Big Data a Hadoop Ecosystem Tutorial
Vítejte na první lekci ‚Big Data a Hadoop Ecosystem‘ výukového kurzu Big Data Hadoop, který je součástí kurzu ‚Big Data Hadoop and Spark Developer Certification course‘ nabízeného společností Simplilearn. Tato lekce je úvodem do ekosystému Big Data a Hadoop. V další části se budeme zabývat cíli této lekce.
Cíle
Po absolvování této lekce budete umět:
-
Pochopit pojem Big Data a jeho problémy
-
Vysvětlit, co jsou Big Data
-
Vysvětlit, co je Hadoop. a jak řeší výzvy spojené s Big Data
-
Popsat ekosystém Hadoop
Podívejme se nyní na přehled Big Data a Hadoop.
Přehled k Big Data a Hadoop
Před rokem 2000 byla data relativně malá než v současnosti, nicméně výpočet dat byl složitý. Veškeré výpočty dat byly závislé na výpočetním výkonu dostupných počítačů.
Později, jak data rostla, bylo řešením mít počítače s velkou pamětí a rychlými procesory. Po roce 2000 však dat stále přibývalo a původní řešení již nemohlo pomoci.
V posledních několika letech došlo k neuvěřitelné explozi objemu dat. Společnost IBM uvedla, že v roce 2012 bylo každý den vygenerováno 2,5 exabajtu neboli 2,5 miliardy gigabajtů dat.
Níže uvádíme několik statistik naznačujících nárůst objemu dat z časopisu Forbes, září 2015. Každou sekundu je na Googlu provedeno 40 000 vyhledávacích dotazů. Na YouTube se každou minutu nahraje až 300 hodin videa.
Na Facebooku uživatelé odešlou 31,25 milionu zpráv a každou minutu zhlédnou 2,77 milionu videí. Do roku 2017 bude téměř 80 % fotografií pořízeno chytrými telefony.
Do roku 2020 bude nejméně třetina všech dat procházet přes cloud (síť serverů propojených přes internet). Do roku 2020 vznikne každou sekundu přibližně 1,7 megabajtu nových informací pro každého člověka na planetě.
Dat přibývá rychleji než kdykoli předtím. Ke správě těchto stále rostoucích dat můžete použít více počítačů. Místo jednoho stroje vykonávajícího tuto práci můžete použít více strojů. Tomu se říká distribuovaný systém.
Náhled kurzu Big Data Hadoop and Spark Developer Certification si můžete prohlédnout zde!
Podívejme se na příklad, abychom pochopili, jak distribuovaný systém funguje.
Jak funguje distribuovaný systém?
Předpokládejme, že máte jeden stroj, který má čtyři vstupní/výstupní kanály. Rychlost každého kanálu je 100 MB/s a chcete na něm zpracovat jeden terabajt dat.
Zpracování jednoho terabajtu dat bude jednomu stroji trvat 45 minut. Nyní předpokládejme, že jeden terabajt dat zpracuje 100 strojů se stejnou konfigurací.
Zpracování jednoho terabajtu dat bude 100 strojům trvat pouze 45 sekund. Distribuovaným systémům trvá zpracování velkých dat kratší dobu.
Podívejme se nyní na problémy distribuovaného systému.
Problémy distribuovaných systémů
Protože se v distribuovaném systému používá více počítačů, existuje vysoká pravděpodobnost selhání systému. Existuje také omezení šířky pásma.
Složitost programování je také vysoká, protože je obtížné synchronizovat data a procesy. Hadoop se s těmito problémy dokáže vypořádat.
V následující části si objasníme, co je to Hadoop.
Co je to Hadoop?
Hadoop je framework, který umožňuje distribuované zpracování velkých souborů dat v clusterech počítačů pomocí jednoduchých programovacích modelů. Je inspirován technickým dokumentem vydaným společností Google.
Slovo Hadoop nemá žádný význam. Doug Cutting, který Hadoop objevil, jej pojmenoval podle svého syna žlutě zbarveného slona na hraní.
Podívejme se, jak Hadoop řeší tři problémy distribuovaného systému, jako je vysoká pravděpodobnost selhání systému, omezení šířky pásma a složitost programování.
Čtyři klíčové vlastnosti systému Hadoop jsou:
-
Hospodárný: Jeho systémy jsou vysoce hospodárné, protože ke zpracování dat lze použít běžné počítače.
-
Spolehlivý:
-
Škálovatelný: Je spolehlivý, protože ukládá kopie dat na různých strojích a je odolný vůči selhání hardwaru: Je snadno škálovatelný horizontálně i vertikálně. Několik dalších uzlů pomáhá při škálování rámce.
-
Pružný:
Tradičně se data ukládala na centrálním místě a za běhu se posílala procesoru. Tato metoda fungovala dobře pro omezený objem dat.
