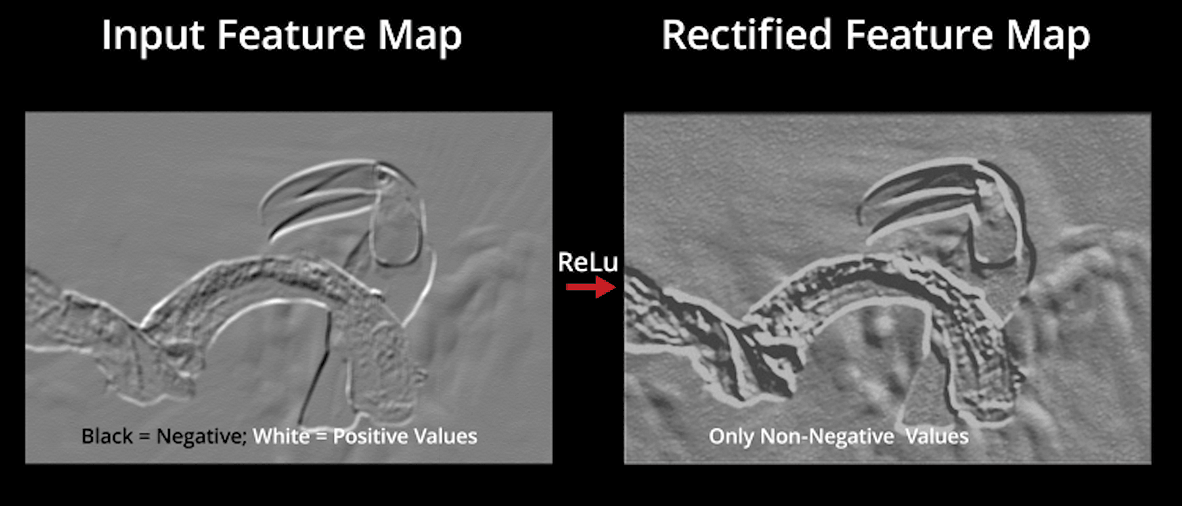
ReLU significa la unidad lineal rectificada. Una vez extraídos los mapas de características, el siguiente paso es trasladarlos a una capa ReLU.
ReLU realiza una operación a lo largo de los elementos y pone todos los píxeles negativos a 0. Introduce la no linealidad en la red, y la salida generada es un mapa de características rectificado. A continuación se muestra el gráfico de una función ReLU:
La imagen original se escanea con múltiples convoluciones y capas ReLU para localizar las características.

Capa de agrupamiento
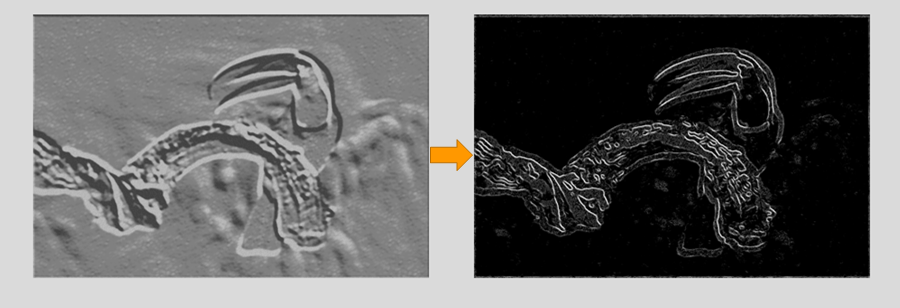
El agrupamiento es una operación de muestreo descendente que reduce la dimensionalidad del mapa de características. El mapa de características rectificado pasa ahora por una capa de agrupación para generar un mapa de características agrupado.

La capa de agrupación utiliza varios filtros para identificar diferentes partes de la imagen como bordes, esquinas, cuerpo, plumas, ojos y pico.
Así es como se ve la estructura de la red neuronal de convolución hasta ahora:

