Big Data and Hadoop Ecosystem Tutorial
Witamy w pierwszej lekcji „Big Data and Hadoop Ecosystem” samouczka Big Data Hadoop, który jest częścią „Big Data Hadoop and Spark Developer Certification course” oferowanego przez Simplilearn. Ta lekcja jest wprowadzeniem do Big Data i ekosystemu Hadoop. W następnej sekcji omówimy cele tej lekcji.
Cele
Po ukończeniu tej lekcji będziesz w stanie:
-
Zrozumieć koncepcję Big Data i związane z nią wyzwania
-
Wyjaśnić, czym jest Big Data
-
Wyjaśnić, czym jest Hadoop. i jak odpowiada na wyzwania związane z Big Data
-
Opisać ekosystem Hadoop
Przyjrzyjrzyjmy się teraz przeglądowi Big Data i Hadoop.
Overview to Big Data and Hadoop
Przed rokiem 2000 dane były stosunkowo mniejsze niż obecnie; jednak obliczenia danych były złożone. Wszystkie obliczenia na danych zależały od mocy obliczeniowej dostępnych komputerów.
Później, gdy dane rosły, rozwiązaniem było posiadanie komputerów z dużą pamięcią i szybkimi procesorami. Jednak po roku 2000 dane wciąż rosły i początkowe rozwiązanie nie mogło już pomóc.
W ciągu ostatnich kilku lat nastąpiła niesamowita eksplozja ilości danych. Firma IBM podała, że w 2012 roku każdego dnia generowano 2,5 eksabajta, czyli 2,5 miliarda gigabajtów danych.
Oto kilka statystyk wskazujących na proliferację danych z Forbes, wrzesień 2015 r. 40 000 zapytań wyszukiwania jest wykonywanych w Google w każdej sekundzie. Do 300 godzin wideo jest przesyłanych do YouTube każdej minuty.
W Facebooku, 31,25 mln wiadomości jest wysyłanych przez użytkowników i 2,77 mln filmów jest oglądanych co minutę. Do 2017 r. prawie 80% zdjęć będzie robionych smartfonami.
Do 2020 r. co najmniej jedna trzecia wszystkich danych będzie przechodzić przez chmurę (sieć serwerów połączonych przez Internet). Do roku 2020, około 1,7 megabajtów nowych informacji będzie tworzonych co sekundę dla każdego człowieka na planecie.
Dane rosną szybciej niż kiedykolwiek wcześniej. Do zarządzania tymi stale rosnącymi danymi można użyć większej liczby komputerów. Zamiast jednej maszyny wykonującej zadanie, można użyć wielu maszyn. Nazywa się to systemem rozproszonym.
Możesz sprawdzić kurs Big Data Hadoop i Spark Developer Certification Preview tutaj!
Przyjrzyjrzyjmy się przykładowi, aby zrozumieć, jak działa system rozproszony.
Jak działa system rozproszony?
Załóżmy, że masz jedną maszynę, która ma cztery kanały wejścia/wyjścia. Prędkość każdego kanału wynosi 100 MB/s i chcesz przetworzyć na nim jeden terabajt danych.
Przetworzenie jednego terabajta danych zajmie jednej maszynie 45 minut. Załóżmy teraz, że jeden terabajt danych jest przetwarzany przez 100 maszyn o tej samej konfiguracji.
Przetworzenie jednego terabajta danych zajmie 100 maszynom tylko 45 sekund. Systemy rozproszone potrzebują mniej czasu na przetworzenie Big Data.
Teraz spójrzmy na wyzwania systemu rozproszonego.
Wyzwania systemów rozproszonych
Ponieważ wiele komputerów jest używanych w systemie rozproszonym, istnieją duże szanse na awarię systemu. Istnieje również ograniczenie przepustowości.
Złożoność programistyczna jest również wysoka, ponieważ trudno jest zsynchronizować dane i proces. Hadoop może poradzić sobie z tymi wyzwaniami.
Zrozummy, czym jest Hadoop w następnej sekcji.
Czym jest Hadoop?
Hadoop to framework, który pozwala na rozproszone przetwarzanie dużych zbiorów danych w klastrach komputerów przy użyciu prostych modeli programowania. Jest on inspirowany dokumentem technicznym opublikowanym przez Google.