Moderní systémy však dostávají denně terabajty dat a pro tradiční počítače nebo systém správy relačních databází (RDBMS) je obtížné posílat velké objemy dat k procesoru.
Hadoop přinesl radikální přístup. V systému Hadoop jde program k datům, nikoli naopak. Zpočátku distribuuje data do více systémů a později provádí výpočty tam, kde se data nacházejí.
V následující části si povíme, čím se Hadoop liší od tradičního databázového systému.
Rozdíl mezi tradičním databázovým systémem a Hadoopem
Níže uvedená tabulka vám pomůže rozlišit tradiční databázový systém a Hadoop.
|
Tradiční databázový systém |
Hadoop |
|
Data se ukládají na centrálním místě a za běhu se posílají procesoru. |
V Hadoopu jde program k datům. Zpočátku rozdělí data do více systémů a později spustí výpočet tam, kde se data nacházejí. |
|
Tradiční databázové systémy nelze použít pro zpracování a ukládání značného množství dat(big data). |
Hadoop funguje lépe, když je velikost dat velká. Dokáže efektivně a účinně zpracovávat a ukládat velké množství dat. |
|
Tradiční RDBMS se používají pouze pro správu strukturovaných a polostrukturovaných dat. Nelze jej použít ke správě nestrukturovaných dat. |
Hadoop dokáže zpracovávat a ukládat různá data, ať už strukturovaná, nebo nestrukturovaná. |
Podívejme se na rozdíl mezi tradičními RDBMS a Hadoop pomocí analogie.
Jistě jste si všimli rozdílu ve stylu stravování člověka a tygra. Člověk jí jídlo pomocí lžíce, kdy si jídlo přináší k ústům. Zatímco tygr přiblíží ústa k jídlu.
Nyní, pokud jsou jídlem data a ústy program, styl jídla člověka znázorňuje tradiční RDBMS a styl tygra znázorňuje Hadoop.
Podívejme se v další části na ekosystém Hadoop.
Ekosystém Hadoop
Ekosystém Hadoop Ekosystém Hadoop má ekosystém, který se vyvinul ze tří základních komponent zpracování, správy zdrojů a ukládání. V tomto tématu se seznámíte s komponentami ekosystému Hadoop a s tím, jak plní své role při zpracování velkých objemů dat. Ekosystém
Hadoop se neustále rozrůstá, aby vyhovoval potřebám zpracování velkých objemů dat. Skládá se z následujících dvanácti komponent:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop. MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
V následujících kapitolách se seznámíte s úlohou jednotlivých komponent ekosystému Hadoop.

Pochopíme úlohu jednotlivých komponent ekosystému Hadoop.
Složky ekosystému Hadoop
Začněme první složkou HDFS ekosystému Hadoop.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS je úložná vrstva pro Hadoop.
-
HDFS je vhodný pro distribuované ukládání a zpracování, to znamená, že při ukládání se data nejprve distribuují a pak se zpracovávají.
-
HDFS poskytuje proudový přístup k datům souborového systému.
-
HDFS poskytuje oprávnění k souborům a ověřování.
-
HDFS používá pro interakci s Hadoopem rozhraní příkazového řádku.
Takže co ukládá data v HDFS? Je to HBase, která ukládá data v systému HDFS.
HBase
-
HBase je databáze NoSQL neboli nerelační databáze.
-
HBase je důležitá a používá se hlavně tehdy, když potřebujete náhodný přístup k velkým datům v reálném čase, pro čtení nebo zápis.
-
Zajišťuje podporu velkého objemu dat a vysokou propustnost.
-
V HBase může mít tabulka tisíce sloupců.
Probírali jsme způsob distribuce a ukládání dat. Nyní pochopíme, jak jsou tato data přijímána nebo přenášena do systému HDFS. Přesně to dělá Sqoop.
Co je Sqoop?
-
Sqoop je nástroj určený k přenosu dat mezi Hadoopem a relačními databázovými servery.
-
Slouží k importu dat z relačních databází (například Oracle a MySQL) do systému HDFS a exportu dat ze systému HDFS do relačních databází.
Pokud chcete přijímat data o událostech, například proudová data, data ze senzorů nebo soubory protokolů, můžete použít Flume. Na Flume se podíváme v další části.
Flume
-
Flume je distribuovaná služba, která shromažďuje data událostí a přenáší je do systému HDFS.
-
Ideálně se hodí pro data událostí z více systémů.
Po přenesení dat do systému HDFS se zpracovávají. Jedním z frameworků, které data zpracovávají, je Spark.
Co je Spark?
-
Spark je open source cluster computing framework.
-
Poskytuje až stokrát vyšší výkon pro několik aplikací s in-memory primitivy ve srovnání s dvoustupňovým diskovým paradigmatem MapReduce systému Hadoop.
