Using Convolutional Neural Networks for Image Recognition
Ten artykuł został pierwotnie opublikowany w witrynie firmy Cadence. Przedrukowano go tutaj za zgodą firmy Cadence.
Konwolucyjne sieci neuronowe (CNN) są szeroko stosowane w problemach rozpoznawania wzorców i obrazów, ponieważ mają szereg zalet w porównaniu z innymi technikami. W tym artykule omówiono podstawy CNN, w tym opis różnych warstw. Na przykładzie rozpoznawania znaków drogowych omawiamy wyzwania związane z tym ogólnym problemem oraz przedstawiamy algorytmy i oprogramowanie wdrożeniowe opracowane przez Cadence, które umożliwiają kompromis pomiędzy obciążeniem obliczeniowym i energią przy niewielkiej degradacji szybkości rozpoznawania znaków. Nakreślamy wyzwania związane z wykorzystaniem CNN w systemach wbudowanych i przedstawiamy kluczowe cechy Cadence® Tensilica® Vision P5 cyfrowego procesora sygnałowego (DSP) do obrazowania i wizji komputerowej i oprogramowania, które sprawiają, że tak nadaje się do zastosowań CNN w wielu obrazowania i powiązanych zadań rozpoznawania.
What Is a CNN?
Sieć neuronowa to system połączonych sztucznych „neuronów”, które wymieniają wiadomości między sobą. Połączenia mają wagi numeryczne, które są dostrajane podczas procesu szkolenia, tak aby prawidłowo wytrenowana sieć reagowała prawidłowo, gdy zostanie przedstawiona z obrazem lub wzorem do rozpoznania. Sieć składa się z wielu warstw „neuronów” wykrywających cechy. Każda warstwa ma wiele neuronów, które reagują na różne kombinacje danych wejściowych z poprzednich warstw. Jak pokazano na Rysunku 1, warstwy są zbudowane tak, że pierwsza warstwa wykrywa zestaw prymitywnych wzorów na wejściu, druga warstwa wykrywa wzory wzorów, trzecia warstwa wykrywa wzory tych wzorów, i tak dalej. Typowa sieć CNN wykorzystuje od 5 do 25 odrębnych warstw rozpoznawania wzorców.
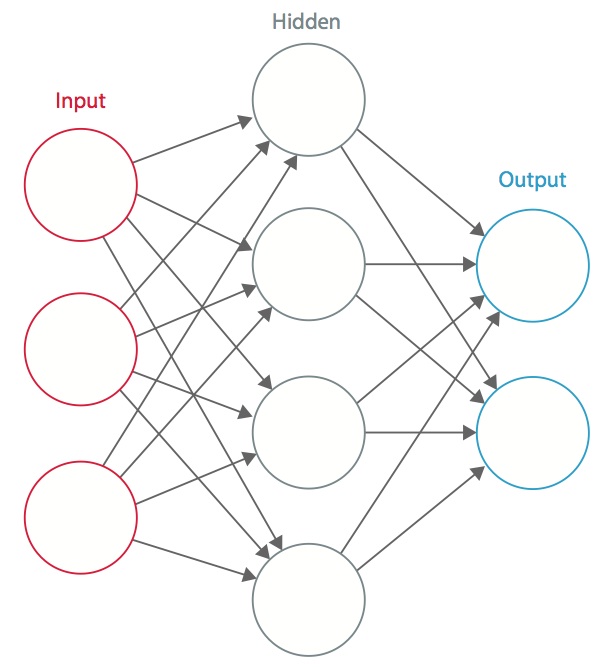
Rysunek 1: Sztuczna sieć neuronowa
Trenowanie jest przeprowadzane przy użyciu „etykietowanego” zbioru danych wejściowych w szerokim asortymencie reprezentatywnych wzorców wejściowych, które są oznaczone za pomocą zamierzonej reakcji wyjściowej. Trening wykorzystuje metody ogólnego przeznaczenia do iteracyjnego określania wag dla pośrednich i końcowych neuronów cech. Rysunek 2 demonstruje proces szkolenia na poziomie bloków.
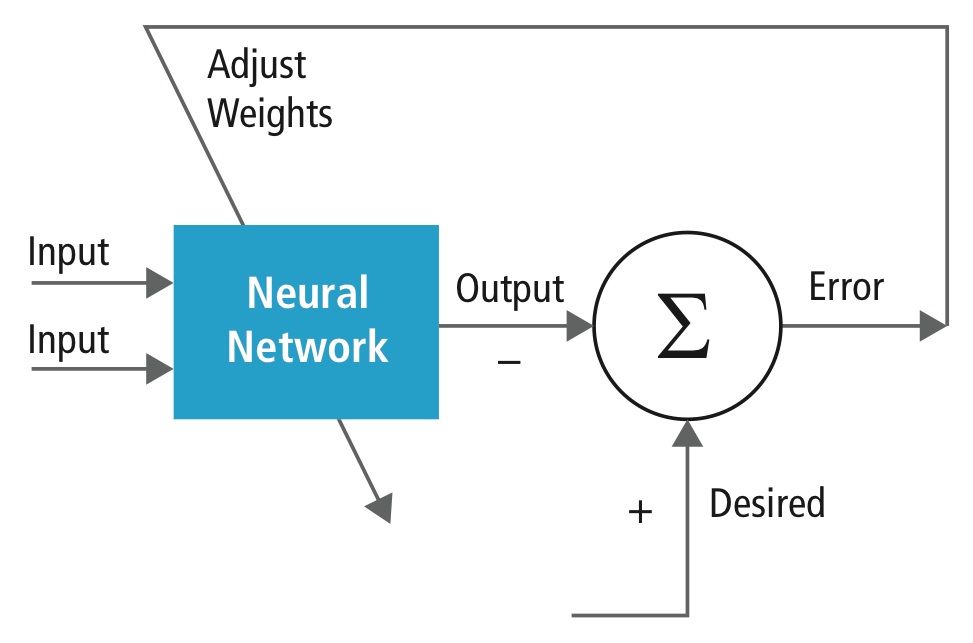
Rysunek 2: Szkolenie sieci neuronowych
Sieci neuronowe są inspirowane biologicznymi systemami neuronowymi. Podstawową jednostką obliczeniową mózgu jest neuron i są one połączone synapsami. Na rysunku 3 porównano biologiczny neuron z podstawowym modelem matematycznym


Rysunek 3: Ilustracja biologicznego neuronu (u góry) i jego modelu matematycznego (u dołu)
W prawdziwym zwierzęcym systemie neuronowym neuron odbiera sygnały wejściowe ze swoich dendrytów i wytwarza sygnały wyjściowe wzdłuż swojego aksonu. Akson rozgałęzia się i łączy się poprzez synapsy z dendrytami innych neuronów. Kiedy kombinacja sygnałów wejściowych osiąga jakiś warunek progowy wśród jego dendrytów wejściowych, neuron jest wyzwalany i jego aktywacja jest przekazywana do kolejnych neuronów.
