NGINX og HAProxy: Test af brugeroplevelsen i skyen – NGINX NGINX og HAProxy: Test af brugeroplevelsen i skyen
Mange benchmarks for ydeevne måler spidsgennemløb eller forespørgsler pr. sekund (RPS), men disse målinger kan forsimple ydelseshistorien på virkelige steder i den virkelige verden. Kun få organisationer kører deres tjenester ved eller tæt på spidsgennemstrømning, hvor en 10 % ændring i ydeevnen i begge retninger kan gøre en betydelig forskel. Det gennemløb eller RPS, som et websted kræver, er ikke uendeligt, men fastsættes af eksterne faktorer som f.eks. antallet af samtidige brugere, de skal betjene, og aktivitetsniveauet for hver enkelt bruger. I sidste ende er det vigtigste, at dine brugere får det bedste serviceniveau. Slutbrugerne er ligeglade med, hvor mange andre mennesker der besøger dit websted. De er bare interesseret i den service, de modtager, og undskylder ikke dårlig ydelse, fordi systemet er overbelastet.
Dette fører os til den konstatering, at det vigtigste er, at en organisation leverer en ensartet ydelse med lav latenstid til alle sine brugere, selv under høj belastning. Ved at sammenligne NGINX og HAProxy, der kører på Amazon Elastic Compute Cloud (EC2) som reverse proxies, satte vi os for at gøre to ting:
- Bestemme, hvilket belastningsniveau hver proxy komfortabelt kan håndtere
- Indsamle latency-percentilfordelingen, som vi finder er den metrik, der er mest direkte korreleret med brugeroplevelsen
Testprotokoller og indsamlede metrikker
Vi brugte load-generationsprogrammet wrk2 til at emulere en klient, der foretager kontinuerlige anmodninger over HTTPS i en defineret periode. Det testede system – HAProxy eller NGINX – fungerede som en reverse proxy, der etablerede krypterede forbindelser med de klienter, der blev simuleret af wrk-tråde, videresendte anmodninger til en backend-webserver, der kører NGINX Plus R22, og returnerede det svar, der blev genereret af webserveren (en fil), til klienten.
Hver af de tre komponenter (klient, reverse proxy og webserver) kørte Ubuntu 20.04.1 LTS på et c5n.2xlarge Amazon Machine Image (AMI) i EC2.
Som nævnt indsamlede vi den fulde latency-percentilefordeling fra hver testkørsel. Latency er defineret som den tid, der går mellem klientens generering af anmodningen og modtagelsen af svaret. En latency-percentilfordeling sorterer de latency-målinger, der er indsamlet i løbet af testperioden, fra højeste (mest latency) til laveste.
Testmetodologi
Client
Ved hjælp af wrk2 (version 4.0.0) kørte vi følgende script på Amazon EC2-instansen:
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/For at simulere mange klienter, der får adgang til et webprogram, blev der oprettet 4 wrk tråde, der tilsammen etablerede 100 forbindelser til reverse proxy’en. I løbet af den 30 sekunders testkørsel genererede scriptet et bestemt antal RPS. Disse parametre svarer til følgende wrk2 indstillinger:
-
‑tindstilling – Antal tråde, der skal oprettes (4) -
‑cindstilling – Antal TCP-forbindelser, der skal oprettes (100) -
‑dindstilling – Antal sekunder i testperioden (30 sekunder) -
‑Rindstilling – -
‑Rindstilling – -
‑Rindstilling –-
‑Rindstilling –-
‑tindstilling – Antal tråde, der skal oprettes (4). Antal RPS udstedt af klienten -
‑‑latencyoption – Output indeholder oplysninger om korrigeret latencypercentil
Vi øgede gradvist antallet af RPS i løbet af testkørslerne, indtil en af proxierne ramte 100 % CPU-udnyttelse. For yderligere diskussion, se Ydelsesresultater.
Alle forbindelser mellem klient og proxy blev foretaget over HTTPS med TLSv1.3. Vi brugte ECC med en nøgle på 256 bit, Perfect Forward Secrecy og
TLS_AES_256_GCM_SHA384cipher suite. (Da TLSv1.2 stadig er almindeligt anvendt på internettet, genudførte vi også testene med det; resultaterne var så ens med dem for TLSv1.3, at vi ikke medtager dem her.)HAProxy: Konfiguration og versionering
Vi har konfigureret HAProxy version 2.3 (stable) som reverse proxy.
Antallet af samtidige brugere på et populært websted kan være enormt. For at kunne håndtere den store trafikmængde skal din reverse proxy kunne skaleres for at udnytte flere kerner. Der er to grundlæggende måder at skalere på: multi-processing og multi-threading. Både NGINX og HAProxy understøtter multiprocessing, men der er en vigtig forskel – i HAProxys implementering deler processerne ikke hukommelse (hvorimod de gør det i NGINX). Den manglende mulighed for at dele tilstand på tværs af processer har flere konsekvenser for HAProxy:
- Konfigurationsparametre – herunder grænser, statistikker og hastigheder – skal defineres separat for hver proces.
