Utilizarea rețelelor neuronale convoluționale pentru recunoașterea imaginilor
Acest articol a fost publicat inițial pe site-ul web al Cadence. El este retipărit aici cu permisiunea Cadence.
Rețelele neuronale convoluționale (CNN) sunt utilizate pe scară largă în problemele de recunoaștere a modelelor și a imaginilor, deoarece au o serie de avantaje în comparație cu alte tehnici. Această carte albă acoperă elementele de bază ale CNN-urilor, inclusiv o descriere a diferitelor straturi utilizate. Folosind recunoașterea semnelor de circulație ca exemplu, discutăm provocările problemei generale și prezentăm algoritmi și software de implementare dezvoltați de Cadence care pot face schimb de sarcină de calcul și energie pentru o degradare modestă a ratelor de recunoaștere a semnelor. Descriem provocările legate de utilizarea CNN-urilor în sistemele încorporate și prezentăm caracteristicile cheie ale procesorului de semnal digital (DSP) Cadence® Tensilica® Vision P5 pentru imagistică și viziune computerizată și ale software-ului care îl fac atât de potrivit pentru aplicațiile CNN în numeroase sarcini de imagistică și de recunoaștere aferente.
Ce este un CNN?
O rețea neuronală este un sistem de „neuroni” artificiali interconectați care schimbă mesaje între ei. Conexiunile au ponderi numerice care sunt reglate în timpul procesului de instruire, astfel încât o rețea instruită corespunzător va răspunde corect atunci când i se prezintă o imagine sau un model de recunoscut. Rețeaua este formată din mai multe straturi de „neuroni” care detectează caracteristici. Fiecare strat are mai mulți neuroni care răspund la diferite combinații de intrări de la straturile anterioare. După cum se arată în figura 1, straturile sunt construite astfel încât primul strat detectează un set de modele primitive în intrare, al doilea strat detectează modele de modele, al treilea strat detectează modele ale acestor modele și așa mai departe. CNN-urile tipice utilizează între 5 și 25 de straturi distincte de recunoaștere a tiparelor.
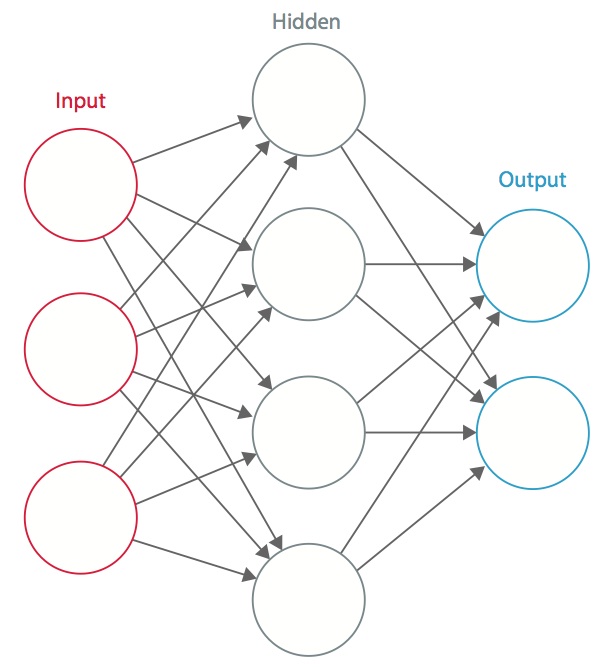
Figura 1: O rețea neuronală artificială
Învățarea se realizează utilizând un set de date „etichetate” de intrări într-un sortiment larg de tipare de intrare reprezentative care sunt etichetate cu răspunsul lor de ieșire preconizat. Învățarea utilizează metode de uz general pentru a determina în mod iterativ ponderile pentru neuronii caracteristici intermediare și finale. Figura 2 demonstrează procesul de instruire la nivel de bloc.
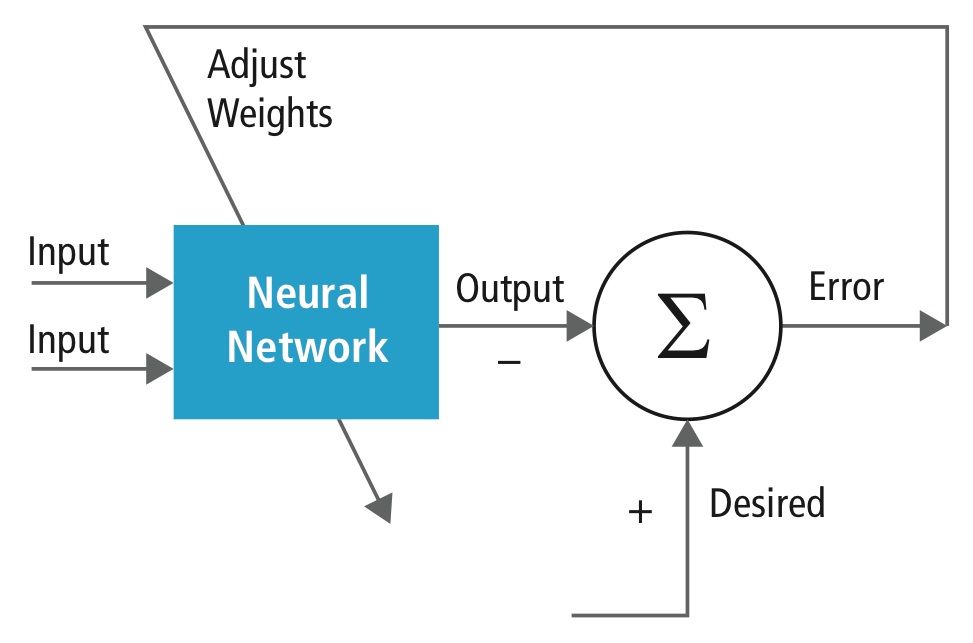
Figura 2: Instruirea rețelelor neuronale
Rețelele neuronale sunt inspirate de sistemele neuronale biologice. Unitatea de calcul de bază a creierului este un neuron, iar aceștia sunt conectați cu sinapse. Figura 3 compară un neuron biologic cu un model matematic de bază .