W modelu obliczeniowym sieci neuronowej, sygnały, które podróżują wzdłuż aksonów (np. x0) oddziałują multiplikatywnie (np., w0x0) z dendrytami innego neuronu w oparciu o siłę synaptyczną w tej synapsie (np., w0). Wagi synaptyczne są wyuczone i kontrolują wpływ jednego lub drugiego neuronu. Dendryty przenoszą sygnał do ciała komórki, gdzie wszystkie są sumowane. Jeśli końcowa suma jest powyżej określonego progu, neuron uruchamia się, wysyłając spajk wzdłuż swojego aksonu. W modelu obliczeniowym zakłada się, że dokładny czas odpalenia nie ma znaczenia, a jedynie częstotliwość odpalenia przekazuje informację. W oparciu o interpretację rate code, częstotliwość wypalania neuronu jest modelowana za pomocą funkcji aktywacji ƒ, która reprezentuje częstotliwość spajków wzdłuż aksonu. Często wybieraną funkcją aktywacji jest sigmoida. Podsumowując, każdy neuron oblicza iloczyn punktowy wejść i wag, dodaje skośność i stosuje nieliniowość jako funkcję wyzwalającą (na przykład, podążając za sigmoidalną funkcją odpowiedzi).
A CNN jest specjalnym przypadkiem sieci neuronowej opisanej powyżej. CNN składa się z jednej lub więcej warstw konwolucyjnych, często z warstwą podpróbkowania, po których następuje jedna lub więcej w pełni połączonych warstw, jak w standardowej sieci neuronowej.
Projekt CNN jest motywowany odkryciem mechanizmu wizualnego, kory wzrokowej, w mózgu. Kora wzrokowa zawiera wiele komórek, które są odpowiedzialne za wykrywanie światła w małych, nakładających się na siebie subregionach pola widzenia, które są nazywane polami recepcyjnymi. Komórki te działają jak lokalne filtry przestrzeni wejściowej, a bardziej złożone komórki mają większe pola recepcyjne. Warstwa konwolucji w CNN wykonuje funkcję, którą wykonują komórki w korze wzrokowej .
Typowa CNN do rozpoznawania znaków drogowych jest pokazana na rysunku 4. Każda cecha w warstwie otrzymuje dane wejściowe ze zbioru cech znajdujących się w małym sąsiedztwie w poprzedniej warstwie, zwanym lokalnym polem recepcyjnym. Dzięki lokalnym polom receptywnym, cechy mogą wyodrębnić elementarne cechy wizualne, takie jak zorientowane krawędzie, punkty końcowe, narożniki itp. Po ekstraktorze następuje trenowany klasyfikator, standardowa sieć neuronowa, która klasyfikuje wektory cech do klas.
W CNN warstwy konwolucyjne pełnią rolę ekstraktora cech. Nie są one jednak projektowane ręcznie. Wagi jądra filtra konwolucyjnego są ustalane jako część procesu szkolenia. Warstwy konwolucyjne są w stanie wyodrębnić cechy lokalne, ponieważ ograniczają pola receptywne warstw ukrytych do lokalnych.
Rysunek 4: Typowy schemat blokowy sieci CNN
Sieci CNN są używane w wielu dziedzinach, w tym w rozpoznawaniu obrazów i wzorców, rozpoznawaniu mowy, przetwarzaniu języka naturalnego i analizie wideo. Istnieje wiele powodów, dla których neuronowe sieci konwolucyjne stają się ważne. W tradycyjnych modelach do rozpoznawania wzorców, ekstraktory cech są projektowane ręcznie. W sieciach CNN, wagi warstwy konwolucyjnej używanej do ekstrakcji cech, jak również warstwy w pełni połączonej używanej do klasyfikacji, są określane podczas procesu treningu. Ulepszone struktury sieciowe CNN prowadzą do oszczędności w wymaganiach dotyczących pamięci i złożoności obliczeniowej, a jednocześnie zapewniają lepszą wydajność w zastosowaniach, w których dane wejściowe mają lokalną korelację (np. obraz i mowa).
Duże wymagania dotyczące zasobów obliczeniowych do szkolenia i oceny CNN są czasami spełniane przez procesory graficzne (GPU), procesory DSP lub inne architektury krzemowe zoptymalizowane pod kątem wysokiej przepustowości i niskiego zużycia energii podczas wykonywania idiosynkratycznych wzorców obliczeń CNN. W rzeczywistości, zaawansowane procesory takie jak Tensilica Vision P5 DSP for Imaging and Computer Vision firmy Cadence mają niemal idealny zestaw zasobów obliczeniowych i pamięciowych wymaganych do uruchomienia CNN przy wysokiej wydajności.
