Tutorial Big Data și ecosistemul Hadoop
Bine ați venit la prima lecție „Big Data și ecosistemul Hadoop” a tutorialului Big Data Hadoop, care face parte din „Big Data Hadoop și Spark Developer Certification course” oferit de Simplilearn. Această lecție este o introducere în Big Data și în ecosistemul Hadoop. În secțiunea următoare, vom discuta obiectivele acestei lecții.
Obiective
După terminarea acestei lecții, veți fi capabil să:
-
Înțelegeți conceptul de Big Data și provocările sale
-
Explicați ce este Big Data
-
Explicați ce este Hadoop și cum abordează provocările Big Data
-
Descrieți ecosistemul Hadoop
Să aruncăm acum o privire de ansamblu asupra Big Data și Hadoop.
Overview to Big Data and Hadoop
Înainte de anul 2000, datele erau relativ mici decât sunt în prezent; cu toate acestea, calculul datelor era complex. Toate calculele de date depindeau de puterea de procesare a calculatoarelor disponibile.
Mai târziu, pe măsură ce datele au crescut, soluția a fost de a avea calculatoare cu memorie mare și procesoare rapide. Cu toate acestea, după anul 2000, datele au continuat să crească și soluția inițială nu a mai putut fi de ajutor.
În ultimii ani, a avut loc o explozie incredibilă a volumului de date. IBM a raportat că 2,5 exabytes, sau 2,5 miliarde de gigabytes, de date, au fost generate în fiecare zi în 2012.
Iată câteva statistici care indică proliferarea datelor din Forbes, septembrie 2015. 40.000 de interogări de căutare sunt efectuate pe Google în fiecare secundă. Până la 300 de ore de videoclipuri sunt încărcate pe YouTube în fiecare minut.
În Facebook, 31,25 milioane de mesaje sunt trimise de utilizatori și 2,77 milioane de videoclipuri sunt vizualizate în fiecare minut. Până în 2017, aproape 80% dintre fotografii vor fi făcute pe smartphone-uri.
Până în 2020, cel puțin o treime din toate datele vor trece prin Cloud (o rețea de servere conectate prin internet). Până în anul 2020, aproximativ 1,7 megabytes de informații noi vor fi create în fiecare secundă pentru fiecare ființă umană de pe planetă.
Datele cresc mai repede ca niciodată. Puteți utiliza mai multe calculatoare pentru a gestiona aceste date în continuă creștere. În loc ca o singură mașină să execute această sarcină, puteți folosi mai multe mașini. Acest lucru se numește un sistem distribuit.
Puteți verifica cursul Big Data Hadoop and Spark Developer Certification Preview aici!
Să ne uităm la un exemplu pentru a înțelege cum funcționează un sistem distribuit.
Cum funcționează un sistem distribuit?
Să presupunem că aveți o mașină care are patru canale de intrare/ieșire. Viteza fiecărui canal este de 100 MB/sec și vreți să procesați un terabyte de date pe acesta.
Vor fi necesare 45 de minute pentru ca o mașină să proceseze un terabyte de date. Acum, să presupunem că un terabyte de date este procesat de 100 de mașini cu aceeași configurație.
Cei 100 de mașini vor avea nevoie de numai 45 de secunde pentru a procesa un terabyte de date. Sistemele distribuite au nevoie de mai puțin timp pentru a procesa Big Data.
Acum, să ne uităm la provocările unui sistem distribuit.
Provocările sistemelor distribuite
Din moment ce mai multe calculatoare sunt folosite într-un sistem distribuit, există șanse mari de defecțiune a sistemului. Există, de asemenea, o limită a lățimii de bandă.
Complexitatea programării este, de asemenea, ridicată, deoarece este dificil de sincronizat datele și procesele. Hadoop poate aborda aceste provocări.
Să înțelegem ce este Hadoop în secțiunea următoare.
Ce este Hadoop?
Hadoop este un cadru care permite procesarea distribuită a unor seturi mari de date în grupuri de calculatoare folosind modele de programare simple. Este inspirat de un document tehnic publicat de Google.