Figura 3: Ilustrație a unui neuron biologic (sus) și a modelului său matematic (jos)
Într-un sistem neuronal animal real, un neuron este perceput ca primind semnale de intrare de la dendritele sale și producând semnale de ieșire de-a lungul axonului său. Axonul se ramifică și se conectează prin sinapse la dendritele altor neuroni. Atunci când combinația de semnale de intrare atinge o anumită condiție de prag printre dendritele sale de intrare, neuronul este declanșat și activarea sa este comunicată neuronilor succesori.
În modelul de calcul al rețelei neuronale, semnalele care se deplasează de-a lungul axonilor (de exemplu, x0) interacționează multiplicativ (de exemplu, w0x0) cu dendritele celuilalt neuron pe baza intensității sinaptice la sinapsa respectivă (de exemplu, w0). Ponderile sinaptice pot fi învățate și controlează influența unui neuron sau a altuia. Dendritele transportă semnalul către corpul celular, unde toate sunt însumate. Dacă suma finală este peste un prag specificat, neuronul se declanșează, trimițând un vârf de-a lungul axonului său. În modelul de calcul, se presupune că momentul precis al declanșării nu contează și că doar frecvența de declanșare comunică informații. Pe baza interpretării codului de rată, rata de aprindere a neuronului este modelată cu o funcție de activare ƒ care reprezintă frecvența vârfurilor de-a lungul axonului. O alegere obișnuită a funcției de activare este cea sigmoidă. Pe scurt, fiecare neuron calculează produsul punctual al intrărilor și al ponderilor, adaugă polarizarea și aplică neliniaritatea ca funcție de activare (de exemplu, urmând o funcție de răspuns sigmoidă).
Un CNN este un caz special al rețelei neuronale descrise mai sus. Un CNN este format din unul sau mai multe straturi convoluționale, adesea cu un strat de subeșantionare, care sunt urmate de unul sau mai multe straturi complet conectate, ca într-o rețea neuronală standard.
Proiectarea unui CNN este motivată de descoperirea unui mecanism vizual, cortexul vizual, în creier. Cortexul vizual conține o mulțime de celule care sunt responsabile pentru detectarea luminii în subregiuni mici și suprapuse ale câmpului vizual, care se numesc câmpuri receptive. Aceste celule acționează ca filtre locale asupra spațiului de intrare, iar celulele mai complexe au câmpuri receptive mai mari. Stratul de convoluție dintr-un CNN îndeplinește funcția care este îndeplinită de celulele din cortexul vizual .
Un CNN tipic pentru recunoașterea semnelor de circulație este prezentat în figura 4. Fiecare trăsătură a unui strat primește intrări de la un set de trăsături situate într-o vecinătate mică în stratul anterior, numită câmp receptiv local. Cu ajutorul câmpurilor receptive locale, caracteristicile pot extrage caracteristici vizuale elementare, cum ar fi marginile orientate, punctele de capăt, colțurile etc., care sunt apoi combinate de către straturile superioare.
În modelul tradițional de recunoaștere a modelelor/imaginilor, un extractor de caracteristici proiectat manual adună informațiile relevante de la intrare și elimină variabilitățile irelevante. Extractorul este urmat de un clasificator antrenabil, o rețea neuronală standard care clasifică vectorii de caracteristici în clase.
Într-un CNN, straturile de convoluție joacă rolul de extractor de caracteristici. Dar ele nu sunt proiectate manual. Ponderile nucleului filtrului de convoluție sunt decise ca parte a procesului de instruire. Straturile de convoluție sunt capabile să extragă caracteristicile locale deoarece restricționează câmpurile receptive ale straturilor ascunse pentru a fi locale.
Figura 4: Schema bloc tipică a unui CNN
CNN-urile sunt utilizate în diverse domenii, inclusiv recunoașterea imaginilor și a modelelor, recunoașterea vorbirii, procesarea limbajului natural și analiza video. Există o serie de motive pentru care rețelele neuronale convoluționale devin importante. În modelele tradiționale de recunoaștere a tiparelor, extractorii de caracteristici sunt proiectați manual. În cazul rețelelor CNN, ponderile stratului convoluțional utilizat pentru extragerea caracteristicilor, precum și ale stratului complet conectat utilizat pentru clasificare sunt determinate în timpul procesului de instruire. Structurile de rețea îmbunătățite ale CNN-urilor conduc la economii în ceea ce privește cerințele de memorie și cerințele de complexitate a calculului și, în același timp, oferă performanțe mai bune pentru aplicațiile în care datele de intrare au o corelație locală (de exemplu, imagine și vorbire).
Cerințele mari de resurse de calcul pentru instruirea și evaluarea CNN-urilor sunt uneori satisfăcute de unități de procesare grafică (GPU), DSP-uri sau alte arhitecturi de siliciu optimizate pentru un randament ridicat și un consum redus de energie atunci când se execută modelele idiosincratice de calcul ale CNN-urilor. De fapt, procesoarele avansate, cum ar fi Tensilica Vision P5 DSP for Imaging and Computer Vision de la Cadence, au un set aproape ideal de resurse de calcul și de memorie necesare pentru a rula CNN-uri la o eficiență ridicată.