Słowo Hadoop nie ma żadnego znaczenia. Doug Cutting, który odkrył Hadoop, nazwał go po swoim synu słoniem-zabawką w żółtym kolorze.
Przedyskutujmy, jak Hadoop rozwiązuje trzy wyzwania systemu rozproszonego, takie jak wysokie prawdopodobieństwo awarii systemu, ograniczenie przepustowości i złożoność programowania.
Cztery kluczowe cechy Hadoop to:
-
Ekonomiczny: Jego systemy są bardzo ekonomiczne, ponieważ do przetwarzania danych można używać zwykłych komputerów.
-
Niezawodny: Jest niezawodny, ponieważ przechowuje kopie danych na różnych maszynach i jest odporny na awarie sprzętu.
-
Skalowalny: Jest łatwo skalowalny zarówno w poziomie, jak i w pionie. Kilka dodatkowych węzłów pomaga w skalowaniu frameworka.
-
Elastyczny: Jest elastyczny i możesz przechowywać tyle ustrukturyzowanych i nieustrukturyzowanych danych, ile potrzebujesz, i zdecydować się na ich późniejsze wykorzystanie.
Tradycyjnie dane były przechowywane w centralnej lokalizacji i były wysyłane do procesora w czasie uruchamiania. Ta metoda działała dobrze w przypadku ograniczonych danych.
Nowoczesne systemy otrzymują jednak terabajty danych dziennie, a tradycyjnym komputerom lub systemom zarządzania relacyjnymi bazami danych (RDBMS) trudno jest pchać duże ilości danych do procesora.
Hadoop przyniósł radykalne podejście. W Hadoop program idzie do danych, a nie odwrotnie. Początkowo rozprowadza dane do wielu systemów, a później uruchamia obliczenia wszędzie tam, gdzie znajdują się dane.
W następnej sekcji porozmawiamy o tym, jak Hadoop różni się od tradycyjnego systemu baz danych.
Różnica między tradycyjnym systemem baz danych a Hadoop
Podana poniżej tabela pomoże Ci odróżnić tradycyjny system baz danych od Hadoop.
|
Tradycyjny System Baz Danych |
Hadoop |
|
Dane są przechowywane w centralnej lokalizacji i wysyłane do procesora w czasie uruchamiania. |
W Hadoop program przechodzi do danych. Początkowo dystrybuuje dane do wielu systemów, a później uruchamia obliczenia wszędzie tam, gdzie znajdują się dane. |
|
Tradycyjne systemy baz danych nie mogą być używane do przetwarzania i przechowywania znacznej ilości danych(big data). |
Hadoop działa lepiej, gdy rozmiar danych jest duży. Może przetwarzać i przechowywać dużą ilość danych wydajnie i skutecznie. |
|
Tradycyjny RDBMS jest używany do zarządzania tylko ustrukturyzowanymi i półstrukturalnymi danymi. Nie można go używać do kontrolowania danych nieustrukturyzowanych. |
Hadoop może przetwarzać i przechowywać różnorodne dane, zarówno ustrukturyzowane, jak i nieustrukturyzowane. |
Przedyskutujmy różnicę między tradycyjnym RDBMS a Hadoop za pomocą analogii.
Zauważylibyście różnicę w stylu jedzenia człowieka i tygrysa. Człowiek spożywa jedzenie za pomocą łyżki, gdzie jedzenie jest doprowadzane do ust. Natomiast tygrys zbliża usta w kierunku jedzenia.
Teraz, jeśli jedzenie to dane, a usta to program, styl jedzenia człowieka przedstawia tradycyjny RDBMS, a styl tygrysa przedstawia Hadoop.
Przyjrzyjmy się ekosystemowi Hadoop w następnej sekcji.
Ekosystem Hadoop
Ekosystem Hadoop Hadoop ma ekosystem, który rozwinął się z jego trzech podstawowych komponentów: przetwarzania, zarządzania zasobami i przechowywania. W tym temacie poznasz składniki ekosystemu Hadoop i dowiesz się, w jaki sposób pełnią one swoje role podczas przetwarzania Big Data. Ekosystem
Hadoop stale się rozwija, aby sprostać potrzebom Big Data. Składa się on z następujących dwunastu komponentów:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop. MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
W kolejnych rozdziałach dowiesz się o roli każdego składnika ekosystemu Hadoop.

Zrozummy rolę każdego składnika ekosystemu Hadoop.
