Real Time vs Batch Processing vs Stream Processing
Przy stałym tempie innowacji, programiści mogą spodziewać się analizowania terabajtów, a nawet petabajtów danych w dowolnym okresie czasu. (Dane, mimo wszystko, przyciągają więcej danych.)
To pozwala na liczne korzyści, oczywiście. Ale co zrobić z tymi wszystkimi danymi? Może być trudno poznać najlepszy sposób na przyspieszenie i przyspieszenie tych technologii, zwłaszcza gdy reakcje muszą zachodzić szybko.
Dla firm typu digital-first coraz częściej pojawia się pytanie, jak najlepiej wykorzystać przetwarzanie w czasie rzeczywistym, przetwarzanie wsadowe i przetwarzanie strumieniowe. Ten post wyjaśni podstawowe różnice między tymi typami przetwarzania danych.
Systemy operacyjne czasu rzeczywistego
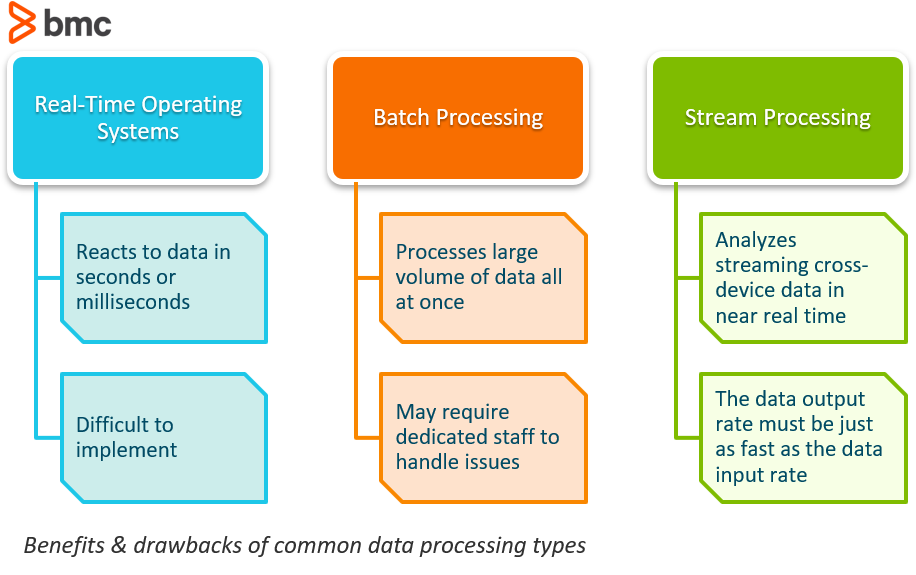
Systemy operacyjne czasu rzeczywistego zazwyczaj odnoszą się do reakcji na dane. System może być skategoryzowany jako czas rzeczywisty, jeśli może zagwarantować, że reakcja będzie w ścisłym terminie rzeczywistym, zwykle w ciągu kilku sekund lub milisekund.
Jednym z najlepszych przykładów systemu czasu rzeczywistego są te używane na giełdzie. Jeśli cytat akcji powinny pochodzić z sieci w ciągu 10 milisekund od umieszczenia, to byłoby to uważane za proces w czasie rzeczywistym. Czy zostało to osiągnięte przy użyciu architektury oprogramowania, która wykorzystała przetwarzanie strumieniowe lub po prostu przetwarzanie w sprzęcie jest nieistotne; gwarancja napiętego terminu jest tym, co czyni go w czasie rzeczywistym.
Inne sytuacje, w których korzystanie z systemów czasu rzeczywistego byłoby korzystne to:
- ATM
- Kontrola ruchu lotniczego
- Systemy zapobiegające blokowaniu się hamulców w samochodzie
Wyzwania
Choć ten typ systemu brzmi jak zmieniacz gry, rzeczywistość jest taka, że systemy czasu rzeczywistego są niezwykle trudne do wdrożenia poprzez wykorzystanie wspólnych systemów oprogramowania. Ponieważ systemy te przejmują kontrolę nad wykonaniem programu, wnoszą zupełnie nowy poziom abstrakcji.
To oznacza, że rozróżnienie między przepływem sterowania programu a kodem źródłowym nie jest już widoczne, ponieważ system czasu rzeczywistego wybiera, które zadanie wykonać w danym momencie. Jest to korzystne, ponieważ pozwala na wyższą wydajność przy użyciu wyższej abstrakcji i może ułatwić projektowanie złożonych systemów, ale oznacza to mniejszą ogólną kontrolę, co może być trudne do debugowania i walidacji.
Innym wspólnym wyzwaniem z systemami operacyjnymi czasu rzeczywistego jest to, że zadania nie są izolowanymi jednostkami. System decyduje, które z nich zaplanować i wysyła zadania o wyższym priorytecie przed zadaniami o niższym priorytecie, opóźniając w ten sposób ich wykonanie, dopóki wszystkie zadania o wyższym priorytecie nie zostaną ukończone.