În aplicațiile de recunoaștere a modelelor și a imaginilor, cele mai bune rate de detecție corectă (CDR) posibile au fost obținute cu ajutorul CNN-urilor. De exemplu, CNN-urile au obținut un CDR de 99,77% folosind baza de date MNIST de cifre scrise de mână , un CDR de 97,47% cu setul de date NORB de obiecte 3D și un CDR de 97,6% pe ~5600 de imagini cu mai mult de 10 obiecte . CNN-urile nu numai că oferă cele mai bune performanțe în comparație cu alți algoritmi de detecție, dar depășesc chiar și performanțele oamenilor în cazuri precum clasificarea obiectelor în categorii cu granulație fină, cum ar fi rasa particulară de câine sau specia de pasăre .
Figura 5 prezintă o conductă tipică a algoritmilor de viziune, care constă din patru etape: preprocesarea imaginii, detectarea regiunilor de interes (ROI) care conțin obiecte probabile, recunoașterea obiectelor și luarea deciziilor de viziune. Etapa de preprocesare depinde, de obicei, de detaliile datelor de intrare, în special de sistemul de camere, și este adesea implementată într-o unitate cablată în afara subsistemului de viziune. Procesul de luare a deciziilor de la capătul pipeline-ului operează de obicei cu obiecte recunoscute – poate lua decizii complexe, dar operează cu mult mai puține date, astfel încât aceste decizii nu sunt, de obicei, probleme dificile din punct de vedere computațional sau care necesită multă memorie. Marea provocare este în etapele de detectare și recunoaștere a obiectelor, unde CNN-urile au în prezent un impact larg.

Figura 5: Filiera algoritmilor de viziune
Câmpuri de CNN-uri
Prin suprapunerea de straturi multiple și diferite într-un CNN, se construiesc arhitecturi complexe pentru probleme de clasificare. Patru tipuri de straturi sunt cele mai comune: straturi de convoluție, straturi de grupare/subeșantionare, straturi neliniare și straturi complet conectate.
Capacități de convoluție
Operațiunea de convoluție extrage diferite caracteristici ale datelor de intrare. Primul strat de convoluție extrage caracteristicile de nivel scăzut, cum ar fi marginile, liniile și colțurile. Straturile de nivel superior extrag caracteristicile de nivel superior. Figura 6 ilustrează procesul de convoluție 3D utilizat în CNN-uri. Intrarea are dimensiunea N x N x D și este convolvată cu H nuclee, fiecare de
dimensiunea k x k x D separat. Convoluția unei intrări cu un nucleu produce o caracteristică de ieșire, iar cu H nuclee produce independent H caracteristici. Începând din colțul din stânga sus al intrării, fiecare nucleu este deplasat de la stânga la dreapta, câte un element la un moment dat. După ce se ajunge la colțul din dreapta sus, nucleul este deplasat cu un element în jos și, din nou, nucleul este deplasat de la stânga la dreapta, câte un element pe rând. Acest proces se repetă până când
nodul ajunge în colțul din dreapta jos. Pentru cazul în care N = 32 și k = 5 , există 28 de poziții unice de la stânga la dreapta și 28 de poziții unice de sus în jos pe care le poate lua nucleul. Corespunzând acestor poziții, fiecare caracteristică de la ieșire va conține 28×28 (adică (N-k+1) x (N-k+1)) elemente. Pentru fiecare poziție a nucleului într-un proces de fereastră glisantă, k x k x D elemente de intrare și k x k x D elemente ale nucleului sunt înmulțite și acumulate element cu element. Astfel, pentru a crea un element al unei caracteristici de ieșire, sunt necesare k x k x D operații de multiplicare-acumulare.
Figura 6: Reprezentarea picturală a procesului de convoluție
Capacități de grupare/subeșantionare
Capacitatea de grupare/subeșantionare reduce rezoluția caracteristicilor. Acesta face ca caracteristicile să fie rezistente la zgomot și distorsiuni. Există două moduri de a face pooling: pooling maxim și pooling mediu. În ambele cazuri, datele de intrare sunt împărțite în spații bidimensionale care nu se suprapun. De exemplu, în figura 4, stratul 2 este stratul de centralizare. Fiecare caracteristică de intrare are o dimensiune de 28×28 și este împărțită în 14×14 regiuni de 2×2. Pentru punerea în comun medie, se calculează media celor patru valori din regiune. În cazul grupării maxime, se selectează valoarea maximă dintre cele patru valori.
Figura 7 detaliază procesul de grupare. Intrarea este de dimensiune 4×4. Pentru subeșantionarea 2×2, o imagine 4×4 este împărțită în patru matrici care nu se suprapun de dimensiune 2×2. În cazul unei grupări maxime, valoarea maximă a celor patru valori din matricea 2×2 reprezintă ieșirea. În cazul grupării medii, rezultatul este media celor patru valori. Vă rugăm să rețineți că, în cazul ieșirii cu indicele (2,2), rezultatul calculării mediei este o fracție care a fost rotunjită la cel mai apropiat număr întreg.
Figura 7: Reprezentarea picturală a punerii în comun maxime și a punerii în comun medii
Câmpuri neliniare
Rețelele neuronale, în general, și CNN-urile, în special, se bazează pe o funcție de „declanșare” neliniară pentru a semnala identificarea distinctă a caracteristicilor probabile în fiecare strat ascuns. CNN-urile pot utiliza o varietate de funcții specifice – cum ar fi unitățile liniare rectificate (ReLU) și funcțiile de declanșare continuă (neliniară) – pentru a implementa eficient această declanșare neliniară.