W aplikacjach rozpoznawania wzorców i obrazów, najlepsze możliwe wskaźniki poprawnej detekcji (CDR) zostały osiągnięte przy użyciu CNN. Na przykład, CNN osiągnęły CDR na poziomie 99.77% używając bazy danych MNIST z odręcznym pismem, CDR na poziomie 97.47% z zestawem danych NORB z obiektami 3D oraz CDR na poziomie 97.6% na ~5600 obrazach z więcej niż 10 obiektami. CNN nie tylko zapewniają najlepszą wydajność w porównaniu z innymi algorytmami wykrywania, ale nawet przewyższają ludzi w przypadkach takich jak klasyfikowanie obiektów do drobnoziarnistych kategorii, takich jak konkretna rasa psa lub gatunek ptaka .
Rysunek 5 przedstawia typowy potok algorytmów wizyjnych, który składa się z czterech etapów: wstępnego przetwarzania obrazu, wykrywania regionów zainteresowania (ROI), które zawierają prawdopodobne obiekty, rozpoznawania obiektów i podejmowania decyzji dotyczących wizji. Etap wstępnego przetwarzania jest zwykle zależny od szczegółów danych wejściowych, zwłaszcza systemu kamery, i często jest implementowany w przewodowej jednostce poza podsystemem wizyjnym. Podejmowanie decyzji na końcu potoku zwykle operuje na rozpoznanych obiektach – może podejmować złożone decyzje, ale operuje na znacznie mniejszej ilości danych, więc decyzje te nie są zwykle problemami trudnymi obliczeniowo lub wymagającymi dużej ilości pamięci. Dużym wyzwaniem są etapy wykrywania i rozpoznawania obiektów, gdzie sieci CNN mają obecnie szeroki wpływ.

Rysunek 5: Potok algorytmów wizyjnych
Warstwy sieci CNN
Poprzez układanie wielu różnych warstw w sieci CNN budowane są złożone architektury dla problemów klasyfikacji. Najbardziej powszechne są cztery typy warstw: warstwy konwolucji, warstwy łączenia/podpróbkowania, warstwy nieliniowe i warstwy w pełni połączone.
Warstwy konwolucji
Operacja konwolucji wyodrębnia różne cechy danych wejściowych. Pierwsza warstwa konwolucji wyodrębnia cechy niskiego poziomu, takie jak krawędzie, linie i narożniki. Warstwy wyższego rzędu wydobywają cechy wyższego rzędu. Rysunek 6 ilustruje proces konwolucji 3D wykorzystywany w sieciach CNN. Dane wejściowe mają rozmiar N x N x D i są konwertowane przez H jąder, każde o
rozmiarze k x k x D osobno. Konwolucja wejścia z jednym jądrem daje jedną cechę wyjściową, a z H jądrami niezależnie od siebie daje H cech. Zaczynając od lewego górnego rogu wejścia, każde jądro jest przesuwane od lewej do prawej, po jednym elemencie na raz. Po osiągnięciu prawego górnego rogu, jądro jest przesuwane o jeden element w dół, i ponownie jądro jest przesuwane od lewej do prawej, po jednym elemencie na raz. Proces ten jest powtarzany do momentu, aż
jądro osiągnie prawy dolny róg. Dla przypadku, gdy N = 32 i k = 5 , istnieje 28 unikalnych pozycji od lewej do prawej i 28 unikalnych pozycji od góry do dołu, które może przyjąć jądro. Odpowiadając tym pozycjom, każda cecha na wyjściu będzie zawierać 28×28 (tj. (N-k+1) x (N-k+1)) elementów. Dla każdej pozycji jądra w procesie okna przesuwnego, k x k x D elementów wejścia i k x k x D elementów jądra są element po elemencie mnożone i kumulowane. Tak więc, aby utworzyć jeden element jednej cechy wyjściowej, wymagane jest wykonanie k x k x D operacji mnożenia-akumulacji.
Rysunek 6: Obrazowe przedstawienie procesu konwolucji
Warstwy pooling/subsampling
Warstwa pooling/subsampling zmniejsza rozdzielczość cech. Dzięki temu cechy są odporne na szumy i zniekształcenia. Istnieją dwa sposoby łączenia: łączenie maksymalne i łączenie średnie. W obu przypadkach dane wejściowe dzielone są na nienakładające się przestrzenie dwuwymiarowe. Na przykład, na rysunku 4, warstwa 2 jest warstwą łączącą. Każda cecha wejściowa ma rozmiar 28×28 i jest podzielona na 14×14 regionów o rozmiarze 2×2. W przypadku łączenia średniego, obliczana jest średnia z czterech wartości w regionie. W przypadku łączenia maksymalnego, wybierana jest maksymalna wartość z czterech wartości.
Rysunek 7 przedstawia proces łączenia dalej. Dane wejściowe mają rozmiar 4×4. W przypadku podpróbkowania 2×2, obraz 4×4 jest dzielony na cztery nienakładające się macierze o rozmiarze 2×2. W przypadku max pooling, maksymalna wartość czterech wartości w macierzy 2×2 jest wyjściem. W przypadku łączenia średniego wartością wyjściową jest średnia z czterech wartości. Zwróć uwagę, że w przypadku wyjścia o indeksie (2,2) wynikiem uśredniania jest ułamek, który został zaokrąglony do najbliższej liczby całkowitej.
Rysunek 7: Obrazowa reprezentacja łączenia maksymalnego i łączenia średniego
Warstwy nieliniowe
Sieci neuronowe w ogólności, a CNN w szczególności, polegają na nieliniowej funkcji „wyzwalania”, aby zasygnalizować odrębną identyfikację prawdopodobnych cech na każdej warstwie ukrytej. CNN mogą wykorzystywać różne specyficzne funkcje – takie jak rektyfikowane jednostki liniowe (ReLU) i ciągłe funkcje wyzwalania (nieliniowe) – do efektywnej implementacji tego nieliniowego wyzwalania.