Coraz więcej, niektóre systemy oprogramowania zaczynają iść w kierunku smaku przetwarzania w czasie rzeczywistym, gdzie termin nie jest tak absolutny, jak jest to prawdopodobieństwo. Znane jako miękkie systemy czasu rzeczywistego, są one w stanie zazwyczaj lub ogólnie spełnić swój termin, chociaż wydajność zacznie się pogarszać, jeśli zbyt wiele terminów zostanie pominiętych.
Przetwarzanie wsadowe
Przetwarzanie wsadowe to przetwarzanie dużej ilości danych jednocześnie. Dane łatwo składają się z milionów rekordów na dzień i mogą być przechowywane w różny sposób (plik, rekord, itp.). Zadania są zazwyczaj wykonywane jednocześnie w non-stop, w kolejności sekwencyjnej.
Przykładem przetwarzania wsadowego są wszystkie transakcje, które firma finansowa może złożyć w ciągu tygodnia. Przetwarzanie wsadowe może być również stosowane w:
- Procesach płacowych
- Fakturach pozycji
- Łańcuchu dostaw i realizacji
Wsadowe przetwarzanie danych jest niezwykle wydajnym sposobem przetwarzania dużych ilości danych, które są gromadzone przez pewien okres czasu. Pomaga również zmniejszyć koszty operacyjne, które firmy mogą wydać na pracę, ponieważ nie wymaga wyspecjalizowanych urzędników do wprowadzania danych, aby wspierać jego funkcjonowanie. Może być używany w trybie offline i daje menedżerom pełną kontrolę, kiedy rozpocząć przetwarzanie, czy to z dnia na dzień lub na koniec tygodnia lub pay period.
Wyzwania
Jak ze wszystkim, istnieje kilka wad do korzystania z oprogramowania przetwarzania partii. Jednym z największych problemów, że firmy widzą jest to, że debugowanie tych systemów może być trudne. Jeśli nie masz dedykowany zespół IT lub profesjonalny, próbując naprawić system, gdy pojawia się błąd może być szkodliwe, powodując potrzebę zewnętrznego konsultanta do assist.
Innym problemem z przetwarzania wsadowego jest to, że firmy zazwyczaj wdrażają go, aby zaoszczędzić pieniądze, ale oprogramowanie i szkolenia wymaga przyzwoitą ilość wydatków na początku. Menedżerowie będą musieli zostać przeszkoleni, aby zrozumieć:
- Jak zaplanować partię
- Co je wyzwala
- Co oznaczają pewne powiadomienia
(Dowiedz się więcej o nowoczesnym przetwarzaniu wsadowym.)
Przetwarzanie strumieniowe
Przetwarzanie strumieniowe jest procesem umożliwiającym niemal natychmiastową analizę danych, które są przesyłane strumieniowo z jednego urządzenia do drugiego.
Ta metoda ciągłych obliczeń ma miejsce, gdy dane przepływają przez system bez obowiązkowych ograniczeń czasowych na wyjściu. Z prawie natychmiastowym przepływem, systemy nie wymagają dużych ilości danych do przechowywania.
Przetwarzanie strumieniowe jest bardzo korzystne, jeśli zdarzenia, które chcesz śledzić dzieją się często i blisko siebie w czasie. Jest to również najlepszy do wykorzystania, jeśli zdarzenie musi być wykryte od razu i reagować na szybko. Przetwarzanie strumieniowe jest zatem przydatne do zadań takich jak wykrywanie oszustw i bezpieczeństwo cybernetyczne. Jeśli dane transakcji są przetwarzane strumieniowo, oszukańcze transakcje mogą być zidentyfikowane i zatrzymane zanim jeszcze zostaną ukończone.
Wyzwania
Jednym z największych wyzwań, jakie stoją przed organizacjami w związku z przetwarzaniem strumieniowym jest to, że długoterminowy wskaźnik wyjściowy danych systemu musi być tak szybki, lub szybszy, niż długoterminowy wskaźnik wejściowy danych, w przeciwnym razie system zacznie mieć problemy z przechowywaniem i pamięcią.
Innym wyzwaniem jest próba znalezienia najlepszego sposobu radzenia sobie z ogromną ilością danych, które są generowane i przenoszone. Aby utrzymać przepływ danych przez system działający na najwyższym optymalnym poziomie, konieczne jest, aby organizacje stworzyły plan, jak zmniejszyć liczbę kopii, jak ukierunkować jądra obliczeniowe i jak wykorzystać hierarchię pamięci podręcznej w najlepszy możliwy sposób.
Wniosek
Choć wszystkie te systemy mają zalety, na koniec dnia organizacje powinny rozważyć potencjalne korzyści każdego z nich, aby zdecydować, która metoda jest najlepsza dla danego przypadku użycia.
Dodatkowe zasoby
- BMC Workload Automation Blog
- BMC Big Data Blog
- Przewodnik początkującego automatyka miejsca pracy
- Co to jest zadanie wsadowe?
- Co to jest rurociąg danych?
Manage sl as for your batch services joe goldberg z BMC Software
Take a modern approach to batch processing

Te posty są mojego autorstwa i nie muszą reprezentować stanowiska, strategii lub opinii BMC.
Widzisz błąd lub masz sugestię? Proszę dać nam znać, wysyłając e-mail na adres [email protected].
.