ReLU
Un ReLU implementează funcția y = max(x,0), astfel încât dimensiunile de intrare și de ieșire ale acestui strat sunt aceleași. Aceasta mărește proprietățile neliniare ale funcției de decizie și ale rețelei în ansamblu, fără a afecta câmpurile receptive ale stratului de convoluție. În comparație cu alte funcții neliniare utilizate în CNN-uri (de exemplu, tangenta hiperbolică, absolutul tangentei hiperbolice și sigmoidul), avantajul ReLU este că rețeaua se antrenează de multe ori mai repede. Funcționalitatea ReLU este ilustrată în figura 8, cu funcția sa de transfer reprezentată grafic deasupra săgeții.
Figura 8: Reprezentare picturală a funcționalității ReLU
Funcția de declanșare continuă (neliniară)
Stratul neliniar operează element cu element în fiecare caracteristică. O funcție de declanșare continuă poate fi tangentă hiperbolică (figura 9), absolută a tangentei hiperbolice (figura 10) sau sigmoidă (figura 11). Figura 12 demonstrează modul în care se aplică neliniaritatea element cu element.
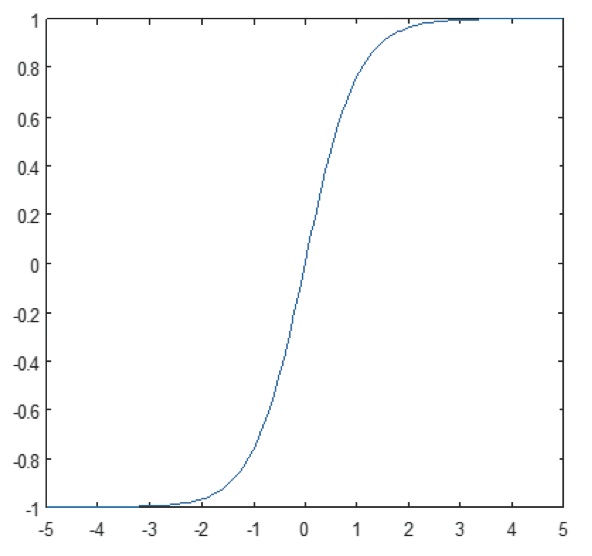
Figura 9: Reprezentarea grafică a funcției tangentă hiperbolică
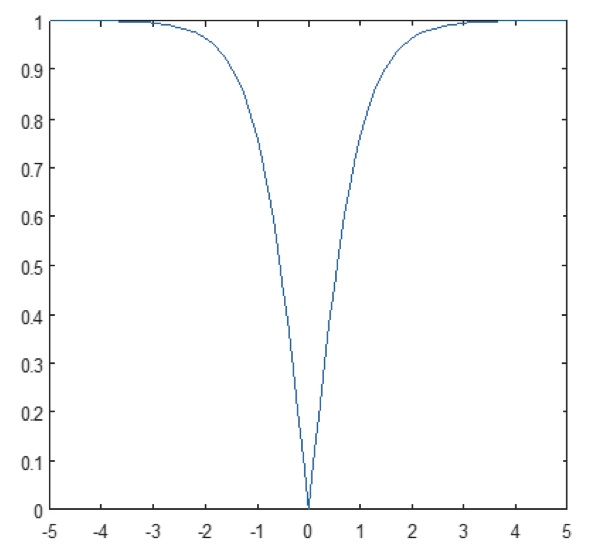
Figura 10: Reprezentarea grafică a funcției tangentă absolută a tangentei hiperbolice
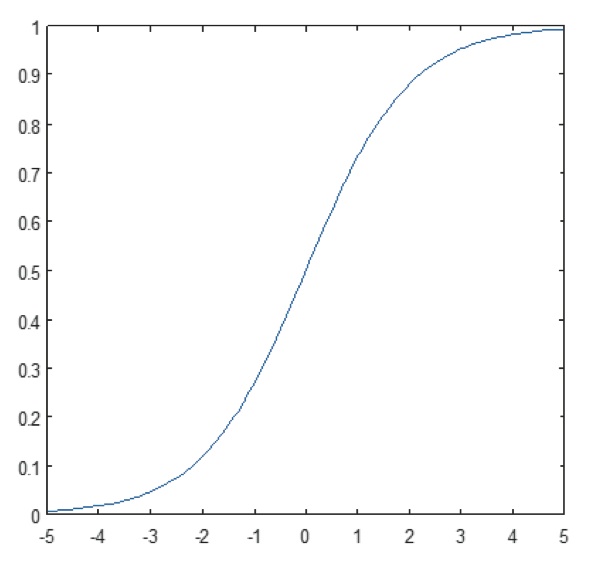
Figura 11: Reprezentarea grafică a funcției tangentă hiperbolică: Graficul funcției sigmoide
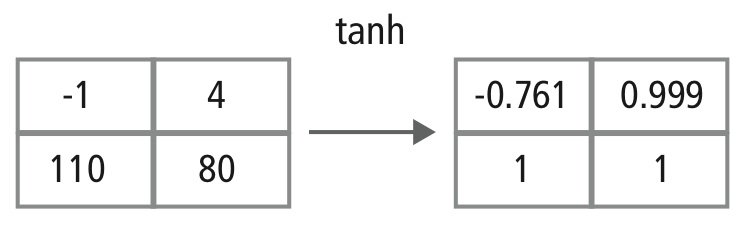
Figura 12: Reprezentare picturală a procesării tanh
Capacități complet conectate
Capacitățile complet conectate sunt adesea folosite ca straturi finale ale unui CNN. Aceste straturi însumează matematic o pondere a stratului anterior de caracteristici, indicând amestecul precis de „ingrediente” pentru a determina un rezultat de ieșire țintă specific. În cazul unui strat complet conectat, toate elementele tuturor trăsăturilor din stratul anterior sunt utilizate în calculul fiecărui element al fiecărei trăsături de ieșire.
Figura 13 explică stratul complet conectat L. Stratul L-1 are două trăsături, fiecare dintre acestea fiind de 2×2, adică are patru elemente. Stratul L are două caracteristici, fiecare având un singur element.