ReLU
ReLU implementuje funkcję y = max(x,0), więc rozmiary wejścia i wyjścia tej warstwy są takie same. Zwiększa ona nieliniowe właściwości funkcji decyzyjnej i całej sieci bez wpływu na pola receptywne warstwy konwolucji. W porównaniu do innych funkcji nieliniowych stosowanych w CNN (np. tangens hiperboliczny, absolut tangensa hiperbolicznego, sigmoida), zaletą ReLU jest to, że sieć trenuje wielokrotnie szybciej. Funkcjonalność ReLU jest przedstawiona na Rysunku 8, z jej funkcją transferu wykreśloną powyżej strzałki.
Rysunek 8: Obrazowe przedstawienie funkcjonalności ReLU
Ciągła funkcja wyzwalająca (nieliniowa)
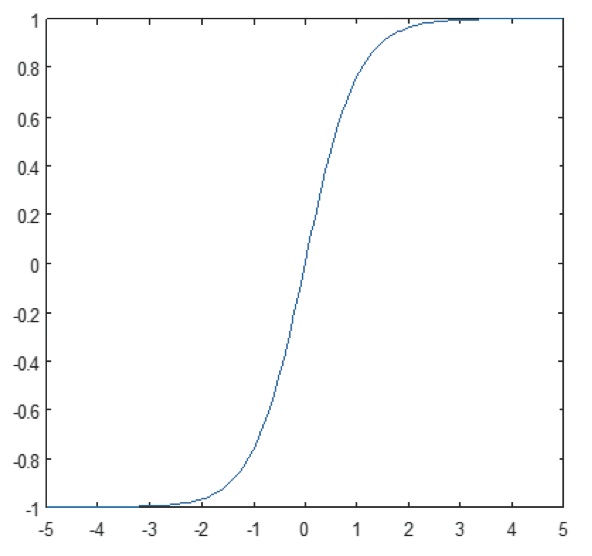
Warstwa nieliniowa działa element po elemencie w każdej funkcji. Ciągła funkcja wyzwalająca może być tangensem hiperbolicznym (Rysunek 9), absolutem tangensa hiperbolicznego (Rysunek 10) lub sigmoidą (Rysunek 11). Na rysunku 12 pokazano, jak nieliniowość jest stosowana element po elemencie.
Rysunek 9: Wykres funkcji tangensa hiperbolicznego
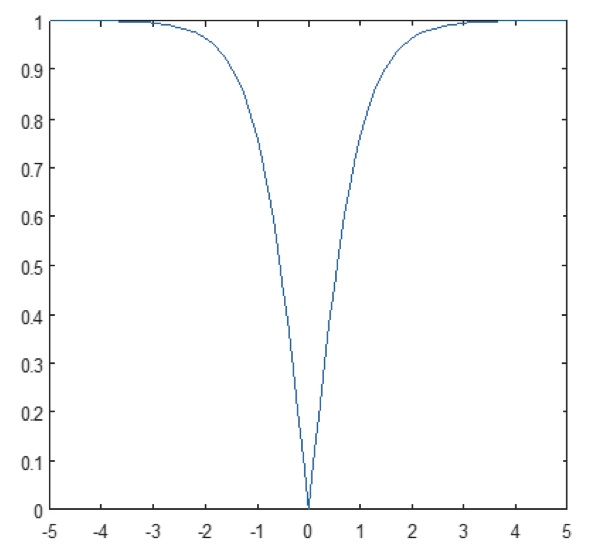
Rysunek 10: Wykres funkcji absolutnej tangensa hiperbolicznego
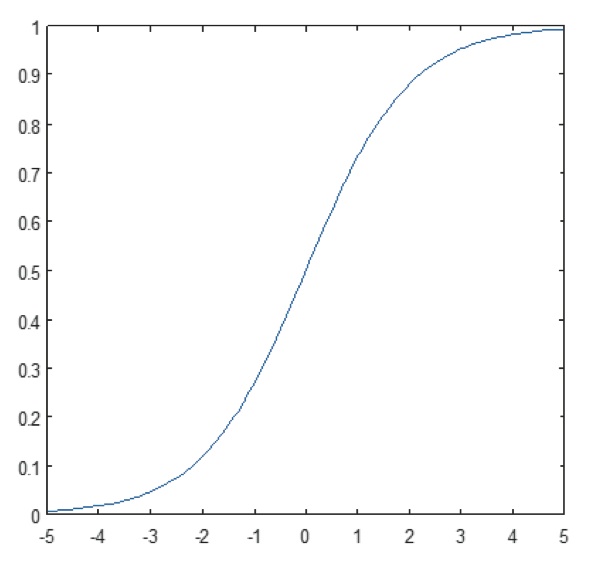
Rysunek 11: Wykres funkcji sigmoidalnej
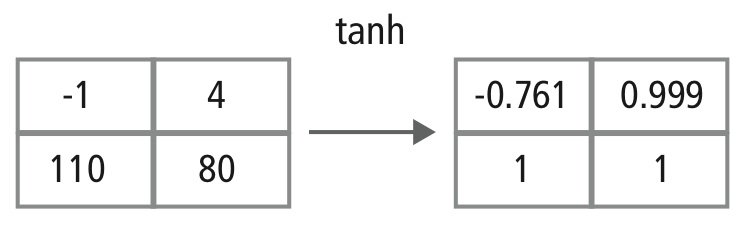
Rysunek 12: Obrazowe przedstawienie przetwarzania tanh
Warstwy w pełni połączone
Warstwy w pełni połączone są często używane jako końcowe warstwy CNN. Warstwy te matematycznie sumują wagi cech z poprzedniej warstwy, wskazując dokładną mieszankę „składników” do określenia konkretnego docelowego wyniku wyjściowego. W przypadku warstwy w pełni połączonej, wszystkie elementy wszystkich cech poprzedniej warstwy są wykorzystywane w obliczeniach każdego elementu każdej cechy wyjściowej.