Komponenty ekosystemu Hadoop
Zacznijmy od pierwszego komponentu HDFS ekosystemu Hadoop.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS to warstwa pamięci masowej dla Hadoop.
-
HDFS jest odpowiedni do rozproszonego przechowywania i przetwarzania, to znaczy, że podczas przechowywania danych, najpierw są one dystrybuowane, a następnie przetwarzane.
-
HDFS zapewnia strumieniowy dostęp do danych systemu plików.
-
HDFS zapewnia uprawnienia do plików i uwierzytelnianie.
-
HDFS używa interfejsu wiersza poleceń do interakcji z Hadoop.
Więc co przechowuje dane w HDFS? Jest to HBase, który przechowuje dane w HDFS.
HBase
-
HBase jest bazą danych NoSQL lub nierelacyjną bazą danych.
-
HBase jest ważny i głównie używany, gdy potrzebujesz losowego, w czasie rzeczywistym, odczytu lub zapisu dostępu do swoich Big Data.
-
Zapewnia wsparcie dla dużej ilości danych i wysokiej przepustowości.
-
W HBase, tabela może mieć tysiące kolumn.
Przedyskutowaliśmy, jak dane są dystrybuowane i przechowywane. Teraz zrozumiemy, jak te dane są przyjmowane lub przenoszone do HDFS. Sqoop robi dokładnie to.
Czym jest Sqoop?
-
Sqoop jest narzędziem zaprojektowanym do przesyłania danych między Hadoop a serwerami relacyjnych baz danych.
-
Jest używany do importowania danych z relacyjnych baz danych (takich jak Oracle i MySQL) do HDFS i eksportowania danych z HDFS do relacyjnych baz danych.
Jeśli chcesz pobierać dane o zdarzeniach, takie jak dane strumieniowe, dane z czujników lub pliki dziennika, możesz użyć Flume. Przyjrzymy się Flume w następnej sekcji.
Flume
-
Flume jest rozproszoną usługą, która zbiera dane zdarzeń i przekazuje je do HDFS.
-
Idealnie nadaje się do danych zdarzeń z wielu systemów.
Po przekazaniu danych do HDFS są one przetwarzane. Jednym z frameworków przetwarzających dane jest Spark.
Czym jest Spark?
-
Spark jest frameworkiem obliczeniowym typu open source dla klastrów.
-
Zapewnia do 100 razy szybszą wydajność dla kilku aplikacji z prymitywami in-memory w porównaniu do dwustopniowego paradygmatu MapReduce opartego na dysku w Hadoop.
-
Spark może działać w klastrze Hadoop i przetwarzać dane w HDFS.
-
Obsługuje również szeroką gamę obciążeń roboczych, które obejmują Machine learning, Business intelligence, Streaming i Batch processing.
Spark posiada następujące główne komponenty:
-
Spark Core and Resilient Distributed datasets or RDD
-
Spark SQL
-
Spark streaming
-
Machine learning library or Mlib
-
Graphx.
Spark jest obecnie szeroko stosowany, a więcej na jego temat dowiesz się w kolejnych lekcjach.
Hadoop MapReduce
-
Hadoop MapReduce to drugi framework, który przetwarza dane.
-
Jest to oryginalny silnik przetwarzania Hadoop, który jest przede wszystkim oparty na Javie.
-
Opiera się na modelu programowania map and reduces.
-
Wiele narzędzi, takich jak Hive i Pig, jest zbudowanych na modelu map-reduce.
-
Ma rozbudowaną i dojrzałą odporność na błędy wbudowaną w framework.
-
Jest nadal bardzo powszechnie używany, ale traci grunt pod nogami na rzecz Sparka.
Po przetworzeniu danych są one analizowane. Można to zrobić za pomocą open-source’owego, wysokopoziomowego systemu przepływu danych o nazwie Pig. Jest on używany głównie do analityki.
Zrozummy teraz, jak Pig jest używany do analityki.
Pig
-
Pig konwertuje swoje skrypty na kod Map i Reduce, oszczędzając w ten sposób użytkownikowi pisania skomplikowanych programów MapReduce.
-
Kwerendy ad-hoc, takie jak Filter i Join, które są trudne do wykonania w MapReduce, mogą być łatwo wykonane przy użyciu Pig.
-
Można również użyć Impali do analizy danych.