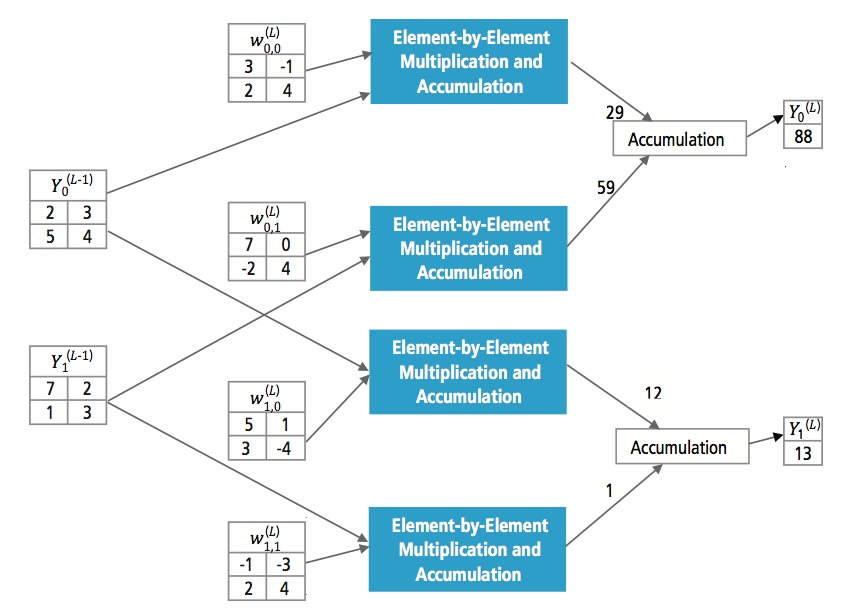
Figura 13: Prelucrarea unui strat complet conectat
De ce CNN?
În timp ce rețelele neuronale și alte metode de detectare a modelelor au existat în ultimii 50 de ani, în ultimul timp a existat o dezvoltare semnificativă în domeniul rețelelor neuronale convoluționale. Această secțiune se referă la avantajele utilizării CNN pentru recunoașterea imaginilor.
Rezistența la modificări și distorsiuni ale imaginii
Detecția cu ajutorul CNN este rezistentă la distorsiuni, cum ar fi modificarea formei datorată obiectivului aparatului de fotografiat, condiții diferite de iluminare, poziții diferite, prezența unor ocluzii parțiale, deplasări orizontale și verticale etc. Cu toate acestea, CNN-urile sunt invariante în ceea ce privește deplasarea, deoarece aceeași configurație de ponderare este utilizată în tot spațiul. Teoretic, se poate obține invarianța la deplasare și cu ajutorul straturilor complet conectate. Dar, în acest caz, rezultatul formării este reprezentat de mai multe unități cu configurații de greutate identice în diferite locații ale intrării. Pentru a învăța aceste configurații de ponderi, ar fi necesar un număr mare de instanțe de instruire pentru a acoperi spațiul variațiilor posibile.
Cerințe de memorie mai mici
În același caz ipotetic în care folosim un strat complet conectat pentru a extrage caracteristicile, imaginea de intrare de dimensiune 32×32 și un strat ascuns având 1000 de caracteristici vor necesita un ordin de 106 coeficienți, o cerință de memorie uriașă. În stratul convoluțional, aceiași coeficienți sunt utilizați în diferite locații din spațiu, astfel încât necesarul de memorie se reduce drastic.
Încă o antrenare mai ușoară și mai bună
Încă o dată cu utilizarea rețelei neuronale standard care ar fi echivalentă cu un CNN, deoarece numărul de parametrii ar fi mult mai mare, timpul de antrenare ar crește, de asemenea, proporțional. În cazul unui CNN, deoarece numărul de parametri este drastic redus, timpul de instruire este redus în mod proporțional. De asemenea, presupunând o instruire perfectă, putem proiecta o rețea neuronală standard a cărei performanță ar fi aceeași cu cea a unui CNN. Dar, în practică,
o rețea neuronală standard echivalentă cu CNN ar avea mai mulți parametri, ceea ce ar duce la un plus de zgomot în timpul procesului de formare. Prin urmare, performanța unei rețele neuronale standard echivalente cu un CNN va fi întotdeauna mai slabă.
Algoritm de recunoaștere pentru setul de date GTSRB
The German Traffic Sign Recognition Benchmark (GTSRB) a fost o provocare de clasificare a mai multor clase și a unei singure imagini, organizată în cadrul International Joint Conference on Neural Networks (IJCNN) 2011, cu următoarele cerințe:
- 51 840 de imagini ale semnelor rutiere germane în 43 de clase (figurile 14 și 15)
- Dimensiunea imaginilor variază de la 15×15 la 222×193
- Imaginile sunt grupate pe clase și pe piste, cu cel puțin 30 de imagini pe pistă
- Imaginile sunt disponibile ca imagini color (RGB), caracteristici HOG, caracteristici Haar și histograme de culoare
- Concurența este doar pentru algoritmul de clasificare; algoritmul pentru a găsi regiunea de interes din cadru nu este necesar
- Informația temporală a secvențelor de testare nu este partajată, astfel încât dimensiunea temporală nu poate fi utilizată în algoritmul de clasificare

Figura 14: Semne de circulație ideale GTSRB

Figura 15: Semne de circulație GTSRB cu deficiențe
Algoritmul Cadence pentru recunoașterea semnelor de circulație în setul de date GTSRB
Cadence a dezvoltat diverși algoritmi în MATLAB pentru recunoașterea semnelor de circulație utilizând setul de date GTSRB, pornind de la o configurație de bază bazată pe o lucrare binecunoscută privind recunoașterea semnelor . Rata de detectare corectă de 99,24% și efortul de calcul de aproape >50 de milioane de multiplicații-adăugări per semn sunt prezentate ca un punct verde gros în figura 16. Cadence a obținut rezultate semnificativ mai bune folosind noua noastră abordare proprietară Hierarchical CNN. În acest algoritm, 43 de semne de circulație au fost împărțite în cinci familii. În total, am implementat șase CNN-uri mai mici. Primul CNN decide din ce familie face parte semnul de trafic primit. Odată ce familia semnului este cunoscută, este rulat CNN-ul (unul dintre cele cinci rămase) corespunzător familiei detectate pentru a decide care este semnul de circulație din familia respectivă. Folosind acest algoritm, Cadence a obținut o rată de detecție corectă de 99,58%, cea mai bună CDR obținută până în prezent pe GTSRB.