Rysunek 13 wyjaśnia w pełni połączoną warstwę L. Warstwa L-1 ma dwie cechy, z których każda jest 2×2, czyli ma cztery elementy. Warstwa L ma dwie cechy, z których każda ma jeden element.
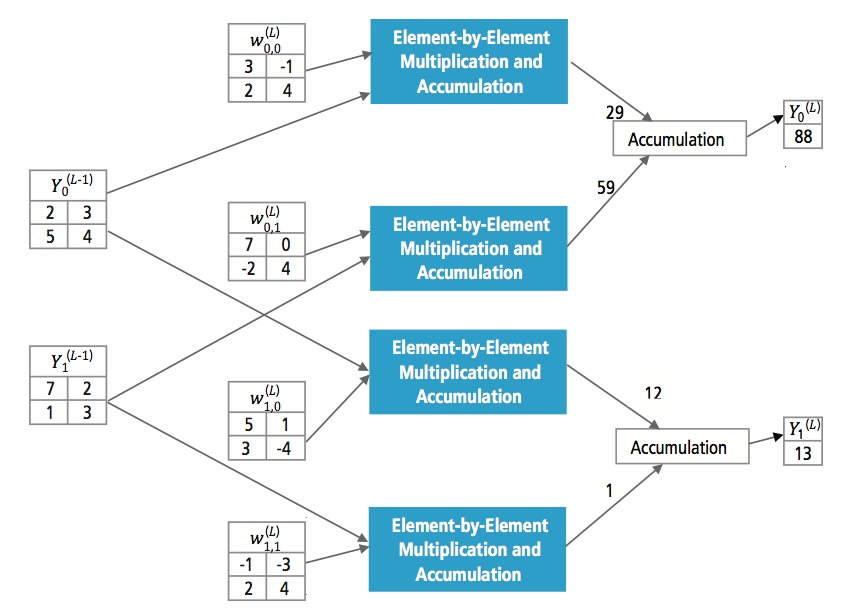
Rysunek 13: Przetwarzanie w pełni połączonej warstwy
Why CNN?
While neural networks and other pattern detection methods have been around for the past 50 years, there has been significant development in the area of convolutional neural networks in the recent past. Ta sekcja obejmuje zalety wykorzystania CNN do rozpoznawania obrazów.
Odporność na przesunięcia i zniekształcenia obrazu
Detekcja z wykorzystaniem CNN jest odporna na zniekształcenia, takie jak zmiana kształtu spowodowana obiektywem kamery, różne warunki oświetlenia, różne pozy, obecność częściowych okluzji, przesunięcia poziome i pionowe itp. CNN są jednak niezmienne na przesunięciach, ponieważ ta sama konfiguracja wag jest używana w całej przestrzeni. Teoretycznie możemy również osiągnąć niezmienniczość przesunięcia za pomocą warstw w pełni połączonych. Jednak w tym przypadku wynikiem treningu jest wiele jednostek z identycznymi wzorcami wagowymi w różnych miejscach na wejściu. Aby nauczyć się tych konfiguracji wagowych, wymagana byłaby duża liczba instancji treningowych, aby pokryć przestrzeń możliwych wariacji.
Mniejsze wymagania pamięciowe
W tym samym hipotetycznym przypadku, w którym używamy w pełni połączonej warstwy do ekstrakcji cech, obraz wejściowy o rozmiarze 32×32 i warstwa ukryta posiadająca 1000 cech będą wymagały rzędu 106 współczynników, co stanowi ogromne zapotrzebowanie na pamięć. W warstwie konwolucyjnej te same współczynniki są używane w różnych miejscach przestrzeni, więc zapotrzebowanie na pamięć jest drastycznie zmniejszone.
Łatwiejsze i lepsze szkolenie
Ponownie, używając standardowej sieci neuronowej, która byłaby odpowiednikiem CNN, ponieważ liczba paramterów byłaby znacznie większa, czas szkolenia również wzrósłby proporcjonalnie. W CNN, ponieważ liczba parametrów jest drastycznie zredukowana, czas treningu jest proporcjonalnie krótszy. Ponadto, zakładając doskonały trening, możemy zaprojektować standardową sieć neuronową, której wydajność będzie taka sama jak CNN. Ale w praktycznym szkoleniu,
standardowa sieć neuronowa równoważna CNN miałaby więcej parametrów, co prowadziłoby do większego dodawania szumu podczas procesu szkolenia. Stąd, wydajność standardowej sieci neuronowej równoważnej CNN będzie zawsze gorsza.
