Using Convolutional Neural Networks for Image Recognition
Dit artikel is oorspronkelijk gepubliceerd op de website van Cadence. Het wordt hier herdrukt met toestemming van Cadence.
Convolutionele neurale netwerken (CNNs) worden veel gebruikt bij patroon- en beeldherkenningsproblemen omdat ze een aantal voordelen hebben ten opzichte van andere technieken. Deze white paper behandelt de basisprincipes van CNN’s, inclusief een beschrijving van de verschillende gebruikte lagen. Met verkeersbordherkenning als voorbeeld bespreken we de uitdagingen van het algemene probleem en introduceren we algoritmen en implementatiesoftware ontwikkeld door Cadence die de computationele last en energie kunnen compenseren voor een bescheiden verslechtering van de bordherkenningspercentages. We schetsen de uitdagingen van het gebruik van CNN’s in embedded systemen en introduceren de belangrijkste kenmerken van de Cadence® Tensilica® Vision P5 digitale signaalprocessor (DSP) voor beeldvorming en computervisie en software die het zo geschikt maken voor CNN-toepassingen voor vele beeldvormings- en gerelateerde herkenningstaken.
Wat is een CNN?
Een neuraal netwerk is een systeem van met elkaar verbonden kunstmatige “neuronen” die onderling berichten uitwisselen. De verbindingen hebben numerieke gewichten die tijdens het trainingsproces worden afgesteld, zodat een goed getraind netwerk correct zal reageren wanneer het een beeld of patroon te herkennen krijgt. Het netwerk bestaat uit meerdere lagen van kenmerk-detecterende “neuronen”. Elke laag heeft veel neuronen die reageren op verschillende combinaties van inputs van de vorige lagen. Zoals in figuur 1 te zien is, zijn de lagen zo opgebouwd dat de eerste laag een reeks primitieve patronen in de input detecteert, de tweede laag patronen van patronen detecteert, de derde laag patronen van die patronen detecteert, enzovoort. Typische CNN’s maken gebruik van 5 tot 25 verschillende lagen voor patroonherkenning.
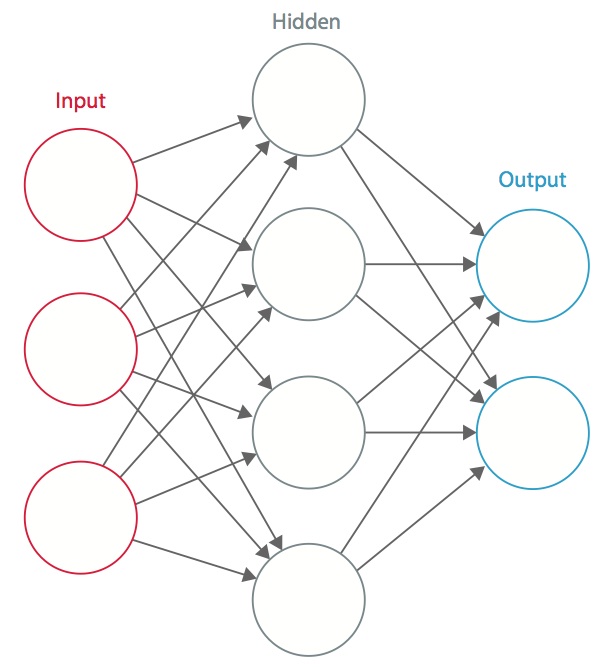
Figuur 1: Een kunstmatig neuraal netwerk
Training wordt uitgevoerd met behulp van een “gelabelde” dataset van inputs in een breed assortiment van representatieve inputpatronen die zijn gelabeld met de beoogde outputrespons. Bij de training worden methoden voor algemene doeleinden gebruikt om de gewichten voor neuronen met tussen- en eindkenmerken iteratief te bepalen. Figuur 2 toont het trainingsproces op blokniveau.