Algoritm for Performance vs. Complexity Tradeoff
Pentru a controla complexitatea CNN-urilor în aplicațiile integrate, Cadence a dezvoltat, de asemenea, un algoritm proprietar care utilizează descompunerea valorilor proprii care reduce un CNN antrenat la dimensiunea sa canonică. Folosind acest algoritm, am reușit să reducem drastic complexitatea CNN-ului fără nicio degradare a performanțelor sau cu o mică reducere controlată a CDR-ului. Figura 16 prezintă rezultatele obținute:
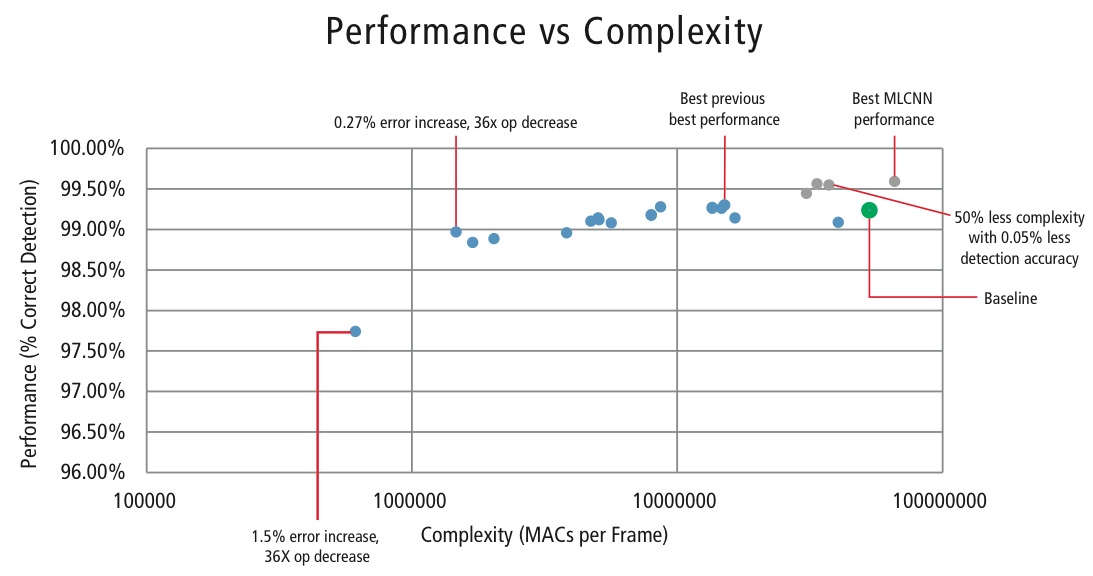
Figura 16: Graficul de performanță în funcție de complexitate pentru diferite configurații CNN pentru detectarea semnelor de circulație în setul de date GTSRB
Punctul verde din figura 16 reprezintă configurația de bază. Această configurație este destul de apropiată de configurația sugerată în Referința . Aceasta necesită 53 MMAC pe cadru pentru o rată de eroare de 0,76%.
- Cel de-al doilea punct din stânga necesită 1,47 milioane de MAC pe cadru pentru o rată de eroare de 1,03%, adică, pentru o creștere a ratei de eroare de 0,27%, necesarul de MAC a fost redus de un factor de 36,14.
- Punctul din stânga necesită 0,61 MMAC pe cadru pentru atingerea unei rate de eroare de 2,26%, adică numărul de MAC este redus de un factor de 86,4 ori.
- Punctele în albastru sunt pentru un CNN cu un singur nivel, în timp ce punctele în roșu sunt pentru un CNN ierarhic. O performanță în cel mai bun caz de 99,58% este obținută de CNN-ul ierarhic.
CNNs in Embedded Systems
Așa cum se arată în figura 5, un subsistem de viziune necesită o mulțime de procesare a imaginii în plus față de un CNN. Pentru a rula CNN-uri pe un sistem încorporat cu consum redus de energie care suportă procesarea imaginilor, acesta ar trebui să îndeplinească următoarele cerințe:
- Disponibilitatea unei performanțe de calcul ridicate: Pentru o implementare tipică a unui CNN, sunt necesare miliarde de MAC-uri pe secundă.
- Lărgime de bandă mai mare de încărcare/stocare: În cazul unui strat complet conectat utilizat în scopul clasificării, fiecare coeficient este utilizat în multiplicare o singură dată. Astfel, cerința de lățime de bandă de încărcare-stocare este mai mare decât numărul de MAC-uri efectuate de procesor.
- Cerință redusă de putere dinamică: Sistemul trebuie să consume mai puțină energie. Pentru a rezolva această problemă, este necesară o implementare în virgulă fixă, care impune cerința de a îndeplini cerințele de performanță utilizând un număr finit minim posibil de biți.
- Flexibilitate: Ar trebui să fie posibilă trecerea cu ușurință de la proiectarea existentă la o nouă proiectare mai performantă.