Recognition Algorithm for GTSRB Dataset
The German Traffic Sign Recognition Benchmark (GTSRB) was a multi-class, single-image classification challenge held at the International Joint Conference on Neural Networks (IJCNN) 2011, with the following requirements:
- 51 840 obrazów niemieckich znaków drogowych w 43 klasach (rysunki 14 i 15)
- Rozmiar obrazów waha się od 15×15 do 222×193
- Obrazy są pogrupowane według klasy i ścieżki z co najmniej 30 obrazami na ścieżkę
- Obrazy są dostępne jako obrazy kolorowe (RGB), cechy HOG, cechy Haar i histogramy kolorów
- Konkurencja dotyczy tylko algorytmu klasyfikacji; algorytm znajdowania regionu zainteresowania w ramce nie jest wymagany
- Informacja temporalna sekwencji testowych nie jest współdzielona, więc wymiar temporalny nie może być wykorzystany w algorytmie klasyfikacji

Rysunek 14: Idealne znaki drogowe GTSRB

Rysunek 15: Znaki drogowe GTSRB z upośledzeniami
Algorytm Cadence do rozpoznawania znaków drogowych w zbiorze danych GTSRB
Cadence opracowała różne algorytmy w MATLABie do rozpoznawania znaków drogowych przy użyciu zbioru danych GTSRB, zaczynając od konfiguracji bazowej opartej na znanej pracy na temat rozpoznawania znaków. Wskaźnik poprawnego wykrywania wynoszący 99,24% i nakład pracy obliczeniowej wynoszący prawie >50 milionów mnożeń na znak pokazano jako gruby zielony punkt na rysunku 16. Firma Cadence osiągnęła znacznie lepsze wyniki stosując nasze nowe autorskie podejście Hierarchical CNN. W tym algorytmie 43 znaki drogowe zostały podzielone na pięć rodzin. W sumie implementujemy sześć mniejszych sieci CNN. Pierwsza CNN decyduje, do której rodziny należy odebrany znak drogowy. Gdy rodzina znaku jest znana, CNN (jedna z pozostałych pięciu) odpowiadająca wykrytej rodzinie jest uruchamiana w celu określenia znaku drogowego w ramach tej rodziny. Wykorzystując ten algorytm, firma Cadence osiągnęła wskaźnik poprawnego wykrywania na poziomie 99,58%, co stanowi najlepszy CDR osiągnięty dotychczas na GTSRB.
Algorithm for Performance vs. Complexity Tradeoff
W celu kontroli złożoności CNN w aplikacjach wbudowanych firma Cadence opracowała również zastrzeżony algorytm wykorzystujący dekompozycję wartości własnych, który redukuje wytrenowaną CNN do jej kanonicznego wymiaru. Za pomocą tego algorytmu udało nam się drastycznie zmniejszyć złożoność CNN bez pogorszenia wydajności lub z niewielką kontrolowaną redukcją CDR. Rysunek 16 przedstawia uzyskane wyniki:
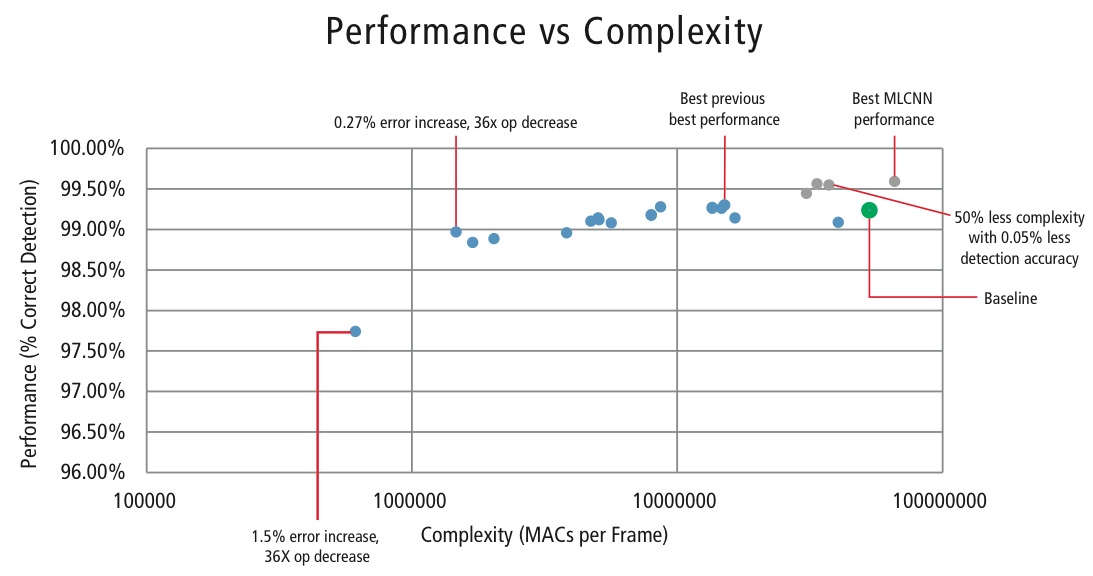
Figure 16: Performance vs. complexity plot for various CNN configurations to detect traffic signs in GTSRB dataset
Zielony punkt na rysunku 16 to konfiguracja bazowa. Ta konfiguracja jest dość zbliżona do konfiguracji sugerowanej w referencji . Wymaga ona 53 MMACs na ramkę dla stopy błędu 0.76%.
- Drugi punkt od lewej wymaga 1.47 miliona MACs na ramkę dla stopy błędu 1.03%, czyli, dla wzrostu stopy błędu o 0,27%, zapotrzebowanie na MAC zostało zmniejszone o współczynnik 36,14.
- Punkt najbardziej wysunięty na lewo wymaga 0,61 MMAC na ramkę dla osiągnięcia stopy błędu 2,26%, czyli liczba MAC została zmniejszona o współczynnik 86,4 razy.
- Punkty w kolorze niebieskim dotyczą jednopoziomowej CNN, natomiast punkty w kolorze czerwonym dotyczą hierarchicznej CNN. Wydajność w najlepszym przypadku 99,58% jest osiągana przez hierarchiczną CNN.
CNNs in Embedded Systems
Jak pokazano na rysunku 5, podsystem wizyjny wymaga wielu procesów przetwarzania obrazu oprócz CNN. Aby uruchomić CNN w systemie wbudowanym o ograniczonej mocy, który obsługuje przetwarzanie obrazu, powinien on spełniać następujące wymagania:
- Dostępność wysokiej wydajności obliczeniowej: W przypadku typowej implementacji CNN wymogiem są miliardy MAC na sekundę.
