Jak zbudować nowoczesny silnik reguł biznesowych, szybki przegląd
To jest wysokopoziomowy, koncepcyjny przegląd architektury silnika reguł biznesowych. Znajduje się on powyżej rzeczywistego kodu. Jeśli budujesz silnik reguł biznesowych – jest wysoce prawdopodobne, że ten tekst może Ci się przydać.
Kiedyś zbudowałem silnik reguł biznesowych, który umożliwiał automatyzację biznesu w małych i średnich firmach, a także miał wszelkie możliwości i potencjał, aby dobrze służyć dużym przedsiębiorstwom. Była to droga od zwykłej aplikacji do wyrafinowanego i złożonego rozwiązania, które spełniało trudne wymagania skalowalności, łatwości utrzymania i rozszerzalności. W tym tekście przedstawimy przegląd tego, czym jest silnik reguł biznesowych, i opiszemy jedno z nowoczesnych podejść do jego budowy, które można rozważyć przy tworzeniu tego rodzaju oprogramowania.
Na początek ważne jest zdefiniowanie podstawowych pojęć. Silniki reguł biznesowych istnieją w branży od dłuższego czasu w takiej czy innej formie i istnieją pewne definicje dla prawie każdego terminu, którego będziemy używać. Zacznijmy od „reguły biznesowej” – istnieje dobrze znana definicja tego terminu. Tak więc „reguła biznesowa” to:
Oświadczenie, które definiuje lub ogranicza jakiś aspekt działalności. Ma ona na celu zapewnienie struktury biznesowej lub kontrolowanie lub wpływanie na zachowanie biznesu.
T. Morgan, Reguły biznesowe i systemy informacyjne. Boston: Addison-Wesley Publishing, 2002
Reguły biznesowe mają bardzo szeroki zakres i mogą być stosowane do dowolnego aspektu działalności przedsiębiorstwa. Na przykład, reguła „Kiedy przychodzi klient, przywitaj go ciepłym uśmiechem i przyjaznym „Witam”” jest stosowana przez pracownika firmy podczas spotkań z klientami. Inna reguła może określać lub ograniczać podejście do rozwiązywania rutynowych zadań przez określoną rolę w firmie. Wraz ze stałym wzrostem popularności rozwiązań programowych, takich jak systemy CRM, oraz z całkowitą integracją oprogramowania z różnymi dziedzinami biznesu, większość procesów biznesowych stała się częściowo lub całkowicie zorientowana na dane. Doprowadziło to do przekształcenia reguł biznesowych tak, że stały się one zorientowane na oprogramowanie, na przykład reguła biznesowa „Kiedy klient kupuje coś w naszym sklepie, zadzwoń do niego później z pytaniem, czy chciałby kupić inne powiązane towary” przekształciła się w bardziej nowoczesną „Kiedy klient kupuje coś w naszym sklepie internetowym, wyślij mu e-mail z listą innych powiązanych towarów później”. W dzisiejszych czasach wiele firm w swojej codziennej działalności ma do czynienia głównie z danymi. Biorąc pod uwagę, że większość firm każdej wielkości posiada zintegrowane oprogramowanie do swojej działalności biznesowej, definicja terminu „reguła biznesowa” może być określona w bardziej szczegółowy sposób poprzez dodanie wyjaśnienia (jest ono pogrubione) do wyżej wymienionej definicji autorstwa T. Morgana:
Reguła biznesowa jest stwierdzeniem, które definiuje lub ogranicza jakiś aspekt działalności. Ma ona na celu zapewnienie struktury biznesowej lub kontrolę lub wpływ na zachowanie przedsiębiorstwa. Przechowywana jest jako konstrukt danych w pamięci trwałej i zawiera atomowy pakiet logiki biznesowej. Jest zarządzana i stosowana w procesach biznesowych firmy automatycznie za pomocą oprogramowania.
Po zdefiniowaniu terminu „reguła biznesowa”, termin „System Zarządzania Silnikiem Reguł Biznesowych” (BRMS) definiuje się następująco:
BRMS to oprogramowanie do zarządzania (przechowywania, edycji i usuwania, itp.) regułami biznesowymi, jak również do stosowania ich w procesach biznesowych firmy.
Standardowe komercyjne systemy BRMS mogą być bardzo drogie w zakupie licencji oraz w integracji z infrastrukturą informatyczną firmy, dlatego firmy często wdrażają rozwiązania własne, gdy napotykają na potrzebę automatyzacji procesów biznesowych lub innego rodzaju procesów.
BRMS-y mogą stać się istotną i kluczową częścią każdego biznesu. Czasami sukces firmy może zależeć od reguł biznesowych, które ona posiada i od tego, jak dobrze te reguły biznesowe są zarządzane i stosowane.
Konstrukcja danych reguł biznesowych
Reguła biznesowa może być reprezentowana jako konsekwentna seria atomowych poleceń. Polecenia mogą obejmować warunkową analizę danych, polecenia oczekiwania na czas, polecenia wykonania akcji itp. Przykład reguły biznesowej „Gdy klient kupi coś w naszym sklepie internetowym, wyślij mu później e-mail z listą innych powiązanych towarów” jest dobry i ogólny, a wiele innych reguł biznesowych może mieć bardzo podobną strukturę logiczną:

Przepływ przetwarzania reguły jest uruchamiany w momencie dokonania zakupu i stosowana jest pewna logika biznesowa poprzez wykonanie polecenia „Wyślij do kupującego e-mail z odpowiednimi ofertami towarów”. Może się zdarzyć, że kupujący wyłączył subskrypcję e-maili. Wówczas do reguły biznesowej należy dodać dodatkowy warunek – „jeśli kupujący ma włączoną subskrypcję e-mail”:

Komendy są wykonywane konsekwentnie i teraz jest polecenie analizy danych sprawdzające, czy kupujący ma aktywną subskrypcję e-mail. Jeśli tak – przejdź do wykonania kolejnego polecenia reguły biznesowej. A jeśli nie – nie kontynuuj, reguła biznesowa jest uznawana za zakończoną, przepływ przetwarzania zatrzymuje się, kolejne polecenia nie są wykonywane.
Kupujący może mieć również subskrypcję SMS i jeśli jest ona aktywna, to również powinno być kolejne polecenie – „Wyślij SMS z powiązaną ofertą promocyjną”. Dzięki temu do logiki reguły biznesowej wprowadzono rozgałęzienie:
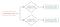
Gałęzie reguły są przetwarzane niezależnie od siebie. Przetwarzanie jednej z gałęzi może zatrzymać się na poleceniu oceny warunku, a inna gałąź może być przetwarzana aż do końca.
UI aplikacji BRMS po stronie klienta do reprezentacji reguły biznesowej może być zaimplementowane na różne sposoby (zadziała każdy rodzaj drzewiastej reprezentacji graficznej):

Konstrukcja danych reguły biznesowej jest skierowanym, zakorzenionym grafem drzewiastym (skierowany graf acykliczny, który ma drzewo jako bazowy graf nieskierowany). Wierzchołki grafu reguł biznesowych są reprezentowane przez różne rodzaje poleceń: polecenia analizy danych, polecenia wykonania akcji, polecenia oczekiwania na czas itd. Każde skierowane, ukorzenione drzewo posiada korzeń – wierzchołek, z którego wychodzą wszystkie krawędzie. Tak więc każda reguła zaczyna się od specjalnego wierzchołka (lub wierzchołka korzenia w terminologii teorii grafów) – wierzchołka, który wyznacza punkt wejścia do przetwarzania reguły.
OperacjeCRUD na konstrukcji danych reguł biznesowych
Ponieważ konstrukcja danych jest reprezentowana przez skierowane, ukorzenione drzewo, a nie jakikolwiek inny rodzaj grafu, uwalnia nas to od niedogodności towarzyszących przechowywaniu ogólnych struktur grafowych w RDBMS (jak przechowywanie wierzchołków i krawędzi w różnych tabelach, co może skutkować zwiększoną liczbą odwołań do pojedynczej reguły, itp.) A jest to krytyczne, ponieważ jest jasne, że podczas normalnego działania BRMS odszukiwania danych zdarzają się znacznie częściej, niż inne operacje, takie jak inserty, aktualizacje czy usunięcia.

Przypominamy – każdy wierzchołek reguły biznesowej reprezentuje polecenie atomowe. Jest ono zapisane w tabeli RDBMS jako rekord z atrybutami takimi jak typ polecenia, opis i inne dane uzupełniające. W drzewie każdy wierzchołek ma jednego i tylko jednego rodzica (z wyjątkiem wierzchołka korzenia, który nie ma rodziców), więc każdy rekord powinien zawierać ID wierzchołka rodzica. Wygodnie jest również posiadać inną tabelę, w której przechowywane są rekordy reguł zawierające dane istotne dla samej reguły biznesowej. Nie ma problemu z przechowywaniem danych reguł biznesowych o dowolnej złożoności przy takim podejściu.
Operacje CRUD są dość proste. Zmiany w regule biznesowej mogą wymagać aktualizacji jednej lub obu tabel – reguł lub poleceń. Podczas usuwania lub wstawiania poleceń konieczne jest zachowanie referencji pomiędzy poleceniami (jest to w istocie usuwanie lub wstawianie węzłów do drzewa).
Jeden z komponentów BRMS, nazwijmy go menedżerem, powinien wykonywać opisane operacje bazodanowe i udostępniać API dla operacji CRUD na regułach biznesowych.
Przetwarzanie reguły biznesowej
Przetwarzanie reguły biznesowej rozpoczyna się w momencie wystąpienia określonego zdarzenia biznesowego. Może to być cokolwiek – użytkownik zalogował się, dokonano zakupu, przelano jakąś kwotę pieniędzy, itp. Tego typu aktywność powinna być śledzona, a BRMS powinien być o niej informowany za pomocą jakiegoś transportu. AMQP najprawdopodobniej najlepiej nadaje się do tego typu zadań.

