GeeksforGeeks
Arrays przechowują elementy w sąsiadujących lokalizacjach pamięci, co skutkuje łatwymi do obliczenia adresami przechowywanych elementów, a to pozwala na szybszy dostęp do elementu o określonym indeksie. Listy połączone są mniej sztywne w swojej strukturze przechowywania i elementy zazwyczaj nie są przechowywane w sąsiadujących lokalizacjach, stąd muszą być przechowywane z dodatkowymi znacznikami podającymi referencję do kolejnego elementu. Ta różnica w schemacie przechowywania danych decyduje o tym, która struktura danych będzie bardziej odpowiednia w danej sytuacji.
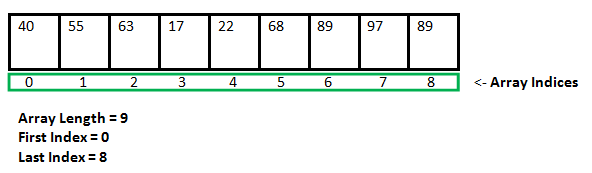
Schemat przechowywania danych tablicy
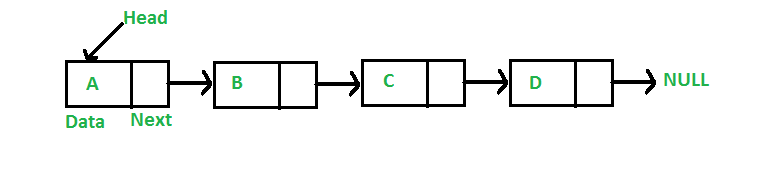
Schemat przechowywania danych listy połączonej
Główne różnice są wymienione poniżej:
- Rozmiar: Ponieważ dane mogą być przechowywane tylko w ciągłych blokach pamięci w tablicy, ich rozmiar nie może być zmieniany w czasie wykonywania ze względu na ryzyko nadpisania nad innymi danymi. Jednak w połączonej liście każdy węzeł wskazuje na następny, tak że dane mogą istnieć w rozproszonych (nie przylegających) adresach; pozwala to na dynamiczny rozmiar, który może się zmienić w czasie wykonywania.
- Alokacja pamięci: Dla tablic w czasie kompilacji i w czasie runtime dla list połączonych.
- Wydajność pamięci: Dla tej samej liczby elementów listy połączone zużywają więcej pamięci, ponieważ wraz z danymi przechowywane jest również odwołanie do następnego węzła. Jednak elastyczność rozmiaru w listach połączonych może sprawić, że ogólnie zużywają one mniej pamięci; jest to przydatne, gdy istnieje niepewność co do rozmiaru lub występują duże różnice w rozmiarze elementów danych; pamięć równa górnej granicy rozmiaru musi zostać zaalokowana (nawet jeśli nie cała jest używana) podczas korzystania z tablic, podczas gdy listy połączone mogą zwiększać swoje rozmiary krok po kroku proporcjonalnie do ilości danych.
- Czas wykonania: Każdy element w tablicy może być bezpośrednio dostępny z jego indeksem; jednak w przypadku listy połączonej, wszystkie poprzednie elementy muszą być przemierzone, aby dotrzeć do dowolnego elementu. Ponadto, lepsza lokalizacja pamięci podręcznej w tablicach (ze względu na kontinuum alokacji pamięci) może znacznie poprawić wydajność. W rezultacie niektóre operacje (takie jak modyfikowanie określonego elementu) są szybsze w tablicach, podczas gdy niektóre inne (takie jak wstawianie / usuwanie elementu w danych) są szybsze w listach połączonych.
Następujące punkty przemawiają na korzyść Linked Lists.
(1) Rozmiar tablic jest stały: więc musimy znać górną granicę liczby elementów z góry. Ponadto, na ogół przydzielona pamięć jest równa górnej granicy niezależnie od użycia, a w praktycznych zastosowaniach górna granica jest rzadko osiągana.
(2) Wstawienie nowego elementu do tablicy elementów jest kosztowne, ponieważ musi zostać utworzone miejsce dla nowych elementów, a w celu utworzenia miejsca istniejące elementy muszą zostać przesunięte.
Na przykład załóżmy, że utrzymujemy posortowaną listę identyfikatorów w tablicy id.
id = .
A jeśli chcemy wstawić nowy identyfikator 1005, to aby zachować posortowaną kolejność, musimy przesunąć wszystkie elementy po 1000 (z wyłączeniem 1000).
Deletion jest również drogie z tablicami, dopóki nie zostaną użyte pewne specjalne techniki. Na przykład, aby usunąć 1010 w id, wszystko po 1010 musi zostać przeniesione.
So Linked list zapewnia następujące dwie zalety w stosunku do tablic
1) Dynamiczny rozmiar
2) Łatwość wstawiania/usuwania
Listy połączone mają następujące wady:
1) Dostęp losowy nie jest dozwolony. Musimy uzyskać dostęp do elementów sekwencyjnie, zaczynając od pierwszego węzła. Więc nie możemy zrobić wyszukiwania binarnego z połączonymi listami.
2) Dodatkowe miejsce w pamięci dla wskaźnika jest wymagane z każdym elementem listy.
3) Tablice mają lepszą lokalność pamięci podręcznej, która może zrobić całkiem dużą różnicę w wydajności.
.