- Præstationsmålinger indsamles pr. proces; at kombinere dem kræver yderligere config, hvilket kan være ret komplekst.
- Hver proces håndterer sundhedskontroller separat, så målservere undersøges pr. proces i stedet for pr. server som forventet.
- Sessionsvedligeholdelse er ikke mulig.
- En dynamisk konfigurationsændring, der foretages via HAProxy Runtime API, gælder for en enkelt proces, så du skal gentage API-kaldet for hver proces.
På grund af disse problemer fraråder HAProxy kraftigt brugen af implementeringen af multiprocesser. For at citere direkte fra HAProxy-konfigurationsmanualen:
Brug af flere processer er sværere at fejlsøge og frarådes virkelig.
HAProxy introducerede multi-threading i version 1.8 som et alternativ til multi-processing. Multi-threading løser for det meste problemet med deling af tilstande, men som vi diskuterer i Ydelsesresultater, yder HAProxy i multi-thread-tilstand ikke lige så godt som i multi-procestilstand.
Vores HAProxy-konfiguration omfattede tilrådighedsstillelse for både multithread-tilstand (HAProxy MT) og multiprocestilstand (HAProxy MP). For at skifte mellem tilstande på hvert RPS-niveau under testen kommenterede og afkommenterede vi det relevante sæt linjer og genstartede HAProxy for at få konfigurationen til at træde i kraft:
$ sudo service haproxy restartHer er konfigurationen med HAProxy MT provisioned: fire tråde oprettes under en proces, og hver tråd er fastgjort til en CPU. For HAProxy MP (kommenteret ud her) er der fire processer, der hver især er pinned til en CPU.
global #Multi-thread mode nbproc 1 nbthread 4 cpu-map auto:1/1-4 0-3 #Multi-process mode #nbproc 4 #cpu-map 1 0 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 ssl-server-verify none log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy maxconn 4096 defaults log global option httplog option http-keep-alive frontend Local_Server bind 172.31.12.25:80 bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem redirect scheme https code 301 if !{ ssl_fc } default_backend Web-Pool http-request set-header Connection keep-alive backend Web-Pool mode http server server1 backend.workload.1:80 checkNGINX: Konfiguration og versionering
Vi implementerede NGINX Open Source version 1.18.0 som reverse proxy.
For at bruge alle de kerner, der er tilgængelige på maskinen (fire i dette tilfælde), inkluderede vi parameteren
autotilworker_processes-direktivet, hvilket også er indstillingen i standardfilen nginx.conf, der distribueres fra vores repository. Derudover blevworker_cpu_affinity-direktivet inkluderet for at fastgøre hver arbejdsproces til en CPU (hvert1i den anden parameter angiver en CPU i maskinen).user nginx;worker_processes auto;worker_cpu_affinity auto 1111;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events { worker_connections 1024;}http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 65; keepalive_requests 100000; server { listen 443 ssl reuseport; ssl_certificate /etc/ssl/certs/hapee.pem; ssl_certificate_key /etc/ssl/private/hapee.key; ssl_protocols TLSv1.3; location / { proxy_set_header Connection ' '; proxy_http_version 1.1; proxy_pass http://backend; } } upstream backend { server backend.workload.1:80; keepalive 100; }}Præstationsresultater
Som front-end til din applikation er ydeevnen for din reverse proxy kritisk.
Vi testede hver reverse proxy (NGINX, HAProxy MP og HAProxy MT) ved stigende antal RPS, indtil en af dem nåede 100 % CPU-udnyttelse. Alle tre præsterede på samme måde på de RPS-niveauer, hvor CPU’en ikke blev udtømt.
Det skete først for HAProxy MT at nå 100 % CPU-udnyttelse ved 85.000 RPS, og på det tidspunkt forværredes ydelsen dramatisk for både HAProxy MT og HAProxy MP. Her præsenterer vi fordelingen af latenspercentilen for hver reverse proxy ved dette belastningsniveau. Diagrammet blev plottet ud fra output af
wrkscriptet ved hjælp af programmet HdrHistogram, der er tilgængeligt på GitHub.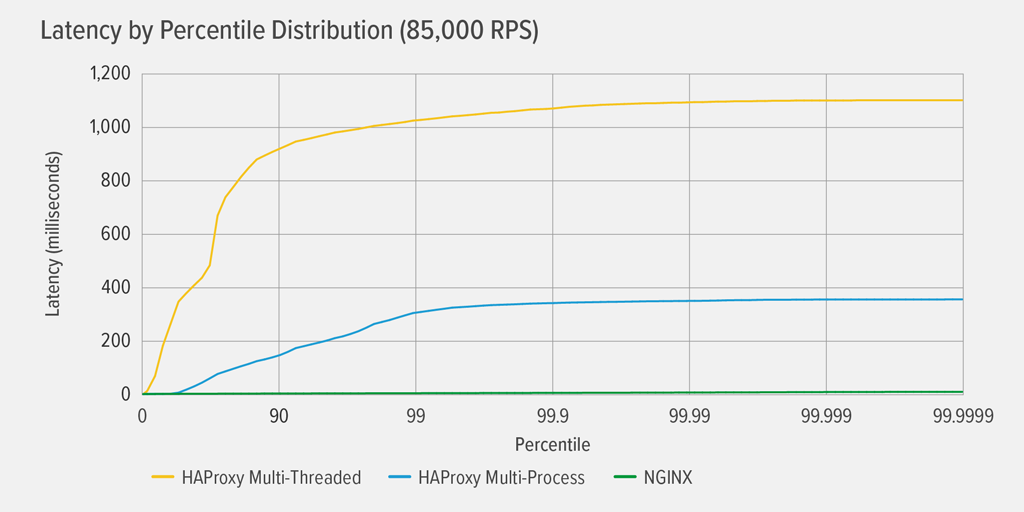
Til 85.000 RPS stiger latenstiden med HAProxy MT brat indtil den 90. percentil, hvorefter den gradvist stabiliseres ved ca. 1100 millisekunder (ms).