-
Jest to open-source’owy, wysokowydajny silnik SQL, który działa na klastrze Hadoop.
-
Jest idealny do interaktywnej analizy i ma bardzo niską latencję, którą można mierzyć w milisekundach.
Impala
-
Impala obsługuje dialekt SQL, więc dane w HDFS są modelowane jako tabele bazy danych.
-
Analizę danych można również przeprowadzać za pomocą HIVE. Jest to warstwa abstrakcji na wierzchu Hadoop.
-
Jest bardzo podobna do Impali. Jest jednak preferowany do przetwarzania danych i operacji Extract Transform Load, znanych również jako ETL.
-
Impala jest preferowana do zapytań ad-hoc.
HIVE
-
HIVE wykonuje zapytania przy użyciu MapReduce; użytkownik nie musi jednak pisać żadnego kodu w niskopoziomowym MapReduce.
-
Hive jest odpowiedni dla danych ustrukturyzowanych. Po przeanalizowaniu danych są one gotowe do udostępnienia użytkownikom.
Teraz, gdy już wiemy, co robi HIVE, omówimy, co wspiera wyszukiwanie danych. Wyszukiwanie danych odbywa się za pomocą Cloudera Search.
Cloudera Search
-
Search jest jednym z produktów Cloudera zapewniających dostęp do danych w czasie zbliżonym do rzeczywistego. Umożliwia użytkownikom nietechnicznym wyszukiwanie i eksplorację danych przechowywanych lub wprowadzanych do Hadoop i HBase.
-
Użytkownicy nie potrzebują znajomości SQL ani umiejętności programistycznych, aby korzystać z Cloudera Search, ponieważ zapewnia on prosty, pełnotekstowy interfejs do wyszukiwania.
-
Kolejną zaletą Cloudera Search w porównaniu z samodzielnymi rozwiązaniami wyszukiwania jest w pełni zintegrowana platforma przetwarzania danych.
-
Cloudera Search wykorzystuje elastyczny, skalowalny i solidny system pamięci masowej dołączony do CDH lub Cloudera Distribution, w tym Hadoop. Eliminuje to konieczność przenoszenia dużych zbiorów danych między infrastrukturami w celu realizacji zadań biznesowych.
-
Zadania Hadoop, takie jak MapReduce, Pig, Hive i Sqoop mają przepływy pracy.
Oozie
-
Oozie jest systemem przepływu pracy lub koordynacji, którego można użyć do zarządzania zadaniami Hadoop.
Cykl życia aplikacji Oozie jest pokazany na poniższym diagramie.
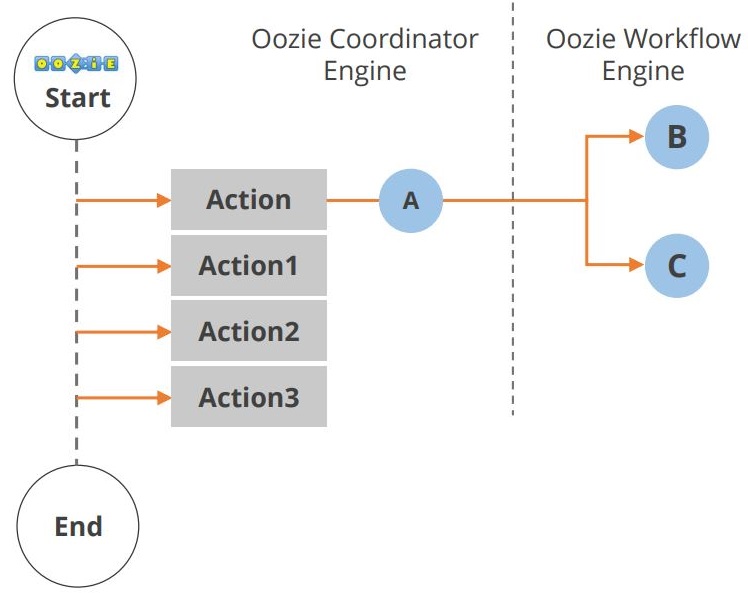 Jak widać, między początkiem a końcem przepływu pracy występuje wiele akcji. Kolejnym komponentem w ekosystemie Hadoop jest Hue. Przyjrzyjmy się teraz Hue.
Jak widać, między początkiem a końcem przepływu pracy występuje wiele akcji. Kolejnym komponentem w ekosystemie Hadoop jest Hue. Przyjrzyjmy się teraz Hue.