El siguiente paso en el proceso se llama aplanamiento. El aplanamiento se utiliza para convertir todas las matrices bidimensionales resultantes de los mapas de características agrupadas en un único vector lineal largo y continuo.
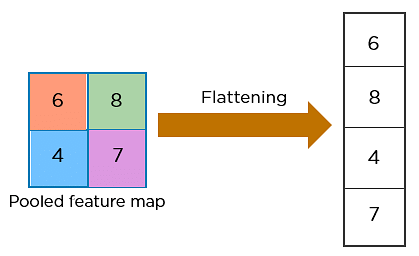
La matriz aplanada se introduce como entrada en la capa totalmente conectada para clasificar la imagen.
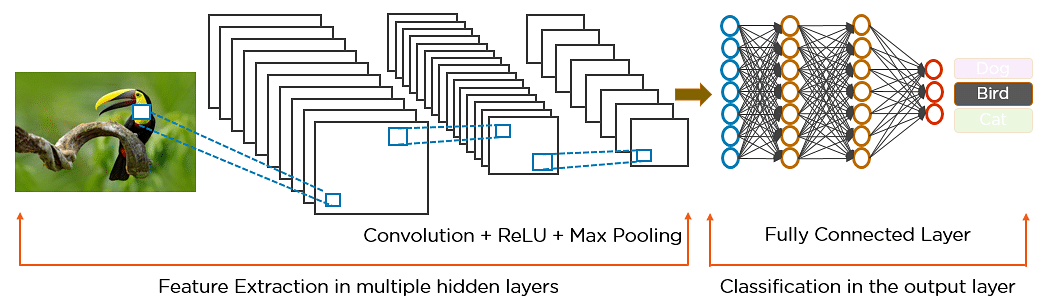
Así es como la CNN reconoce exactamente un pájaro:
- Los píxeles de la imagen pasan a la capa convolucional que realiza la operación de convolución
- Se obtiene un mapa convolucionado
- El mapa convolucionado se aplica a una función ReLU para generar un mapa de características rectificado
- La imagen se procesa con múltiples convoluciones y capas ReLU para localizar las características
- Se utilizan diferentes capas de agrupación con varios filtros para identificar partes específicas de la imagen
- El mapa de características agrupado se aplana y se alimenta a una capa totalmente conectada para obtener la salida final
Curso gratuito de aprendizaje automático
Aprende endemanda de habilidades y herramientas de aprendizaje automáticoInicie el aprendizaje
Implementación de casos de uso utilizando CNN
Utilizaremos el conjunto de datos CIFAR-10 del Canadian Institute For Advanced Research para clasificar imágenes en 10 categorías utilizando CNN.
1. Descargar el conjunto de datos:

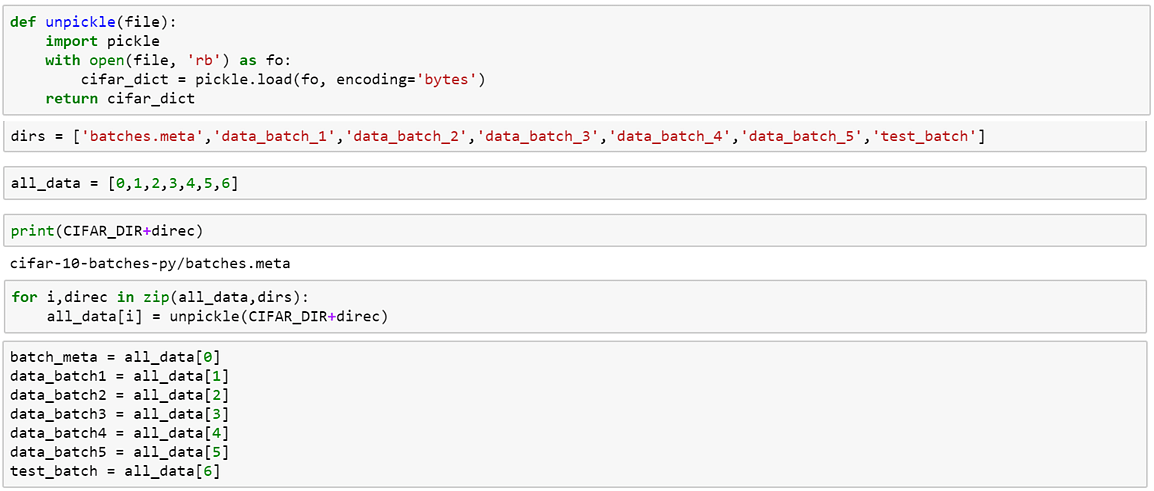
2. Importar el conjunto de datos CIFAR:
3. Leer los nombres de las etiquetas:

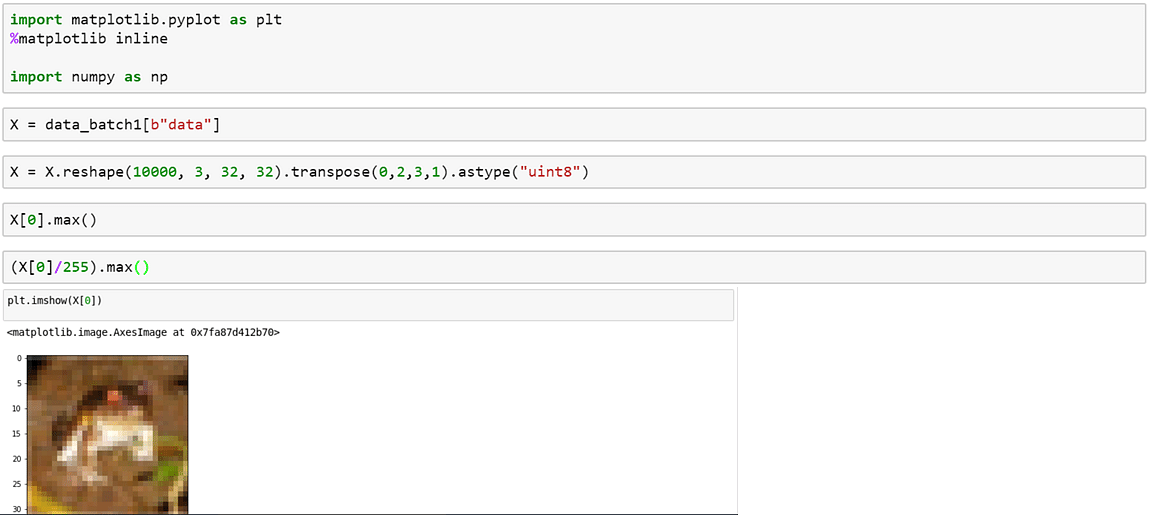
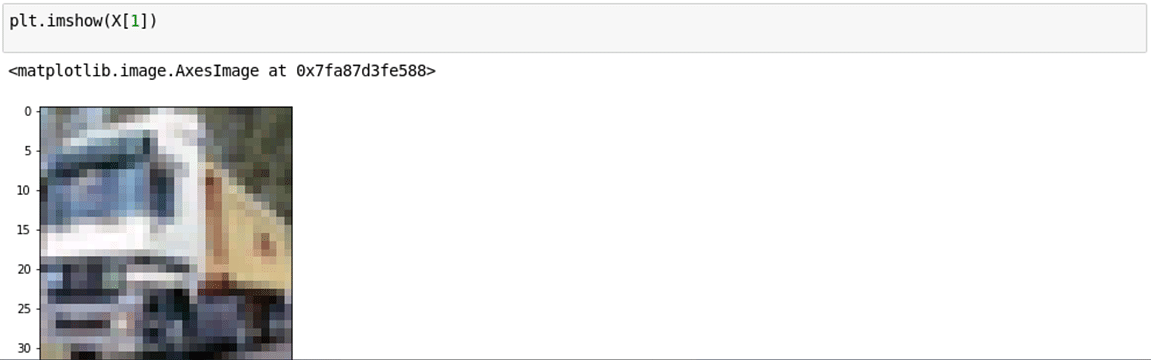
4. Visualizar las imágenes utilizando matplotlib:
5. Utilizar la función de ayuda para manejar los datos:


6. Crear el modelo:

7. Aplicar las funciones de ayuda:

8. Crear las capas para la convolución y la agrupación:

9. Crear la capa aplanada remodelando la capa de pooling:

10. Crear una capa totalmente conectada:

11. Establecer la salida en la variable y_pred:

12. Aplicar la función de pérdida:
![]()
13. Crear el optimizador:
![]()
14. Crear una variable para inicializar todas las variables globales:
![]()
15. Ejecutar el modelo creando una sesión de gráficos:

Construye modelos de aprendizaje profundo en TensorFlow y aprende el framework de código abierto TensorFlow con el Curso de Aprendizaje Profundo (con Keras &TensorFlow). Inscríbete ahora!
Aprende más sobre CNN y aprendizaje profundo
Así construyes una CNN con múltiples capas ocultas y cómo identificar un pájaro usando sus valores de píxeles. También has completado una demo para clasificar imágenes a través de 10 categorías utilizando el conjunto de datos CIFAR.
También puedes inscribirte en el Programa de Postgrado en IA y Aprendizaje Automático con la Universidad de Purdue y en colaboración con IBM, y transformarte en un experto en técnicas de aprendizaje profundo utilizando TensorFlow, la biblioteca de software de código abierto diseñada para llevar a cabo investigaciones sobre aprendizaje automático y redes neuronales profundas. Este programa en IA y Aprendizaje Automático cubre Python, Aprendizaje Automático, Procesamiento del Lenguaje Natural, Reconocimiento del Habla, Aprendizaje Profundo Avanzado, Visión por Computador y Aprendizaje por Refuerzo. Te preparará para una de las fronteras tecnológicas más emocionantes del mundo.