Cuvântul Hadoop nu are nicio semnificație. Doug Cutting, cel care a descoperit Hadoop, l-a numit după elefantul de jucărie de culoare galbenă al fiului său.
Să discutăm despre modul în care Hadoop rezolvă cele trei provocări ale sistemului distribuit, cum ar fi șansele mari de eșec ale sistemului, limitarea lățimii de bandă și complexitatea programării.
Cele patru caracteristici cheie ale Hadoop sunt:
-
Economic: Sistemele sale sunt foarte economice, deoarece calculatoarele obișnuite pot fi folosite pentru prelucrarea datelor.
-
Fiabil: Este fiabil deoarece stochează copii ale datelor pe diferite mașini și este rezistent la defecțiuni hardware.
-
Scalabil: Este ușor de scalat atât pe orizontală, cât și pe verticală. Câteva noduri suplimentare ajută la scalarea cadrului.
-
Flexibil: Este flexibil și puteți stoca oricât de multe date structurate și nestructurate aveți nevoie și puteți decide să le folosiți mai târziu.
În mod tradițional, datele erau stocate într-o locație centrală și erau trimise către procesor la momentul execuției. Această metodă a funcționat bine pentru date limitate.
Cu toate acestea, sistemele moderne primesc terabytes de date pe zi și este dificil pentru calculatoarele tradiționale sau pentru sistemul de gestionare a bazelor de date relaționale (RDBMS) să împingă volume mari de date către procesor.
Hadoop a adus o abordare radicală. În Hadoop, programul merge la date, și nu invers. Acesta distribuie inițial datele pe mai multe sisteme și ulterior execută calculele acolo unde se află datele.
În următoarea secțiune, vom vorbi despre modul în care Hadoop diferă de sistemul tradițional de baze de date.
Diferența dintre sistemul tradițional de baze de date și Hadoop
Tabelul de mai jos vă va ajuta să faceți distincția între sistemul tradițional de baze de date și Hadoop.
|
Sistemul de baze de date tradițional |
Hadoop |
|
Datele sunt stocate într-o locație centrală și trimise la procesor în momentul execuției. |
În Hadoop, programul se duce la date. Acesta distribuie inițial datele în mai multe sisteme și, ulterior, execută calculul oriunde se află datele. |
|
Sistemele tradiționale de baze de date nu pot fi utilizate pentru a procesa și stoca o cantitate semnificativă de date (big data). |
Hadoop funcționează mai bine atunci când dimensiunea datelor este mare. Acesta poate procesa și stoca o cantitate mare de date în mod eficient și eficace. |
|
SGBD tradițional este utilizat pentru a gestiona numai date structurate și semistructurate. Nu poate fi folosit pentru a controla datele nestructurate. |
Hadoop poate procesa și stoca o varietate de date, indiferent dacă sunt structurate sau nestructurate. |
Să discutăm despre diferența dintre RDBMS tradițional și Hadoop cu ajutorul unei analogii.
Ați fi observat diferența dintre stilul alimentar al unei ființe umane și cel al unui tigru. Un om mănâncă mâncare cu ajutorul unei linguri, unde mâncarea este adusă la gură. În timp ce un tigru își aduce gura spre mâncare.
Acum, dacă mâncarea este reprezentată de date, iar gura este un program, stilul de a mânca al unui om descrie RDBMS tradițional, iar cel al tigrului descrie Hadoop.
Să analizăm ecosistemul Hadoop în secțiunea următoare.
Ecosistemul Hadoop
Ecosistemul Hadoop Hadoop are un ecosistem care a evoluat pornind de la cele trei componente principale ale sale: procesare, gestionarea resurselor și stocare. În acest subiect, veți afla care sunt componentele ecosistemului Hadoop și modul în care acestea își îndeplinesc rolurile în timpul procesării Big Data. Ecosistemul
Hadoop este în continuă creștere pentru a răspunde nevoilor Big Data. Acesta cuprinde următoarele douăsprezece componente:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
În secțiunile următoare veți afla despre rolul fiecărei componente a ecosistemului Hadoop.

Să înțelegem care este rolul fiecărei componente a ecosistemului Hadoop.