Hue
Hue to akronim oznaczający Hadoop User Experience. Jest to interfejs webowy open-source dla Hadoop. Za pomocą interfejsu Hue można wykonywać następujące operacje:
-
Wysyłanie i przeglądanie danych
-
Przetwarzanie tabel w HIVE i Impala
-
Rozpoczynanie zadań Spark i Pig oraz przepływów pracy Wyszukiwanie danych
-
W sumie interfejs Hue ułatwia korzystanie z Hadoop.
-
Dostarcza również edytor SQL dla HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL i Solr SQL.
Po tym krótkim przeglądzie dwunastu komponentów ekosystemu Hadoop omówimy teraz, jak te komponenty współpracują ze sobą w celu przetwarzania Big Data.
Etapy przetwarzania Big Data
Wyróżniamy cztery etapy przetwarzania Big Data: Ingest, Processing, Analyze, Access. Przyjrzyjmy się im szczegółowo.
Ingest
Pierwszym etapem przetwarzania Big Data jest Ingest. Dane są ingestowane lub przekazywane do Hadoop z różnych źródeł, takich jak relacyjne bazy danych, systemy lub pliki lokalne. Sqoop przenosi dane z RDBMS do HDFS, natomiast Flume przenosi dane zdarzeń.
Processing
Drugim etapem jest Processing. Na tym etapie dane są przechowywane i przetwarzane. Dane są przechowywane w rozproszonym systemie plików, HDFS, oraz w rozproszonych danych NoSQL, HBase. Spark i MapReduce wykonują przetwarzanie danych.
Analyze
Trzecim etapem jest Analyze. Tutaj dane są analizowane przez frameworki przetwarzania, takie jak Pig, Hive i Impala.
Pig konwertuje dane za pomocą mapy i redukcji, a następnie analizuje je. Hive jest również oparty na programowaniu map and reduce i jest najbardziej odpowiedni dla danych ustrukturyzowanych.
Access
Czwarty etap to Access, który jest wykonywany przez narzędzia takie jak Hue i Cloudera Search. Na tym etapie analizowane dane mogą być dostępne dla użytkowników.
Hue jest interfejsem webowym, podczas gdy Cloudera Search zapewnia interfejs tekstowy do eksploracji danych.
Sprawdź kurs certyfikacyjny Big Data Hadoop and Spark Developer Certification tutaj!
Podsumowanie
Podsumujmy teraz to, czego nauczyliśmy się w tej lekcji.
-
Hadoop to framework do rozproszonego przechowywania i przetwarzania danych.
-
Rdzeniowe komponenty Hadoop obejmują HDFS do przechowywania danych, YARN do zarządzania zasobami klastra oraz MapReduce lub Spark do przetwarzania.
-
Ekosystem Hadoop obejmuje wiele komponentów, które obsługują każdy etap przetwarzania Big Data.
-
Flume i Sqoop pobierają dane, HDFS i HBase przechowują dane, Spark i MapReduce przetwarzają dane, Pig, Hive i Impala analizują dane, Hue i Cloudera Search pomagają w eksploracji danych.
-
Oozie zarządza przepływem zadań Hadoop.
Wnioski
To kończy lekcję na temat Big Data i ekosystemu Hadoop. W następnej lekcji omówimy HDFS i YARN.
Znajdź nasze zajęcia szkoleniowe Big Data Hadoop i Spark Developer Online Classroom w najlepszych miastach:
| Nazwa | Data | Miejsce | |
|---|---|---|---|
| Big Data Hadoop i Spark Developer | 3 kwietnia -15 maja 2021 r, Weekendowa partia | Twoje miasto | Pokaż szczegóły |
| Big Data Hadoop and Spark Developer | 12 kwietnia -4 maja 2021 r, Weekdays batch | Your City | View Details |
| Big Data Hadoop and Spark Developer | 24 Apr -5 Jun 2021, Weekendowa partia | Twoje miasto | Pokaż szczegóły |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Aby dowiedzieć się więcej, weź udział w Kursie
Big Data Hadoop and Spark Developer Certification Training
Go to Course
Aby dowiedzieć się więcej, skorzystaj z Kursu
Szkolenie certyfikacyjne Big Data Hadoop and Spark Developer Przejdź do Kursu
.