VGG16 – konvoluční síť pro klasifikaci a detekci
VGG16 je model konvoluční neuronové sítě navržený K. Simonyanem a A. Zissermanem z Oxfordské univerzity v článku „Very Deep Convolutional Networks for Large-Scale Image Recognition“. Tento model dosahuje 92,7% přesnosti top-5 testů v síti ImageNet, což je datová sada obsahující více než 14 milionů obrázků patřících do 1000 tříd. Byl to jeden ze slavných modelů předložených na konferenci ILSVRC-2014. Zlepšení oproti modelu AlexNet dosahuje nahrazením velkých filtrů o velikosti jádra (11 a 5 v první, resp. druhé konvoluční vrstvě) několika filtry o velikosti jádra 3×3 za sebou. VGG16 byl trénován několik týdnů a používal grafické procesory NVIDIA Titan Black.
Sada dat
ImageNet je datová sada více než 15 milionů označených obrázků s vysokým rozlišením patřících do zhruba 22 000 kategorií. Obrázky byly shromážděny z webu a označeny lidskými štítkovači pomocí crowd-sourcingového nástroje Mechanical Turk společnosti Amazon. Od roku 2010 se v rámci soutěže Pascal Visual Object Challenge každoročně koná soutěž nazvaná ImageNet Large-Scale Visual Recognition Challenge (ILSVRC). ILSVRC používá podmnožinu sítě ImageNet se zhruba 1000 obrázky v každé z 1000 kategorií. Celkem je k dispozici zhruba 1,2 milionu trénovacích obrázků, 50 000 validačních obrázků a 150 000 testovacích obrázků. Síť ImageNet se skládá z obrázků s proměnlivým rozlišením. Proto byly obrázky zmenšeny na pevné rozlišení 256×256. Při zadání obdélníkového obrázku se změní jeho měřítko a z výsledného obrázku se vyřízne centrální políčko o rozměrech 256×256.
Architektura
Níže zobrazená architektura je VGG16.
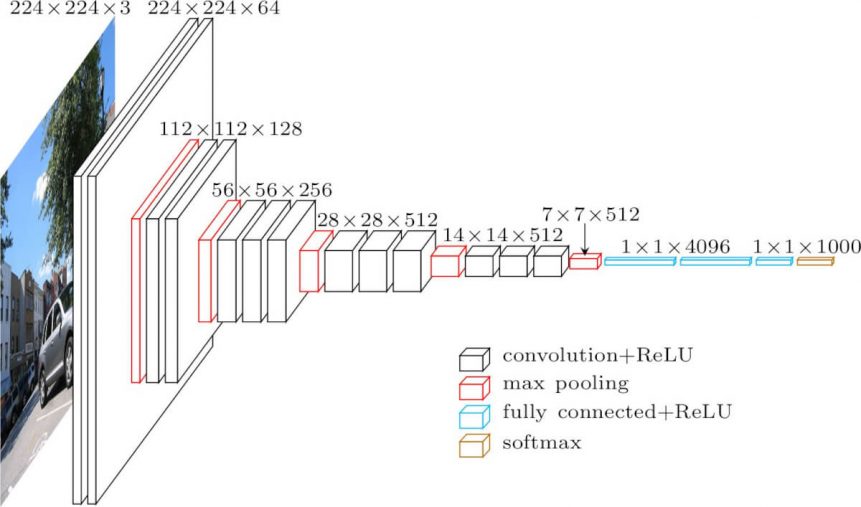
Vstup do vrstvy cov1 má pevnou velikost 224 x 224 obrázků RGB. Obraz prochází zásobníkem konvolučních (konv.) vrstev, kde byly použity filtry s velmi malým receptivním polem: 3×3 (což je nejmenší velikost pro zachycení pojmů vlevo/vpravo, nahoře/dole, uprostřed). V jedné z konfigurací se také využívá konvolučních filtrů 1×1, což lze chápat jako lineární transformaci vstupních kanálů (s následnou nelinearitou). Krok konvoluce je pevně stanoven na 1 pixel; prostorová výplň vstupní konvoluční vrstvy je taková, aby bylo po konvoluci zachováno prostorové rozlišení, tj. výplň je 1 pixel pro 3×3 konvoluční vrstvy. Prostorové sdružování se provádí pomocí pěti vrstev max-pooling, které následují za některými konv. vrstvami (ne za všemi konv. vrstvami následuje max-pooling). Max-pooling se provádí nad oknem 2×2 pixely s krokem 2.
Tři plně propojené vrstvy (FC) následují za zásobníkem konvolučních vrstev (který má v různých architekturách různou hloubku): první dvě mají každá 4096 kanálů, třetí provádí 1000cestnou klasifikaci ILSVRC a obsahuje tedy 1000 kanálů (jeden pro každou třídu). Poslední vrstvou je vrstva soft-max. Konfigurace plně propojených vrstev je ve všech sítích stejná.