Componente ale ecosistemului Hadoop
Să începem cu prima componentă HDFS a ecosistemului Hadoop.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS este un strat de stocare pentru Hadoop.
-
HDFS este potrivit pentru stocarea și procesarea distribuită, adică, în timp ce datele sunt stocate, acestea sunt mai întâi distribuite și apoi sunt procesate.
-
HDFS oferă acces în flux continuu la datele din sistemul de fișiere.
-
HDFS asigură permisiunea și autentificarea fișierelor.
-
HDFS utilizează o interfață de linie de comandă pentru a interacționa cu Hadoop.
Atunci ce stochează datele în HDFS? Este HBase care stochează datele în HDFS.
HBase
-
HBase este o bază de date NoSQL sau o bază de date non-relațională.
-
HBase este importantă și utilizată în principal atunci când aveți nevoie de acces aleatoriu, în timp real, de citire sau de scriere la Big Data.
-
Acesta oferă suport pentru un volum mare de date și un debit ridicat.
-
Într-o HBase, un tabel poate avea mii de coloane.
Am discutat despre modul în care sunt distribuite și stocate datele. Acum, să înțelegem cum sunt ingerate sau transferate aceste date în HDFS. Sqoop face exact acest lucru.
Ce este Sqoop?
-
Sqoop este un instrument conceput pentru a transfera date între Hadoop și serverele de baze de date relaționale.
-
Este folosit pentru a importa date din baze de date relaționale (cum ar fi Oracle și MySQL) în HDFS și pentru a exporta date din HDFS în baze de date relaționale.
Dacă doriți să ingerați date de evenimente, cum ar fi date în flux continuu, date de la senzori sau fișiere jurnal, atunci puteți folosi Flume. Ne vom uita la Flume în secțiunea următoare.
Flume
-
Flume este un serviciu distribuit care colectează date de eveniment și le transferă în HDFS.
-
Este ideal pentru datele de eveniment din mai multe sisteme.
După ce datele sunt transferate în HDFS, acestea sunt procesate. Unul dintre cadrele care procesează datele este Spark.
Ce este Spark?
-
Spark este un cadru de calcul în cluster cu sursă deschisă.
-
Aprovizionează o performanță de până la 100 de ori mai rapidă pentru câteva aplicații cu primitive în memorie, în comparație cu paradigma MapReduce în două etape bazată pe disc a lui Hadoop.
-
Spark poate rula în clusterul Hadoop și poate procesa date în HDFS.
-
Suportă, de asemenea, o mare varietate de sarcini de lucru, care includ Machine learning, Business intelligence, Streaming și Batch processing.
Spark are următoarele componente majore:
-
Spark Core și Resilient Distributed datasets sau RDD
-
Spark SQL
-
Spark streaming
-
Machine learning library sau Mlib
-
Graphx.
Spark este acum utilizat pe scară largă și veți învăța mai multe despre el în lecțiile următoare.
Hadoop MapReduce
-
Hadoop MapReduce este celălalt cadru care procesează datele.
-
Este motorul original de procesare Hadoop, care se bazează în principal pe Java.
-
Se bazează pe modelul de programare map and reduces.
-
Multe instrumente, cum ar fi Hive și Pig, sunt construite pe un model hartă-reducere.
-
Acesta are o toleranță la erori extinsă și matură încorporată în cadru.
-
Este încă foarte frecvent utilizat, dar pierde teren în fața Spark.
După ce datele sunt procesate, acestea sunt analizate. Aceasta poate fi realizată de un sistem open-source de flux de date de nivel înalt numit Pig. Acesta este utilizat în principal pentru analiză.
Să înțelegem acum cum este utilizat Pig pentru analiză.
Pig
-
Pig își convertește scripturile în cod Map și Reduce, salvând astfel utilizatorul de la scrierea unor programe complexe MapReduce.
-
Interogările ad-hoc, cum ar fi Filter și Join, care sunt dificil de realizat în MapReduce, pot fi realizate cu ușurință folosind Pig.
-
De asemenea, puteți utiliza Impala pentru a analiza datele.