Din moment ce resursele de calcul sunt întotdeauna o constrângere în sistemele încorporate, dacă cazul de utilizare permite o mică degradare a performanței, este util să se dispună de un algoritm care poate realiza economii uriașe în ceea ce privește complexitatea de calcul cu prețul unei mici degradări controlate a performanței. Așadar, activitatea Cadence privind un algoritm care să realizeze un compromis între complexitate și performanță, așa cum s-a explicat în secțiunea anterioară, are o mare relevanță pentru implementarea CNN-urilor în sistemele încorporate.
CNN-uri pe procesoare Tensilica
Procesorul Tensilica Vision P5 DSP este un DSP de înaltă performanță, cu consum redus de energie, conceput special pentru procesarea imaginilor și a vederii computerizate. DSP-ul are o arhitectură VLIW cu suport SIMD. Are cinci sloturi de emitere într-un cuvânt de instrucțiuni de până la 96 de biți și poate încărca până la 1024 de biți de cuvinte din memorie în fiecare ciclu. Registrele interne și unitățile de operare variază de la 512 biți la 1536 de biți, unde datele sunt reprezentate ca 16, 32 sau 64 de felii de date de 8b, 16b, 24b, 32b sau 48b pixeli.
DSP-ul abordează toate provocările pentru implementarea CNN-urilor în sistemele încorporate, așa cum s-a discutat în secțiunea anterioară.
- Disponibilitatea unei performanțe de calcul ridicate: În plus față de suportul avansat pentru implementarea procesării semnalelor de imagine, DSP-ul are suport de instrucțiuni pentru toate etapele CNN-urilor. Pentru operațiile de convoluție, acesta dispune de un set de instrucțiuni foarte bogat care suportă operații de multiplicare/multiplicare-acumulare care suportă operații 8b x 8b, 8b x 16b și 16b x 16b pentru date semnate/ne-semnate. Acesta poate efectua până la 64 de operații de multiplicare/multiplicare-acumulare 8b x 16b și 8b x 8b într-un ciclu și 32 de operații de multiplicare/multiplicare-acumulare 16b x 16b într-un ciclu. Pentru funcționalitatea de maximizare și ReLU, DSP-ul dispune de instrucțiuni pentru a efectua 64 de comparații pe 8 biți într-un ciclu. Pentru implementarea funcțiilor neliniare cu intervale finite, cum ar fi tanh și signum, acesta dispune de instrucțiuni pentru implementarea unui tabel de căutare pentru 64 de valori pe 7 biți într-un ciclu. În majoritatea cazurilor, instrucțiunile pentru comparație și tabelul de căutare sunt programate în paralel cu instrucțiunile de multiplicare/multiplicare-acumulare și nu necesită cicluri suplimentare.
- Lărgime de bandă mai mare pentru încărcare/stocare: DSP-ul poate efectua până la două operații de încărcare/stocare pe 512 biți pe ciclu.
- Necesitate redusă de putere dinamică: DSP-ul este o mașină în virgulă fixă. Datorită manipulării flexibile a unei varietăți de tipuri de date, se poate obține performanța completă și avantajul energetic al calculului mixt 16b și 8b cu o pierdere minimă de precizie.
- Flexibilitate: Deoarece DSP-ul este un procesor programabil, sistemul poate fi actualizat la o nouă versiune doar prin efectuarea unei actualizări de firmware.
- Floating Point: Pentru algoritmii care necesită o gamă dinamică extinsă pentru datele și/sau coeficienții lor, DSP-ul dispune de o unitate opțională de virgulă mobilă vectorială.
DPS Vision P5 este livrat cu un set complet de instrumente software care include un compilator C/C++ de înaltă performanță cu vectorizare și programare automată pentru a susține arhitectura SIMD și VLIW fără a fi nevoie să scrie limbaj de asamblare. Acest set complet de instrumente include, de asemenea, linkerul, asamblorul, depanatorul, profilerul și instrumentele de vizualizare grafică. Un simulator cuprinzător de set de instrucțiuni (ISS) permite proiectantului să simuleze și să evalueze rapid performanța. Atunci când se lucrează cu sisteme mari sau cu vectori de testare lungi, opțiunea rapidă și funcțională a simulatorului TurboXim atinge viteze de 40X până la 80X mai rapide decât ISS pentru o dezvoltare eficientă a software-ului și o verificare funcțională.
Cadence a implementat o arhitectură CNN cu un singur strat pe DSP pentru recunoașterea semnelor de circulație din Germania. Cadence a obținut un CDR de 99,403% cu cuantificare pe 16 biți pentru eșantioanele de date și cuantificare pe 8 biți pentru coeficienți în toate straturile pentru această arhitectură. Aceasta are două straturi de convoluție, trei straturi complet conectate, patru straturi ReLU, trei straturi max pooling și un strat neliniar tanh. Cadence a obținut o performanță medie de 38,58 MACs/ciclu pentru întreaga rețea, inclusiv ciclurile pentru toate straturile max pooling, tanh și ReLU. Cadence a obținut cea mai bună performanță în cel mai bun caz de 58,43 MAC pe ciclu pentru cel de-al treilea strat, inclusiv ciclurile pentru funcționalitățile tanh și ReLU. Acest DSP care rulează la 600MHz poate procesa peste 850 de semne de circulație într-o secundă.
Viitorul CNN-urilor
Printre domeniile promițătoare ale cercetării în domeniul rețelelor neuronale se numără rețelele neuronale recurente (RNN) care utilizează memoria pe termen scurt (LSTM). Aceste domenii oferă stadiul actual al tehnicii în sarcinile de recunoaștere a seriilor de timp, cum ar fi recunoașterea vorbirii și recunoașterea scrisului de mână. RNN/autocodorii sunt, de asemenea, capabili să genereze scris de mână/vorbire/imagini cu o anumită distribuție cunoscută ,,,,.