1. Cała koncepcja zbudowana jest w oparciu o architekturę mikroserwisów. Mikroserwis będący konsumentem zdarzeń biznesowych nasłuchuje wszystkich zdarzeń biznesowych poprzez zadeklarowanie kolejki i powiązanie jej z określoną wymianą na serwerze wymiany RabbitMQ. Kiedy w głównym systemie oprogramowania wydarzy się jakaś czynność biznesowa (która jest uważana za istotną i jest śledzona), wiadomość jest wysyłana do serwera wymiany RabbitMQ. Zawiera ona informacje o tym, co się wydarzyło, jak również pewne istotne dane uzupełniające. Zdarzenie biznesowe może być zidentyfikowane za pomocą dowolnego atrybutu przekazanego w wiadomości lub użytego jako klucz routingu, na przykład ciąg purchase.completed. Komunikat jest następnie konsumowany przez mikrousługę konsumenta zdarzeń biznesowych BRMS.

2. Gdy mikrousługa konsumenta zdarzeń biznesowych otrzyma komunikat z głównego systemu oprogramowania, to następnie odpytuje mikrousługę menedżera, czy w bazie danych znajdują się jakieś reguły biznesowe, które mają odpowiedni wyzwalacz regułowy dla danego zdarzenia aktywności biznesowej. I jeśli istnieje taka pasująca reguła biznesowa, mikroserwis menedżera zwraca początkowe dane polecenia do mikroserwisu konsumenta zdarzeń biznesowych. To pobieranie danych z menedżera odbywa się za pomocą gRPC i jest wizualizowane linią przerywaną.
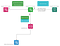
3. Zaraz po tym, jak mikroserwis menedżera odpowie z początkowymi danymi polecenia, mikroserwis konsumenta zdarzeń biznesowych jest gotowy do zainicjowania przetwarzania reguły biznesowej. Konsument zdarzeń biznesowych tworzy kolejny komunikat, który enkapsuluje początkowe dane komendy (otrzymane od mikroserwisu menedżera) oraz dane ze zdarzenia biznesowego, otrzymane z głównego systemu oprogramowania. Wysyła je za pomocą AMQP do wewnętrznej centrali BRMS. Klucz routingu komunikatu odpowiada typowi komendy.
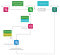
4. Initial command processing microservice konsumuje komunikat (nasłuchuje kolejki, w której ułożone są komunikaty z kluczem routingu initial). Następnie wykonuje swoją logikę (w podstawowym przypadku blok początkowy nie zawiera żadnej logiki) i odpytuje menedżera, czy w regule biznesowej istnieją kolejne polecenia (są to polecenia o parent_id równym id polecenia, które jest aktualnie przetwarzane). A jeśli tak, to odbiera dane następnej komendy i wysyła zarówno dane zdarzenia biznesowego jak i dane następnej komendy do wewnętrznego serwera RabbitMQ. Tak, wygląda to teraz jak traversal listy połączonej, a gdy reguła ma gałęzie, to jest to traversal drzewa! W ten sposób reguła biznesowa jest przetwarzana komenda po komendzie. Kolejna ważna rzecz – w tym kontekście, dane zdarzenia biznesowego są przekazywane do każdej komendy potomnej. Jest to kontekst unikalnego wykonania reguły biznesowej. Może on być wykorzystany później w procesorze poleceń analizy danych i procesorze poleceń akcji.
Dla celów ilustracyjnych załóżmy, że przykładowa reguła ma następującą strukturę: polecenie początkowe -> polecenie warunkowej analizy danych -> polecenie akcji biznesowej. Wówczas kolejnym poleceniem po początkowym jest polecenie analizy danych.