-
Este un motor SQL open-source de înaltă performanță, care rulează pe clusterul Hadoop.
-
Este ideal pentru analiza interactivă și are o latență foarte scăzută, care poate fi măsurată în milisecunde.
Impala
-
Impala suportă un dialect de SQL, astfel încât datele din HDFS sunt modelate ca o tabelă de bază de date.
-
Puteți efectua, de asemenea, analize de date folosind HIVE. Acesta este un strat de abstractizare deasupra Hadoop.
-
Este foarte asemănător cu Impala. Cu toate acestea, este preferat pentru operațiuni de procesare a datelor și Extract Transform Load, cunoscut și sub numele de ETL.
-
Impala este preferat pentru interogări ad-hoc.
HIVE
-
HIVE execută interogări utilizând MapReduce; cu toate acestea, un utilizator nu trebuie să scrie niciun cod în MapReduce de nivel scăzut.
-
Hive este potrivit pentru date structurate. După ce datele sunt analizate, acestea sunt gata pentru a fi accesate de utilizatori.
Acum că știm ce face HIVE, vom discuta despre ceea ce susține căutarea datelor. Căutarea datelor se face cu ajutorul Cloudera Search.
Cloudera Search
-
Search este unul dintre produsele de acces aproape în timp real ale Cloudera. Acesta permite utilizatorilor non-tehnici să caute și să exploreze datele stocate în sau ingerate în Hadoop și HBase.
-
Utilizatorii nu au nevoie de cunoștințe de SQL sau de programare pentru a utiliza Cloudera Search, deoarece oferă o interfață simplă, full-text pentru căutare.
-
Un alt beneficiu al Cloudera Search în comparație cu soluțiile de căutare de sine stătătoare este platforma de procesare a datelor complet integrată.
-
Cloudera Search utilizează sistemul de stocare flexibil, scalabil și robust inclus cu CDH sau Cloudera Distribution, inclusiv Hadoop. Acest lucru elimină necesitatea de a muta seturi mari de date între infrastructuri pentru a aborda sarcinile de afaceri.
-
Lucrările Hadoop, cum ar fi MapReduce, Pig, Hive și Sqoop, au fluxuri de lucru.
Oozie
-
Oozie este un flux de lucru sau un sistem de coordonare pe care îl puteți utiliza pentru a gestiona joburile Hadoop.
Ciclul de viață al aplicației Oozie este prezentat în diagrama de mai jos.
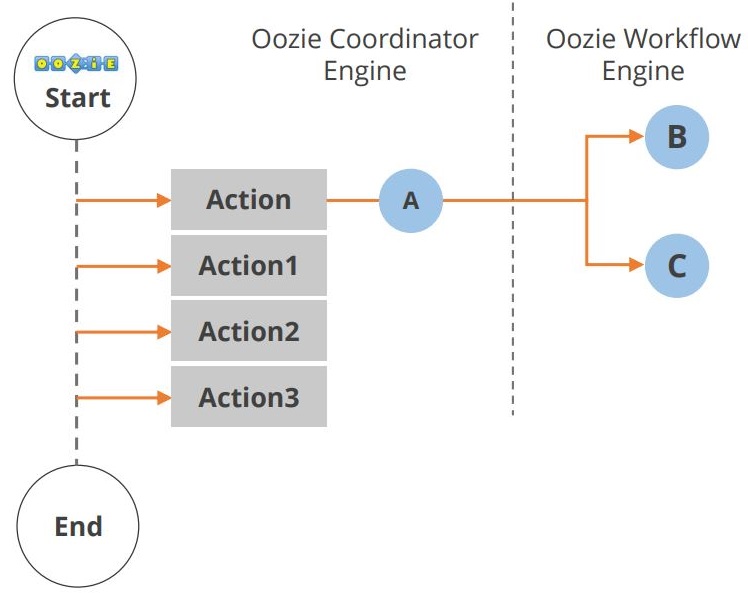 După cum puteți vedea, mai multe acțiuni au loc între începutul și sfârșitul fluxului de lucru. O altă componentă a ecosistemului Hadoop este Hue. Să ne uităm acum la Hue.