- Większa przepustowość load/store: W przypadku w pełni połączonej warstwy używanej do celów klasyfikacji każdy współczynnik zostaje użyty w mnożeniu tylko raz. Tak więc, wymaganie dotyczące szerokości pasma load-store jest większe niż liczba MAC wykonywanych przez procesor.
- Niskie zapotrzebowanie na moc dynamiczną: System powinien zużywać mniej mocy. Aby rozwiązać ten problem, wymagana jest implementacja stałoprzecinkowa, która narzuca wymóg spełnienia wymagań wydajnościowych przy użyciu minimalnej możliwej skończonej liczby bitów.
- Elastyczność: Powinna istnieć możliwość łatwej modernizacji istniejącego projektu do nowego, lepiej działającego projektu.
Ponieważ zasoby obliczeniowe są zawsze ograniczeniem w systemach wbudowanych, jeśli przypadek użycia pozwala na niewielką degra- dację wydajności, pomocne jest posiadanie algorytmu, który może osiągnąć ogromne oszczędności w złożoności obliczeniowej kosztem kontrolowanej niewielkiej degradacji wydajności. Tak więc praca Cadence nad algorytmem pozwalającym osiągnąć kompromis złożoność versus wydajność, jak wyjaśniono w poprzedniej sekcji, ma duże znaczenie dla implementacji CNN w systemach wbudowanych.
CNNs on Tensilica Processors
Tensilica Vision P5 DSP jest wysokowydajnym, niskonapięciowym procesorem DSP zaprojektowanym specjalnie do przetwarzania obrazów i wizji komputerowej. DSP posiada architekturę VLIW z obsługą SIMD. Posiada pięć gniazd emisji w słowie instrukcji o długości do 96 bitów i może załadować do 1024-bitowych słów z pamięci w każdym cyklu. Wewnętrzne rejestry i jednostki operacyjne mają zakres od 512 bitów do 1536 bitów, gdzie dane są reprezentowane jako 16, 32 lub 64 plasterki danych o pikselach 8b, 16b, 24b, 32b lub 48b.
DSP odpowiada na wszystkie wyzwania związane z implementacją CNN w systemach wbudowanych, omówione w poprzedniej sekcji.
- Dostępność wysokiej wydajności obliczeniowej: Oprócz zaawansowanego wsparcia dla implementacji przetwarzania sygnałów obrazowych, DSP posiada wsparcie instrukcyjne dla wszystkich etapów CNN. Dla operacji konwolucji, posiada bardzo bogaty zestaw instrukcji wspierających operacje mnożenia/multiplikacji-kumulacji obsługujących operacje 8b x 8b, 8b x 16b i 16b x 16b dla danych podpisanych/niepodpisanych. Może wykonać do 64 operacji mnożenia/wielokrotnego kumulowania 8b x 16b i 8b x 8b w jednym cyklu oraz 32 operacje mnożenia/wielokrotnego kumulowania 16b x 16b w jednym cyklu. Dla funkcji max pooling i ReLU, DSP posiada instrukcje pozwalające na wykonanie 64 8-bitowych porównań w jednym cyklu. Dla implementacji funkcji nieliniowych o skończonych zakresach, takich jak tanh i signum, posiada instrukcje implementujące tabelę wyszukującą dla 64 wartości 7-bitowych w jednym cyklu. W większości przypadków instrukcje porównania i tablicy wyszukującej są planowane równolegle z instrukcjami mnożenia/mnożenia-kumulacji i nie zajmują żadnych dodatkowych cykli.
- Większa przepustowość load/store: DSP może wykonać do dwóch 512-bitowych operacji load/store na cykl.
- Niskie zapotrzebowanie na moc dynamiczną: DSP jest maszyną stałoprzecinkową. Dzięki elastycznej obsłudze różnych typów danych, można osiągnąć pełną wydajność i przewagę energetyczną mieszanych obliczeń 16b i 8b przy minimalnej utracie dokładności.
- Elastyczność: Ponieważ DSP jest procesorem programowalnym, system można uaktualnić do nowej wersji po prostu wykonując upgrade firmware.
- Płynny punkt: W przypadku algorytmów wymagających rozszerzonego zakresu dynamicznego dla swoich danych i/lub współczynników, DSP posiada opcjonalną wektorową jednostkę zmiennoprzecinkową.
Procesor Vision P5 DSP jest dostarczany z kompletnym zestawem narzędzi programowych, który obejmuje wysokowydajny kompilator C/C++ z automatyczną wektoryzacją i harmonogramowaniem do obsługi architektury SIMD i VLIW bez konieczności pisania języka asemblera. Ten wszechstronny zestaw narzędzi zawiera także linker, asembler, debugger, profiler i narzędzia do graficznej wizualizacji. Wszechstronny symulator zestawu instrukcji (ISS) pozwala projektantowi na szybką symulację i ocenę wydajności. Podczas pracy z dużymi systemami lub długimi wektorami testowymi, szybka, funkcjonalna opcja symulatora TurboXim osiąga prędkości, które są 40x do 80x szybsze niż ISS dla wydajnego rozwoju oprogramowania i weryfikacji funkcjonalnej.
Cadence wdrożyła architekturę jednowarstwową CNN na DSP dla niemieckiego rozpoznawania znaków drogowych. Cadence osiągnęła CDR na poziomie 99,403% przy 16-bitowej kwantyzacji dla próbek danych i 8-bitowej kwantyzacji dla współczynników we wszystkich warstwach dla tej architektury. Posiada ona dwie warstwy konwolucji, trzy warstwy w pełni połączone, cztery warstwy ReLU, trzy warstwy max pooling i jedną warstwę nieliniową tanh. Firma Cadence uzyskała średnią wydajność 38,58 MACs/cykl dla całej sieci, w tym cykle dla wszystkich warstw max pooling, tanh i ReLU. Firma Cadence osiągnęła w najlepszym przypadku wydajność 58,43 MACs/cykl dla trzeciej warstwy, włączając w to cykle dla funkcjonalności tanh i ReLU. Ten procesor DSP pracujący z częstotliwością 600 MHz może przetwarzać ponad 850 znaków drogowych w ciągu jednej sekundy.