-
Spark může běžet v clusteru Hadoop a zpracovávat data v HDFS.
-
Podporuje také širokou škálu pracovních zátěží, mezi které patří strojové učení, business intelligence, streaming a dávkové zpracování.
Spark má následující hlavní součásti:
-
Spark Core a Resilient Distributed datasets neboli RDD
-
Spark SQL
-
Spark Streaming
-
Knihovna strojového učení neboli Mlib
-
Graphx.
Spark je v současnosti hojně využíván a více se o něm dozvíte v následujících lekcích.
Hadoop MapReduce
-
Hadoop MapReduce je další framework, který zpracovává data.
-
Jedná se o původní zpracovatelský engine Hadoop, který je primárně založen na jazyku Java.
-
Je založen na programovacím modelu map a reduces.
-
Mnoho nástrojů, například Hive a Pig, je postaveno na modelu mapa-redukce.
-
Má v sobě zabudovanou rozsáhlou a vyspělou odolnost proti chybám.
-
Stále se velmi často používá, ale ztrácí pozici ve srovnání se Sparkem.
Po zpracování dat dochází k jejich analýze. To lze provést pomocí vysokoúrovňového systému pro tok dat s otevřeným zdrojovým kódem, který se nazývá Pig. Používá se hlavně pro analýzu.
Pochopme nyní, jak se Pig používá pro analýzu.
Pig
-
Pig převádí své skripty na kód Map a Reduce, čímž uživateli ušetří psaní složitých programů MapReduce.
-
Ad-hoc dotazy, jako jsou Filter a Join, které se v MapReduce provádějí obtížně, lze snadno provádět pomocí Pig.
-
Pomocí Impaly lze také analyzovat data.
-
Jedná se o open-source vysoce výkonný SQL engine, který běží na clusteru Hadoop.
-
Je ideální pro interaktivní analýzu a má velmi nízkou latenci, kterou lze měřit v milisekundách.
Impala
-
Impala podporuje dialekt jazyka SQL, takže data v systému HDFS jsou modelována jako databázové tabulky.
-
Analýzu dat můžete provádět také pomocí HIVE. Jedná se o abstrakční vrstvu nad systémem Hadoop.
-
Je velmi podobná systému Impala. Je však vhodnější pro zpracování dat a operace Extract Transform Load, známé také jako ETL.
-
Impala je vhodnější pro ad-hoc dotazy.
HIVE
-
HIVE provádí dotazy pomocí MapReduce; uživatel však nemusí psát žádný kód v nízkoúrovňovém MapReduce.
-
Hive je vhodný pro strukturovaná data. Po analýze jsou data připravena pro přístup uživatelů.
Teď, když víme, co HIVE umí, probereme, co podporuje vyhledávání dat. Vyhledávání dat se provádí pomocí Cloudera Search.
Cloudera Search
-
Vyhledávání je jedním z produktů společnosti Cloudera pro přístup téměř v reálném čase. Umožňuje netechnickým uživatelům prohledávat a zkoumat data uložená v systémech Hadoop a HBase nebo do nich vložená.
-
Uživatelé nepotřebují k používání Cloudera Search znalosti SQL nebo programování, protože poskytuje jednoduché fulltextové rozhraní pro vyhledávání.
-
Další výhodou Cloudera Search ve srovnání se samostatnými vyhledávacími řešeními je plně integrovaná platforma pro zpracování dat.
-
Cloudera Search využívá flexibilní, škálovatelný a robustní úložný systém, který je součástí CDH nebo Cloudera Distribution, včetně Hadoop. Díky tomu není nutné přesouvat velké datové sady napříč infrastrukturami, aby bylo možné řešit obchodní úlohy.
-
Úlohy systému Hadoop, jako jsou MapReduce, Pig, Hive a Sqoop, mají pracovní postupy.
Oozie
-
Oozie je pracovní postup nebo koordinační systém, který můžete použít ke správě úloh Hadoop.
Životní cyklus aplikace Oozie je znázorněn na diagramu níže.
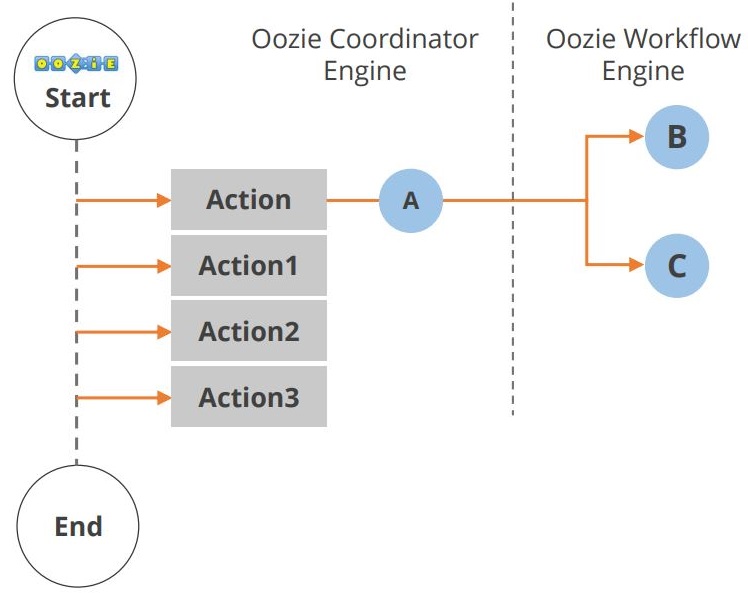 Jak vidíte, mezi začátkem a koncem pracovního postupu dochází k několika akcím. Další komponentou v ekosystému Hadoop je Hue. Podívejme se nyní na Hue.