După cum puteți vedea, mai multe acțiuni au loc între începutul și sfârșitul fluxului de lucru. O altă componentă a ecosistemului Hadoop este Hue. Să ne uităm acum la Hue.
Hue
Hue este un acronim pentru Hadoop User Experience. Este o interfață web open-source pentru Hadoop. Puteți efectua următoarele operații utilizând Hue:
-
Încărcați și răsfoiți date
-
Întrebați un tabel în HIVE și Impala
-
Executați sarcini și fluxuri de lucru Spark și Pig Căutați date
-
În ansamblu, Hue face Hadoop mai ușor de utilizat.
-
Acesta oferă, de asemenea, editor SQL pentru HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL și Solr SQL.
După această scurtă prezentare a celor douăsprezece componente ale ecosistemului Hadoop, vom discuta acum despre modul în care aceste componente lucrează împreună pentru a procesa Big Data.
Etapele procesării Big Data
Există patru etape ale procesării Big Data: Ingest, Procesare, Analiză, Acces. Să le analizăm în detaliu.
Ingestare
Prima etapă a procesării Big Data este Ingest. Datele sunt ingerate sau transferate în Hadoop din diverse surse, cum ar fi baze de date relaționale, sisteme sau fișiere locale. Sqoop transferă datele de la RDBMS la HDFS, în timp ce Flume transferă datele de eveniment.
Procesare
A doua etapă este Procesarea. În această etapă, datele sunt stocate și procesate. Datele sunt stocate în sistemul distribuit de fișiere, HDFS, și în sistemul distribuit de date NoSQL, HBase. Spark și MapReduce realizează procesarea datelor.
Analiză
Cea de-a treia etapă este Analiză. Aici, datele sunt analizate de cadrele de procesare, cum ar fi Pig, Hive și Impala.
Pig convertește datele cu ajutorul unei hărți și reduce și apoi le analizează. Hive se bazează, de asemenea, pe programarea map and reduce și este cel mai potrivit pentru datele structurate.
Accesare
Cea de-a patra etapă este Accesarea, care este realizată de instrumente precum Hue și Cloudera Search. În această etapă, datele analizate pot fi accesate de către utilizatori.
Hue este interfața web, în timp ce Cloudera Search oferă o interfață text pentru explorarea datelor.
Vezi cursul de certificare Big Data Hadoop și Spark Developer aici!
Rezumat
Să rezumăm acum ceea ce am învățat în această lecție.
-
Hadoop este un cadru pentru stocare și procesare distribuită.
-
Componentele de bază ale Hadoop includ HDFS pentru stocare, YARN pentru gestionarea resurselor de cluster și MapReduce sau Spark pentru procesare.
-
Ecosistemul Hadoop include mai multe componente care susțin fiecare etapă a procesării Big Data.
-
Flume și Sqoop ingerează datele, HDFS și HBase stochează datele, Spark și MapReduce procesează datele, Pig, Hive și Impala analizează datele, Hue și Cloudera Search ajută la explorarea datelor.
-
Oozie gestionează fluxul de lucru al lucrărilor Hadoop.
Concluzie
Aceasta încheie lecția despre Big Data și ecosistemul Hadoop. În lecția următoare, vom discuta despre HDFS și YARN.
Găsește cursurile noastre de formare Big Data Hadoop și Spark Developer Online Classroom în orașele de top:
| Nume | Data | Locul | |
|---|---|---|---|
| Big Data Hadoop and Spark Developer | 3 apr -15 mai 2021, Lot de weekend | Orașul tău | Vezi detalii |
| Big Data Hadoop and Spark Developer | 12 apr -4 mai 2021, Lot în timpul săptămânii | Orașul tău | Vezi detalii |
| Big Data Hadoop and Spark Developer | 24 apr -5 iun 2021, Lot de weekend | Orașul tău | Vezi detalii |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Pentru a afla mai multe, urmați cursul
Big Data Hadoop and Spark Developer Certification Training
Go to Course
Pentru a afla mai multe, urmați cursul
Big Data Hadoop and Spark Developer Certification Training Go to Course
.