Reddit AmItheAsshole ist netter zu Frauen als zu Männern – ein SQL-Beweis?
Wenn Redditoren „bin ich das Arschloch“ fragen, während sie über Frauen sprechen, haben sie eine höhere Chance, als Arschloch beurteilt zu werden. Schauen wir uns diese Metriken an – mit BigQuery, dbt und Data Studio
Achten Sie darauf, dass Sie nichts von dem, was ich hier geschrieben habe, als die absolute Wahrheit ansehen. Mehrere Personen haben auf Twitter auf Probleme hingewiesen und Korrekturen an der von mir angebotenen Analyse vorgenommen. Wenn Sie diesen Beitrag in seiner ursprünglichen Form – und die Reaktionen darauf – lesen, können Sie genauso viel lernen wie ich beim Lesen der Antworten. Sie können viele ihrer ungefilterten Gedanken finden, wenn Sie diesem Twitter-Thread folgen.
Kontext
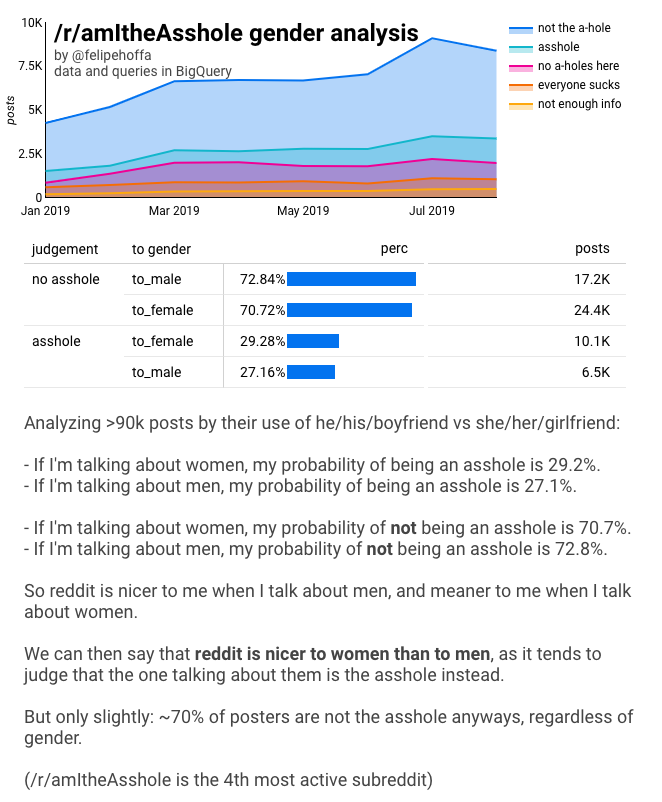
/r/amItheAsshole ist mittlerweile der viertaktivste Subreddit – gemessen an der Anzahl der Kommentare. Die Leute kommen zu diesem Subreddit, um ihre Geschichten zu erzählen, und sie fragen andere Redditoren „bin ich hier das Arschloch?“. Es hat sich herausgestellt, dass die meisten Leute als „nicht das Arschloch“ beurteilt werden, wie in diesem Diagramm zu sehen ist:
Mein Tweet mit diesen Ergebnissen hat viel Aufmerksamkeit bekommen:
Einschließlich der Frage – ist reddit netter zu Frauen oder zu Männern?
Geschlecht bestimmen
Wenn man sich den Titel oder den Inhalt eines Beitrags ansieht, ist es vielleicht schwer zu entscheiden, ob „ich“ ein Mann oder eine Frau ist – aber es ist ziemlich einfach, die Anzahl der „sie/er/seine/Freundin/Freund“ in dem Beitrag zu zählen.
Schauen wir uns ein paar zufällige Beiträge und die Anzahl der einzelnen Pronomen und geschlechtsspezifischen Wörter an:

Wir können sehen, dass die Anzahl der geschlechtsspezifischen Pronomen und Wörter in den Beispielen mit der Person übereinstimmt, von der die Geschichte handelt. Diese Geschichten handeln von einem männlichen Kunden, einer weiblichen Freundin, einem männlichen Nachbarn, einem männlichen Sohn und einer weiblichen Tochter im Teenageralter.
Anhand dieser Zahlen können wir nun eine willkürliche Regel aufstellen: Wenn es mehr als doppelt so viele männliche als weibliche Pronomen gibt, handelt der Beitrag von einem Mann. Die umgekehrte Regel besagt, dass es sich um einen Beitrag über eine Frau handelt. Wenn die Zahlen zu nahe beieinander liegen oder gleich Null sind, nennen wir den Beitrag „neutral“.
Eine weitere Regel, die wir aufstellen können, um die Analyse zu vereinfachen:
- Wenn das Urteil „kein Arschloch“ oder „keine Arschlöcher hier“ lautet, können wir sagen „der Beitrag ist kein Arschloch“.
- Wenn das Urteil ‚Arschloch‘ oder ‚alle sind scheiße‘ lautet, dann können wir sagen ‚der Poster ist ein Arschloch‘.
Wenn wir alle diese Beiträge zusammenfassen, kommen wir auf die Zahlen:

Als ich diese Ergebnisse zum ersten Mal präsentierte, wurde mir gesagt: „Diese Zahlen liegen zu nah beieinander, sie könnten ein statistischer Fehler sein“.
Statistische Signifikanz?
Wie können wir feststellen, dass die Zahlen nicht nur ein statistischer Fehler sind? Schauen wir uns den Trend von Monat zu Monat an – ist er stabil?

Ja! Der Trend variiert von Monat zu Monat, aber die Wahrscheinlichkeit, ein Arschloch zu sein, ist eindeutig höher, wenn über Frauen gesprochen wird, als wenn über Männer gesprochen wird. Wenn der kleine Unterschied nur ein statistischer Zufall wäre, würden wir erwarten, dass der Trend stattdessen stark ansteigt.
Und bitte beachten Sie, dass diese Ergebnisse sehr spezifisch sind, wie dieser Tweet anmerkt:
auf den ich geantwortet habe
How-to
Dieses Mal verwende ich dbtzum ersten Mal, und ich habe meinen gesamten Code auf GitHub hinterlassen. Danke Claire Carroll für deine Hilfe beim Einstieg in dieses tolle Tool!
Um alle /r/AmItheAsshole-Beiträge in BigQuery in eine neue Tabelle zu extrahieren, kann man Folgendes tun:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Dann kann man das Geschlecht und die Bewertung für jeden Beitrag mit einer Abfrage wie der folgenden ermitteln:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
Und schließlich die hier vorgestellten Statistiken:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Diskussion
Im Twitter-Thread zu diesem Beitrag finden Sie viele aufschlussreiche und unterhaltsame Antworten:
Sie können sich gerne an der Diskussion beteiligen (und mir sagen, ob ich falsch liege?). Denkt daran, nett zueinander zu sein – die meisten Leute sind sowieso nicht das Arschloch.
Wollen Sie mehr?
Ich habe nur bis August 2019 abgedeckt, da dann das aktuelle vollständige reddit-Archiv in BigQuery endet – bis zu den erwarteten zukünftigen Updates. Weitere Details zum Sammeln von Live-Daten von pushshift.io finden Sie in meinem vorherigen Beitrag. Danke Jason Baumgartner für den ständigen Nachschub!
Ich bin Felipe Hoffa, ein Developer Advocate für Google Cloud. Folgen Sie mir auf @felipehoffa, finden Sie meine früheren Beiträge auf medium.com/@hoffa, und alles über BigQuery auf reddit.com/r/bigquery.