Reddit AmItheAsshole je milejší k ženám než k mužům – důkaz SQL?
Když se redditoři ptají „jsem já ten debil“ a přitom mluví o ženách, mají větší šanci, že budou jako debil vyhodnoceni. Podívejme se na tyto metriky – pomocí BigQuery, dbt a Data Studio
Ujistěte se, že nic z toho, co jsem zde napsal, neberete jako absolutní pravdu. Několik lidí na Twitteru upozornilo na problémy a doplnilo mnou nabízenou analýzu o opravy. Přečtení tohoto příspěvku v původním znění – a reakcí na něj – pro vás může být skvělým způsobem, jak se dozvědět stejně jako já při čtení reakcí. Mnoho jejich nefiltrovaných myšlenek najdete, když budete sledovat toto vlákno na Twitteru.
Kontext
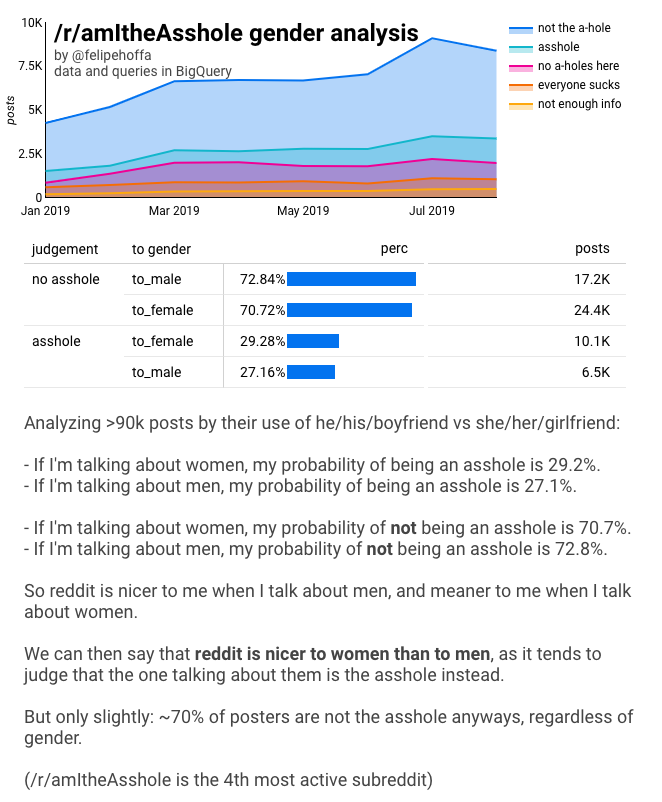
/r/amItheAsshole se rozrostl na čtvrtý nejaktivnější subreddit – podle počtu komentářů. Lidé na tento subreddit chodí vyprávět své příběhy a ptají se ostatních redditorů „jsem tady já ten debil?“. Ukázalo se, že většina lidí je hodnocena jako „ne kretén“, jak je vidět z tohoto grafu:
Můj tweet s těmito výsledky vzbudil velkou pozornost:
Včetně otázky – je reddit milejší k ženám nebo k mužům?
Rozhodování o pohlaví
Při pohledu na název nebo obsah příspěvku můžete mít problém rozhodnout, zda „já“ je muž nebo žena – ale je celkem snadné spočítat počet „ona/on/jeho/přítelkyně/přítele“ přítomných v příběhu.
Podívejme se na několik náhodných příspěvků a počet jednotlivých zájmen a rodových slov:

Vidíme, že počet rodových zájmen a slov v příkladu odpovídá tomu, o kom je příběh. Tyto příběhy jsou o zákazníkovi mužského pohlaví, přítelkyni ženského pohlaví, sousedovi mužského pohlaví, synovi mužského pohlaví a dospívající dceři ženského pohlaví.
Pomocí těchto počtů můžeme nyní stanovit libovolné pravidlo: Pokud je v příspěvku více než dvojnásobný počet zájmen mužského pohlaví než ženského, je tento příspěvek o muži. Pomocí opačného pravidla můžeme říci, že příspěvek je o ženě. Pokud jsou počty příliš blízké nebo nulové, označíme příspěvek za „neutrální“.
Další pravidlo, které můžeme nastavit pro zjednodušení analýzy:
- Pokud je úsudek „není to debil“ nebo „nejsou tu žádní debilové“, pak můžeme říci, že „poster není debil“.
- Jestliže je úsudek ‚kretén‘ nebo ‚všichni jsou tu na hovno‘, pak můžeme říci ‚plakátující je kretén‘.
Pokud všechny tyto příspěvky shrneme, dostaneme se k číslům:

Když jsem tyto výsledky prezentoval poprvé, bylo mi řečeno: „ta čísla jsou příliš blízko, může jít o statistickou chybu.“
Statistická významnost?“
Jak můžeme říct, že ta čísla nejsou pouhou statistickou chybou? Podívejme se na trend po jednotlivých měsících – je stabilní?“

Ano! Trend se v jednotlivých měsících liší, ale když se mluví o ženách, je jednoznačně vyšší šance, že budou za blbce, než když se mluví o mužích. Pokud by tento malý rozdíl byl jen statistickou náhodou, očekávali bychom, že trend místo toho divoce vyskočí.
A všimněte si prosím, že tyto výsledky jsou velmi specifické, jak poznamenává tento tweet:
Na což jsem odpověděl
Jak na to
Tentokrát poprvé používám dbt a celý kód jsem nechal na GitHubu. Děkuji Claire Carroll za pomoc při začátcích s tímto úžasným nástrojem!
Pro extrakci všech příspěvků /r/AmItheAsshole v BigQuery do nové tabulky můžete udělat:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Poté lze pohlaví a úsudek pro každý příspěvek určit dotazem jako:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
A nakonec zde prezentované statistiky:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Diskuse
Na twitterovém vlákně k tomuto příspěvku najdete spoustu zasvěcených a zábavných odpovědí:
Neváhejte se zapojit do diskuse (a říct mi, jestli se mýlím?). Nezapomeňte se k sobě chovat hezky – většina lidí stejně není kretén.
Chcete víc?“
Zakrýval jsem jen do srpna 2019, protože v té době končí současný úplný archiv redditu v BigQuery – do budoucích očekávaných aktualizací. Další podrobnosti o sběru živých dat z pushshift.io najdete v mém předchozím příspěvku. Děkuji Jasonu Baumgartnerovi za neustálý přísun!“
Jmenuji se Felipe Hoffa a pracuji jako Developer Advocate pro Google Cloud. Sledujte mě na @felipehoffa, mé předchozí příspěvky najdete na medium.com/@hoffa a vše o BigQuery na reddit.com/r/bigquery.