Reddit AmItheAsshole jest milszy dla kobiet niż dla mężczyzn – dowód SQL?
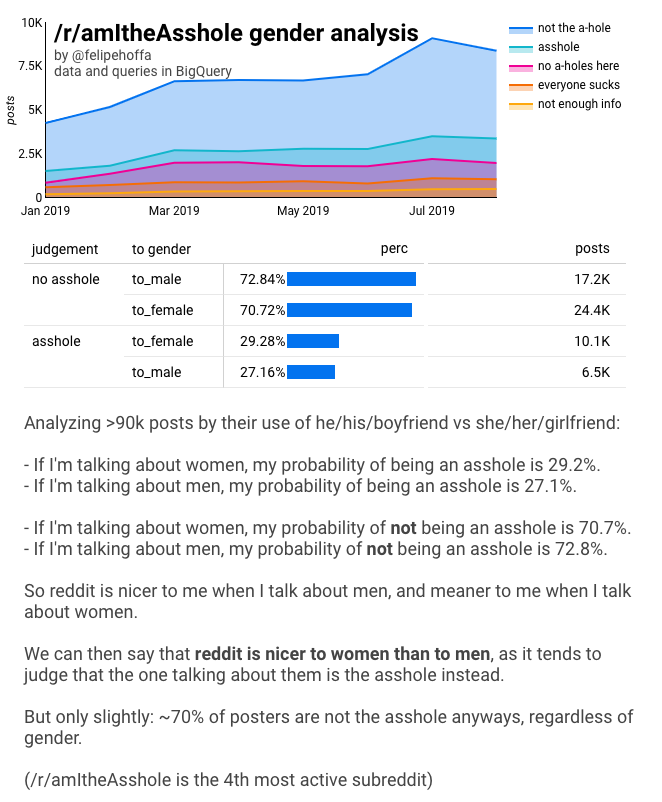
Gdy redditorzy pytają „czy jestem dupkiem”, mówiąc o kobietach, mają większą szansę na bycie ocenionym jako dupek. Let’s check out these metrics – with BigQuery, dbt, and Data Studio
Make sure to not take anything I wrote here as the absolute truth. Kilka osób na Twitterze zauważyło problemy i dodało poprawki do analizy, którą zaoferowałem. Czytanie tego postu jako pierwotnie przedstawionego – i reakcji – może być świetnym sposobem na nauczenie się tak wiele, jak ja to zrobiłem podczas czytania odpowiedzi. Możesz znaleźć wiele z ich niefiltrowanych myśli, śledząc ten wątek na Twitterze.
Kontekst
/r/amItheAsshole urósł do rangi 4. najbardziej aktywnego subreddita – pod względem liczby komentarzy. Ludzie przychodzą na ten subreddit, aby opowiedzieć swoje historie i pytają innych redaktorów „czy ja jestem tutaj dupkiem?”. Okazuje się, że większość ludzi jest oceniana jako „nie dupek”, co widać na tym wykresie:
Mój tweet z tymi wynikami zyskał sporo uwagi:
W tym pytanie – czy reddit jest milszy dla kobiet czy dla mężczyzn?
Deciding gender
Patrząc na tytuł lub treść postu, możesz mieć problem z określeniem, czy „ja” jest mężczyzną czy kobietą – ale całkiem łatwo policzyć liczbę „ona/on/on/jego/dziewczyna/chłopak” obecnych w opowiadaniu.
Spójrzmy na kilka losowych postów, i liczbę dla każdego z tych zaimków i słów genderowych:

Możemy zauważyć, że liczba zaimków i słów związanych z płcią w przykładzie pasuje do tego, o kim jest historia. Te historie są o męskim kliencie, kobiecej dziewczynie, męskim sąsiedzie, męskim synu i kobiecej nastoletniej córce.
Z tymi liczbami, możemy teraz ustalić arbitralną regułę: Jeśli jest więcej niż podwójna liczba męskich zaimków niż żeńskich, ten post jest o mężczyźnie. Możemy użyć przeciwnej zasady, aby powiedzieć, że post jest o kobiecie. Jeśli liczby są zbyt bliskie lub zerowe, nazwiemy post „neutralnym”.
Inna reguła, którą możemy ustalić, aby uprościć analizę:
- Jeśli osąd jest „nie jest dupkiem” lub „nie ma tu dupków”, wtedy możemy powiedzieć „plakat nie jest dupkiem”.
- Jeśli osąd jest 'dupek’ lub 'wszyscy są do dupy’ wtedy możemy powiedzieć 'plakat jest dupkiem’.
Jeśli zsumujemy wszystkie te posty, otrzymamy liczby:

Kiedy po raz pierwszy przedstawiłem te wyniki, powiedziano mi „te liczby są zbyt bliskie, mogą być błędem statystycznym”.
istotność statystyczna?
Jak możemy stwierdzić, że liczby nie są jedynie błędem statystycznym? Zobaczmy trend miesiąc po miesiącu – czy jest stabilny?

Tak! Trend zmienia się z miesiąca na miesiąc, ale jest wyraźnie wyższa szansa na bycie dupkiem, gdy mowa o kobietach, niż gdy mowa o mężczyznach. Gdyby ta niewielka różnica była tylko statystycznym fuksem, spodziewalibyśmy się, że zamiast tego trend przeskoczy dziko.
I proszę zauważyć, że te wyniki są bardzo specyficzne, jak zauważa ten tweet:
Na który odpowiedziałem
How-to
Tym razem używam dbt po raz pierwszy i zostawiłem cały mój kod na GitHubie. Dzięki Claire Carroll za pomoc w rozpoczęciu pracy z tym niesamowitym narzędziem!
Aby wyodrębnić wszystkie posty /r/AmItheAsshole w BigQuery do nowej tabeli, możesz zrobić:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Potem płeć i osąd dla każdego postu można określić za pomocą zapytania takiego jak:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
I wreszcie statystyki przedstawione tutaj:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Dyskusja
Znajdziesz mnóstwo wnikliwych i zabawnych odpowiedzi na twitterowym wątku dla tego postu:
Nie krępuj się dołączyć do dyskusji (i powiedz mi, jeśli się mylę?). Pamiętaj, aby być miłym dla siebie nawzajem – większość ludzi i tak nie jest dupkiem.
Chcesz więcej?
Obejmowałem tylko do sierpnia 2019 r., Ponieważ to jest, gdy obecne pełne archiwum reddit w BigQuery zatrzymuje się – do czasu przyszłych oczekiwanych aktualizacji. Sprawdź mój poprzedni post, aby uzyskać więcej szczegółów na temat zbierania danych na żywo z pushshift.io. Dzięki Jason Baumgartner za stałą dostawę!
Jestem Felipe Hoffa, Developer Advocate dla Google Cloud. Śledź mnie na @felipehoffa, znajdź moje poprzednie posty na medium.com/@hoffa, a wszystko o BigQuery na reddit.com/r/bigquery.