HAProxy MP klarer sig bedre end HAProxy MT – latenstiden stiger langsommere indtil den 99. percentil, hvorefter den begynder at flade ud ved ca. 400 ms. (Som en bekræftelse på, at HAProxy MP er mere effektiv, observerede vi, at HAProxy MT brugte lidt mere CPU end HAProxy MP på hvert RPS-niveau.)
NGINX lider stort set ingen latenstid ved nogen percentil. Den højeste latenstid, som et betydeligt antal brugere kan opleve (ved 99,9999-percentilen), er ca. 8 ms.
Hvad fortæller disse resultater os om brugeroplevelsen? Som nævnt i indledningen er den metrik, der virkelig betyder noget, svartiden fra slutbrugerens perspektiv, og ikke servicetiden for det system, der testes.
Det er en almindelig misforståelse, at medianlatenstiden i en fordeling bedst repræsenterer brugeroplevelsen. Faktisk er medianen det tal, som ca. halvdelen af svartiderne er dårligere end! Brugere udsender typisk mange forespørgsler og får adgang til mange ressourcer pr. sideindlæsning, så flere af deres forespørgsler vil nødvendigvis opleve latenstider på de øverste percentiler i diagrammet (99. til 99,9999.). Fordi brugerne er så intolerante over for dårlig ydeevne, er det latenstider på de høje percentiler, som de sandsynligvis lægger mest mærke til.
Tænk på det på denne måde: Din oplevelse af at tjekke ud i en købmandsbutik er bestemt af, hvor lang tid det tager at forlade butikken fra det øjeblik, du stod i kassekøen, og ikke kun hvor lang tid det tog for kassedamen at bogføre dine varer. Hvis f.eks. en kunde foran dig anfægter prisen på en vare, og kassedamen skal få en anden til at bekræfte det, er din samlede kassetid meget længere end normalt.
For at tage højde for dette i vores latenceresultater skal vi korrigere for noget, der kaldes koordineret udeladelse, hvor (som forklaret i en note i slutningen af
wrk2README) “svar med høj latency resulterer i, at belastningsgeneratoren koordinerer med serveren for at undgå måling i perioder med høj latency”. Heldigvis korrigererwrk2som standard for koordineret udeladelse (se README for flere oplysninger om koordineret udeladelse).Når HAProxy MT udtømmer CPU’en ved 85.000 RPS, oplever mange anmodninger høj latenstid. De er med rette medtaget i dataene, fordi vi korrigerer for koordineret udeladelse. Der skal blot en eller to anmodninger med høj latenstid til at forsinke indlæsningen af en side og resultere i opfattelsen af dårlig ydeevne. I betragtning af, at et rigtigt system betjener flere brugere ad gangen, selv om kun 1 % af anmodningerne har høj latenstid (værdien ved den 99. percentil), er en stor del af brugerne potentielt berørt.
Slutning
Et af hovedpunkterne i benchmarking af ydeevne er at fastslå, om din app er responsiv nok til at tilfredsstille brugerne og få dem til at komme tilbage.
Både NGINX og HAProxy er softwarebaserede og har begivenhedsdrevne arkitekturer. Mens HAProxy MP leverer bedre ydeevne end HAProxy MT, gør manglen på deling af tilstand mellem processerne forvaltningen mere kompleks, som vi beskrev i detaljer i HAProxy: Konfiguration og versionering. HAProxy MT løser disse begrænsninger, men på bekostning af lavere ydeevne, som det fremgår af resultaterne.
Med NGINX er der ingen kompromiser – fordi processerne deler tilstand, er der ikke behov for en multi-threading-tilstand, fordi processerne deler tilstand. Du får den overlegne ydeevne ved multiprocessering uden de begrænsninger, der gør, at HAProxy fraråder brugen af den.
-