Všechny skryté vrstvy jsou vybaveny nelinearitou rektifikace (ReLU). Je třeba také poznamenat, že žádná ze sítí (kromě jedné) neobsahuje normalizaci lokální odezvy (LRN), taková normalizace nezlepšuje výkonnost na datové sadě ILSVRC, ale vede ke zvýšení spotřeby paměti a výpočetního času.
Konfigurace
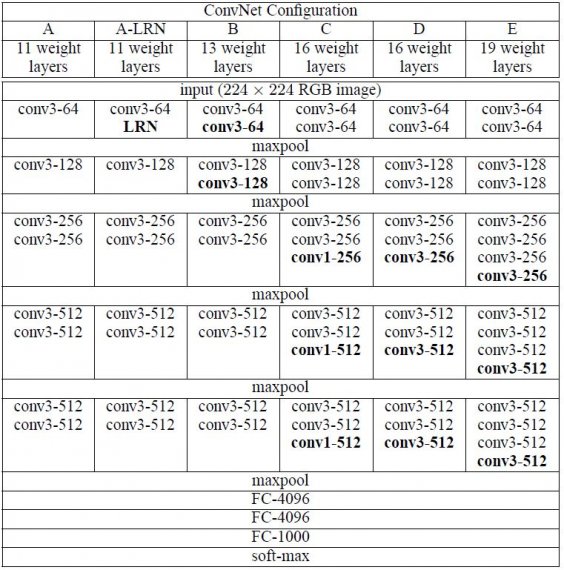
Konfigurace sítě ConvNet jsou nastíněny na obrázku 2. Na obrázku 2 je znázorněna konfigurace sítě ConvNet. Sítě jsou označeny svými názvy (A-E). Všechny konfigurace dodržují obecný návrh přítomný v architektuře a liší se pouze hloubkou: od 11 váhových vrstev v síti A (8 konv. a 3 FC vrstvy) po 19 váhových vrstev v síti E (16 konv. a 3 FC vrstvy). Šířka konv. vrstev (počet kanálů) je poměrně malá, začíná od 64 v první vrstvě a pak se po každé vrstvě max-poolingu zvyšuje o faktor 2, až dosáhne 512.
Případy použití a implementace
Síť VGGNet má bohužel dvě hlavní nevýhody:
- Trénování je bolestivě pomalé.
- Samotné váhy architektury sítě jsou poměrně velké (co se týče disku/šířky pásma).
Díky své hloubce a počtu plně propojených uzlů má síť VGG16 přes 533 MB. Díky tomu je nasazení VGG únavným úkolem.VGG16 se používá v mnoha problémech hlubokého učení klasifikace obrazu; často jsou však žádanější menší architektury sítí (například SqueezeNet, GoogLeNet atd.). Je však skvělým stavebním kamenem pro účely učení, protože se snadno implementuje.
Výsledek
VGG16 výrazně překonává předchozí generaci modelů v soutěžích ILSVRC-2012 a ILSVRC-2013. Výsledek modelu VGG16 konkuruje i vítězi klasifikační úlohy (GoogLeNet s chybou 6,7 %) a výrazně překonává vítězný návrh Clarifai z ILSVRC-2013, který dosáhl 11,2 % s externími trénovacími daty a 11,7 % bez nich. Pokud jde o výkon jednotlivých sítí, architektura VGG16 dosahuje nejlepšího výsledku (7,0% chyba testu) a překonává jediný GoogLeNet o 0,9 %.
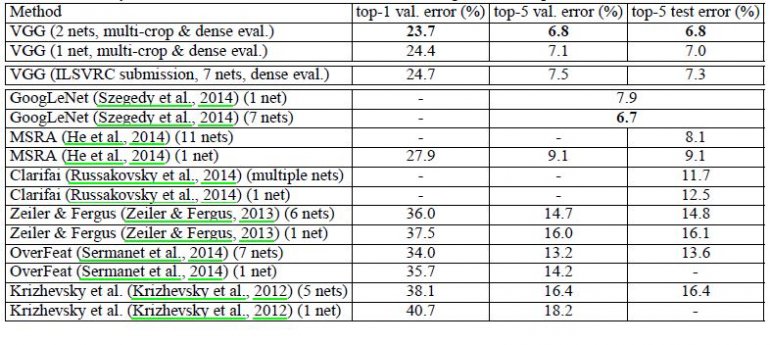
Bylo prokázáno, že hloubka reprezentace je pro klasifikační přesnost přínosná a že nejmodernějšího výkonu na datové sadě úlohy ImageNet lze dosáhnout pomocí konvenční architektury ConvNet s podstatně větší hloubkou.
.