Rețelele de credință profundă, un alt tip de rețea promițătoare care utilizează mașini Boltzman restrânse (RMB)/autocodori, sunt capabile să fie antrenate cu lăcomie, câte un strat la un moment dat, și, prin urmare, sunt mai ușor de antrenat pentru rețele foarte profunde ,.
Concluzie
CNN-urile oferă cele mai bune performanțe în problemele de recunoaștere a modelelor/imaginilor și chiar depășesc performanța oamenilor în anumite cazuri. Cadence a obținut cele mai bune rezultate din industrie folosind algoritmi și arhitecturi proprietare cu CNN-uri. Am dezvoltat CNN-uri ierarhice pentru recunoașterea semnelor de circulație în GTSRB, obținând cea mai bună performanță înregistrată vreodată pe acest set de date. Am dezvoltat un alt algoritm pentru compromisul performanță versus complexitate și am reușit să obținem o reducere a complexității de 86 de ori pentru o degradare a CDR de mai puțin de 2%. DSP-ul Tensilica Vision P5 pentru imagistică și viziune computerizată de la Cadence are toate caracteristicile necesare pentru a implementa CNN-uri, pe lângă caracteristicile necesare pentru a face procesarea semnalelor de imagine. Mai mult de 850 de recunoașteri ale semnelor de circulație pot fi efectuate rulând DSP-ul la 600 MHz. DSP-ul Tensilica Vision P5 de la Cadence are un set aproape ideal de caracteristici pentru a rula CNN-uri.
„Artificial neural network”. Wikipedia. https://en.wikipedia.org/wiki/Artificial_neural_network
Karpathy, Andrej. 2015. „Rețele neuronale Partea 1: Configurarea arhitecturii”. Notes for CS231n Convolutional Neural Networks for Visual Recognition, Stanford University. http://cs231n.github.io/neural-networks-1/
„Convolutional neural network”. Wikipedia. https://en.wikipedia.org/wiki/Convolutional_neural_network
Sermanet, Pierre, și Yann LeCun. 2011. „Traffic Sign Recognition with Multi Scale Networks”. Institutul Courant de Științe Matematice, Universitatea din New York. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6033589
Ciresan, Dan, Ueli Meier, și Jürgen Schmidhuber. 2012. „Rețele neuronale profunde cu mai multe coloane pentru clasificarea imaginilor”. 2012 IEEE Conference on Computer Vision and Pattern Recognition (2012 IEEE Conference on Computer Vision and Pattern Recognition (New York, NY: Institute of Electrical and Electronics Engineers (IEEE)). http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6248110
Ciresan, Dan, Ueli Meier, Jonathan Masci, Luca M. Gambardella și Jurgen Schmidhuber. 2011. „Flexible, High Performance Convolutional Neural Networks for Image Classification” (Rețele neuronale convoluționale flexibile și de înaltă performanță pentru clasificarea imaginilor). Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence-Volume Two: 1237-1242. Recuperat la 17 noiembrie 2013. http://people.idsia.ch/~juergen/ijcai2011.pdf
Lawrence, Steve, C. Lee Giles, Ah Chung Tsoi, și Andrew D. Back. 1997. „Face Recognition: A Convolutional Neural Network Approach”. IEEE Transactions on Neural Networks, Volume 8; Issue 1. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=554195
Russakovsky, O. et al. 2014. „ImageNet Large Scale Visual Recognition Challenge” (Provocare de recunoaștere vizuală pe scară largă ImageNet). International Journal of Computer Vision. http://link.springer.com/article/10.1007/s11263-015-0816-y#
Ovtcharov, Kalin, Olatunji Ruwarse, Joo-Young Kim et al. 22 februarie 2015. „Accelerating Deep Convolutional Networks Using Specialized Hardware” (Accelerarea rețelelor convoluționale profunde utilizând hardware specializat). Microsoft Research. http://research-srv.microsoft.com/pubs/240715/CNN%20Whitepaper.pdf
Stallkamp, J., M. Schlipsing, J. Salmen și C. Igel. „Man Vs. Computer: Benchmarking Machine Learning Algorithms For Traffic Sign Application”. IJCNN 2011. http://www.sciencedirect.com/science/article/pii/S0893608012000457
Hochreiter, Sepp, și Jürgen Schmidhuber. 1997. „Long Short-Term Memory”. Neural Computation, 9(8):1735-1780. ftp://ftp.idsia.ch/pub/juergen/lstm.pdf
Graves, Alex. 2014. „Generating Sequences With Recurrent Neural Networks” (Generarea de secvențe cu rețele neuronale recurente). http://arxiv.org/abs/1308.0850
Schmidhuber, Jurgen. 2015. „Recurrent Neural Networks” (Rețele neuronale recurente). http://people.idsia.ch/~juergen/rnn.html
Olshausen, Bruno A., și David J. Field. 1996. „Emergența proprietăților câmpului receptiv al celulelor simple prin învățarea unui cod împrăștiat pentru imagini naturale”. Nature 381.6583: 607-609. http://www.nature.com/nature/journal/v381/n6583/abs/381607a0.html
Hinton, G. E. și Salakhutdinov, R. R. 2006. „Reducerea dimensionalității datelor cu ajutorul rețelelor neuronale”. Science vol. 313 nr. 5786 pp. 504-507. http://www.sciencemag.org/content/suppl/2006/08/04/313.5786.504.DC1.
Hinton, Geoffrey E. 2009. „Rețele de credință profundă”. Scholarpedia, 4(5):5947.
http://www.scholarpedia.org/article/Deep_belief_networks