Przyszłość CNN
Pośród obiecujących obszarów badań nad sieciami neuronowymi znajdują się rekurencyjne sieci neuronowe (RNN) wykorzystujące długą pamięć krótkotrwałą (LSTM). Obszary te dostarczają obecny stan wiedzy w zadaniach rozpoznawania serii czasowych, takich jak rozpoznawanie mowy i rozpoznawanie pisma ręcznego. RNN/autoencodery są również zdolne do generowania pisma ręcznego/mowy/obrazów z pewną znaną dystrybucją ,,,,.
Głębokie sieci przekonań, inny obiecujący typ sieci wykorzystujący ograniczone maszyny Boltzmana (RMBs)/autoencodery, są w stanie być szkolone zachłannie, jedna warstwa na raz, a zatem są łatwiejsze do szkolenia dla bardzo głębokich sieci.
Wniosek
Sieci CNN dają najlepsze wyniki w problemach związanych z rozpoznawaniem wzorów/obrazów, a w niektórych przypadkach przewyższają nawet ludzi. Firma Cadence osiągnęła najlepsze w branży wyniki przy użyciu własnych algorytmów i architektur z CNN. Opracowaliśmy hierarchiczne sieci CNN do rozpoznawania znaków drogowych w GTSRB, osiągając najlepsze wyniki w historii tego zbioru danych. Opracowaliśmy inny algorytm dla kompromisu wydajność-za-kompleksowość i udało nam się osiągnąć redukcję złożoności o współczynnik 86 przy degradacji CDR poniżej 2%. Procesor DSP Tensilica Vision P5 dla obrazowania i wizji komputerowej firmy Cadence posiada wszystkie funkcje wymagane do implementacji CNN oprócz funkcji wymaganych do przetwarzania sygnału obrazu. Ponad 850 rozpoznań znaków drogowych może być wykonanych przy pracy DSP z częstotliwością 600MHz. Tensilica Vision P5 DSP firmy Cadence ma niemal idealny zestaw funkcji do uruchomienia CNNs.
„Artificial neural network.” Wikipedia. https://en.wikipedia.org/wiki/Artificial_neural_network
Karpathy, Andrej. 2015. „Sieci neuronowe Część 1: Konfigurowanie architektury.” Notes for CS231n Convolutional Neural Networks for Visual Recognition, Stanford University. http://cs231n.github.io/neural-networks-1/
„Convolutional neural network.” Wikipedia. https://en.wikipedia.org/wiki/Convolutional_neural_network
Sermanet, Pierre, and Yann LeCun. 2011. „Traffic Sign Recognition with Multi Scale Networks”. Courant Institute of Mathematical Sciences, New York University. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6033589
Ciresan, Dan, Ueli Meier, and Jürgen Schmidhuber. 2012. „Multi-column deep neural networks for image classi- fication.” 2012 IEEE Conference on Computer Vision and Pattern Recognition (New York, NY: Institute of Electrical and Electronics Engineers (IEEE)). http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6248110
Ciresan, Dan, Ueli Meier, Jonathan Masci, Luca M. Gambardella, and Jurgen Schmidhuber. 2011. „Flexible, High Performance Convolutional Neural Networks for Image Classification”. Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence-Volume Two: 1237-1242. Retrieved 17 November 2013. http://people.idsia.ch/~juergen/ijcai2011.pdf
Lawrence, Steve, C. Lee Giles, Ah Chung Tsoi, and Andrew D. Back. 1997. „Face Recognition: A Convolutional Neural Network Approach.” IEEE Transactions on Neural Networks, Volume 8; Issue 1. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=554195
Russakovsky, O. et al. 2014. „ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision. http://link.springer.com/article/10.1007/s11263-015-0816-y#
Ovtcharov, Kalin, Olatunji Ruwarse, Joo-Young Kim et al. Feb 22, 2015. „Accelerating Deep Convolutional Networks Using Specialized Hardware”. Microsoft Research. http://research-srv.microsoft.com/pubs/240715/CNN%20Whitepaper.pdf
Stallkamp, J., M. Schlipsing, J. Salmen, and C. Igel. „Man Vs. Computer: Benchmarking Machine Learning Algorithms For Traffic Sign Application.” IJCNN 2011. http://www.sciencedirect.com/science/article/pii/S0893608012000457
Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. „Long Short-Term Memory.” Neural Computation, 9(8):1735-1780. ftp://ftp.idsia.ch/pub/juergen/lstm.pdf
Graves, Alex. 2014. „Generating Sequences With Recurrent Neural Networks.” http://arxiv.org/abs/1308.0850
Schmidhuber, Jurgen. 2015. „Recurrent Neural Networks.” http://people.idsia.ch/~juergen/rnn.html
Olshausen, Bruno A., and David J. Field. 1996. „Emergence of simple-cell receptive field properties by learning a sparse code for natural images.” Nature 381.6583: 607-609. http://www.nature.com/nature/journal/v381/n6583/abs/381607a0.html
Hinton, G. E. i Salakhutdinov, R. R. 2006. „Zmniejszanie wymiarowości danych za pomocą sieci neuronowych.” Science vol. 313 nr 5786 s. 504-507. http://www.sciencemag.org/content/suppl/2006/08/04/313.5786.504.DC1.
Hinton, Geoffrey E. 2009. „Głębokie sieci przekonań.” Scholarpedia, 4(5):5947.
http://www.scholarpedia.org/article/Deep_belief_networks