Jak vidíte, mezi začátkem a koncem pracovního postupu dochází k několika akcím. Další komponentou v ekosystému Hadoop je Hue. Podívejme se nyní na Hue.
Hue
Hue je zkratka pro Hadoop User Experience. Jedná se o open-source webové rozhraní pro Hadoop. Pomocí Hue můžete provádět následující operace:
-
Nahrávat a procházet data
-
Dotazovat se na tabulku v HIVE a Impala
-
Spouštět úlohy a pracovní postupy Spark a Pig Vyhledávat data
-
Celkově Hue usnadňuje používání Hadoopu.
-
Zajišťuje také editor SQL pro HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL a Solr SQL.
Po tomto stručném přehledu dvanácti komponent ekosystému Hadoop si nyní probereme, jak tyto komponenty spolupracují při zpracování velkých dat.
Fáze zpracování velkých dat
Existují čtyři fáze zpracování velkých dat: Zpracování, Analýza, Přístup. Podívejme se na ně podrobněji.
Ingest
První fází zpracování Big Data je Ingest. Data jsou do systému Hadoop přijímána nebo přenášena z různých zdrojů, jako jsou relační databáze, systémy nebo místní soubory. Sqoop přenáší data z RDBMS do HDFS, zatímco Flume přenáší data událostí.
Processing
Druhou fází je Processing. V této fázi se data ukládají a zpracovávají. Data jsou uložena v distribuovaném souborovém systému HDFS a v distribuované databázi NoSQL HBase. Zpracování dat provádí Spark a MapReduce.
Analyze
Třetí fází je Analýza. Zde se data analyzují pomocí zpracovatelských rámců, jako jsou Pig, Hive a Impala.
Pig převádí data pomocí map a reduce a poté je analyzuje. Hive je také založen na programování map and reduce a je nejvhodnější pro strukturovaná data.
Přístup
Čtvrtou fází je Přístup, který provádějí nástroje jako Hue a Cloudera Search. V této fázi mohou uživatelé přistupovat k analyzovaným datům.
Hue je webové rozhraní, zatímco Cloudera Search poskytuje textové rozhraní pro zkoumání dat.
Podívejte se na certifikační kurz Big Data Hadoop a Spark Developer zde!
Shrnutí
Nechte nás nyní shrnout, co jsme se v této lekci naučili.
-
Hadoop je framework pro distribuované ukládání a zpracování dat.
-
Mezi základní komponenty Hadoopu patří HDFS pro ukládání, YARN pro správu clusterových zdrojů a MapReduce nebo Spark pro zpracování.
-
Ekosystém Hadoopu zahrnuje několik komponent, které podporují jednotlivé fáze zpracování velkých dat.
-
Flume a Sqoop přijímají data, HDFS a HBase ukládají data, Spark a MapReduce zpracovávají data, Pig, Hive a Impala analyzují data, Hue a Cloudera Search pomáhají data zkoumat.
-
Oozie řídí pracovní postupy úloh Hadoop.
Závěr
Tímto končí lekce o velkých datech a ekosystému Hadoop. V příští lekci probereme systémy HDFS a YARN.
Najděte si naše školení Big Data Hadoop a Spark Developer Online Classroom v nejlepších městech:
| Název | Datum | Místo | |
|---|---|---|---|
| Big Data Hadoop and Spark Developer | 3. dubna – 15. května 2021, Víkendová dávka | Vaše město | Zobrazit podrobnosti |
| Big Data Hadoop and Spark Developer | 12. 4.-4. 5. 2021, Všední dny dávka | Vaše město | Zobrazit podrobnosti |
| Big Data Hadoop and Spark Developer | 24. dubna -5. června 2021, Víkendová dávka | Vaše město | Zobrazit podrobnosti |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Chcete-li se dozvědět více, zúčastněte se kurzu
Big Data Hadoop and Spark Developer Certification Training
Go to Course
To learn more, absolvovat kurz
Big Data Hadoop and Spark Developer Certification Training Přejít na kurz
.