5. Procesor polecenia analizy zużywa komunikat z kluczem routingu analysis z wymiany wewnętrznej. Na podstawie oceny warunków, które zostały opisane w poleceniu analizy reguły biznesowej i przy wykorzystaniu danych o zdarzeniach biznesowych, przepływ wykonania reguły może być kontynuowany lub zatrzymany w tym miejscu. W przypadku zatrzymania – nie są wykonywane dalsze polecenia reguły biznesowej. Jeśli przepływ wykonawczy jest kontynuowany, procesor polecenia analizy odpytuje menedżera o kolejne polecenia reguły biznesowej, pobiera je i publikuje kolejny komunikat na wewnętrznym serwerze wymiany.
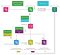
6. Wreszcie, w wewnętrznej wymianie znajduje się komunikat, który jest gotowy do skonsumowania przez procesor poleceń akcji. Jeżeli strumień wykonawczy reguły biznesowej dotarł do tego polecenia, oznacza to, że w tej gałęzi reguły każdy warunek, który znajdował się w poleceniu analizy danych był prawdziwy i strumień wykonawczy nie został przerwany. Procesor polecenia akcji wykonuje akcję, np. wysyła e-mail.
Ten rodzaj trawersowania grafu jest typu depth-first, a gdy napotkane zostanie polecenie z 2 lub więcej poleceniami podrzędnymi, rozpoczyna się jednoczesne trawersowanie depth-first dla każdej gałęzi ze względu na asynchroniczny charakter przetwarzania reguł biznesowych w opisywanym systemie.
Skalowanie
Opisane podejście pozwala nie tylko na świetne odseparowanie problemów, ale również może zaoszczędzić sporo pieniędzy, jeśli chodzi o płacenie rachunków za IaaS. Użytkownicy końcowi tworzą różne reguły biznesowe z różną liczbą poleceń różnego rodzaju i różną liczbą gałęzi. Jednak najczęściej spotykane scenariusze skalowania są następujące:
1. Zwiększa się liczba zdarzeń biznesowych – skaluje się konsument zdarzeń biznesowych.
2. Zwiększa się liczba reguł biznesowych powiązanych (wyzwalanych) przez zdarzenia biznesowe – skaluje się procesor poleceń początkowych wraz z menedżerem.
3. W regułach biznesowych jest wiele poleceń analizy – skaluje się procesor poleceń analizy
4. Trzeba wykonać zbyt wiele poleceń akcji – skaluje się procesor poleceń akcji.
Zawodność
Naczyniem krwionośnym systemu jest transport. Aby system mógł działać przy dużym obciążeniu, wewnętrzna wymiana komunikatów powinna być wysoce niezawodna. RabbitMQ zapewnia klastrowanie i dobrze spełnia wymagania niezawodności (https://www.rabbitmq.com/clustering.html).
Inne typy poleceń
Do systemu może zostać wprowadzona dowolna inna logika biznesowa. Jednym z popularnych i pożądanych typów poleceń jest polecenie time wait (np. „Czekaj 45 minut, potem kontynuuj”). Wraz z wprowadzeniem polecenia time-wait przetwarzanie reguły biznesowej przestaje być przetwarzaniem w czasie rzeczywistym, gdyż może zostać zawieszone na pewien czas. Takie zmiany wymagają dodatkowych procesorów poleceń i kilku poprawek w strukturach danych, które są poza zakresem tego tekstu. Zabawa z czasem może być trudna, a napisanie usługi, która obsługuje harmonogramy i czas może być wyzwaniem, oto przykład dobrego: https://github.com/nextiva/krolib
Third-party alternatives
Istnieją znane alternatywy silników reguł / silników przepływu pracy, oto top 3 z nich (IMHO):
1. Comunda – jest to dojrzały produkt z wersjami community i enterprise, z którego możesz chcieć skorzystać. Oczywiście, wersja enterprise jest płatna.
2. Luigi – jest to silnik przepływu pracy opracowany przez Spotify dla ich wewnętrznych potrzeb, ale używany już przez dziesiątki innych firm.
3. Apache Airflow – jest to kolejny dobrze znany produkt, który udowodnił, że jest zdolny, wygodny i konfigurowalny.
To co łączy te narzędzia, to fakt, że wszystkie one używają bezpośrednich grafów acyklicznych jako struktury danych, która reprezentuje reguły biznesowe lub przepływy pracy. To nie jest niespodzianka.
Mogą istnieć inne produkty warte uwagi, ale każde dochodzenie powinno rozpocząć się od tych trzech.
Wniosek
Budowanie własnego silnika reguł biznesowych może być wyzwaniem, ale jest satysfakcjonujące. Nie dość, że dostajesz system wewnętrzny, to jeszcze jest on zbudowany zgodnie z konkretnymi wymaganiami Twojego biznesu. Dobry zespół DevOps jest koniecznością, jeśli chodzi o utrzymanie niezawodności, skalowalności i monitorowania. Po tym wszystkim, otrzymujesz fantastyczny produkt, z którego możesz być dumny.