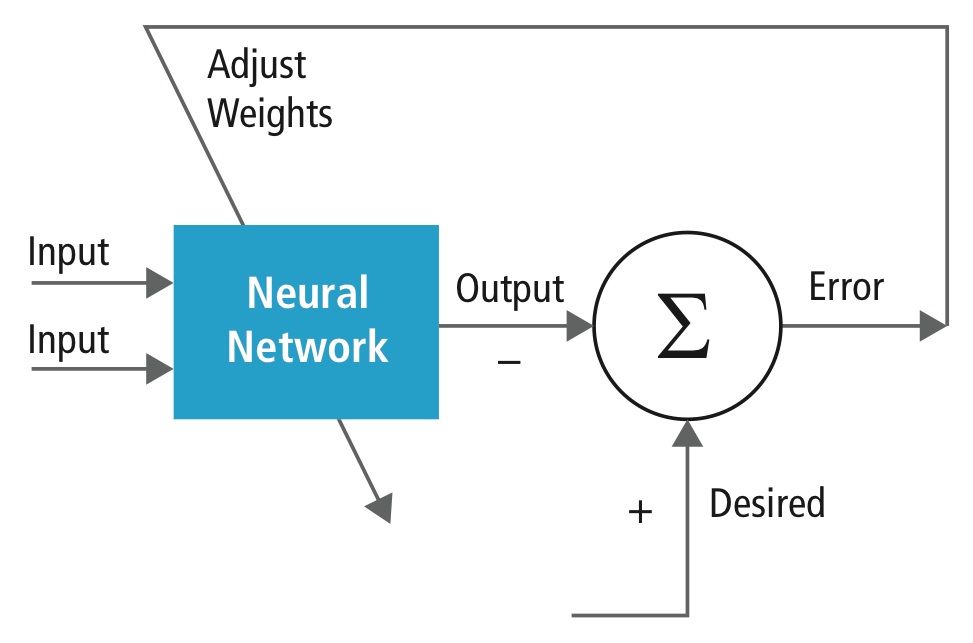
Figuur 2: Training van neurale netwerken
Neurale netwerken zijn geïnspireerd op biologische neurale systemen. De basisrekeneenheid van de hersenen is een neuron en deze zijn met synapsen verbonden. In figuur 3 wordt een biologisch neuron vergeleken met een wiskundig basismodel.


Figuur 3: Illustratie van een biologisch neuron (boven) en zijn wiskundig model (onder)
In een echt dierlijk neuraal systeem ontvangt een neuron ingangssignalen van zijn dendrieten en produceert het uitgangssignalen langs zijn axon. Het axon vertakt zich en verbindt zich via synapsen met dendrieten van andere neuronen. Wanneer de combinatie van ingangssignalen bij zijn ingangsdendrieten een bepaalde drempelwaarde bereikt, wordt het neuron getriggerd en wordt zijn activering doorgegeven aan opvolgende neuronen.
In het rekenmodel van het neurale netwerk werken de signalen die langs de axonen reizen (b.v. x0) vermenigvuldigend (b.v., w0x0) met de dendrieten van het andere neuron op basis van de synaptische sterkte bij die synaps (b.v., w0). Synaptische gewichten zijn leerbaar en bepalen de invloed van het ene neuron of het andere. De dendrieten voeren het signaal naar het cellichaam, waar ze allemaal worden opgeteld. Als de uiteindelijke som boven een bepaalde drempel ligt, gaat het neuron af en zendt een piek langs zijn axon. In het computationele model wordt aangenomen dat de precieze tijdstippen van het vuren er niet toe doen en dat alleen de frequentie van het vuren informatie doorgeeft. Op basis van de rate code interpretatie wordt de vuursnelheid van het neuron gemodelleerd met een activeringsfunctie ƒ die de frequentie van de spikes langs het axon weergeeft. Een gebruikelijke keuze van activeringsfunctie is sigmoïde. Samengevat berekent elk neuron het dot-product van de inputs en de gewichten, voegt het de bias toe, en past niet-lineariteit toe als activeringsfunctie (bijvoorbeeld volgens een sigmoïde responsfunctie).
Een CNN is een speciaal geval van het hierboven beschreven neurale netwerk. Een CNN bestaat uit een of meer convolutionele lagen, vaak met een subsampling-laag, die worden gevolgd door een of meer volledig verbonden lagen zoals in een standaard neuraal netwerk.
Het ontwerp van een CNN is gemotiveerd door de ontdekking van een visueel mechanisme, de visuele cortex, in de hersenen. De visuele cortex bevat een groot aantal cellen die verantwoordelijk zijn voor het detecteren van licht in kleine, overlappende subregio’s van het visuele veld, die receptieve velden worden genoemd. Deze cellen fungeren als lokale filters over de invoerruimte, en de meer complexe cellen hebben grotere receptieve velden. De convolutielaag in een CNN voert de functie uit die wordt uitgevoerd door de cellen in de visuele cortex .
Een typisch CNN voor het herkennen van verkeersborden is afgebeeld in figuur 4. Elk kenmerk van een laag ontvangt input van een set kenmerken die zich in een kleine buurt in de vorige laag bevinden, een lokaal receptief veld genaamd. Met lokale receptieve velden kunnen kenmerken elementaire visuele kenmerken extraheren, zoals georiënteerde randen, eindpunten, hoeken, enzovoort, die vervolgens door de hogere lagen worden gecombineerd.
In het traditionele model van patroon-/beeldherkenning verzamelt een met de hand ontworpen kenmerkextractor relevante informatie uit de invoer en elimineert irrelevante variabelen. De extractor wordt gevolgd door een trainbare classificator, een standaard neuraal netwerk dat feature vectoren in klassen indeelt.
In een CNN spelen convolutielagen de rol van feature extractor. Maar ze zijn niet met de hand ontworpen. De kerngewichten van de convolutiefilter worden tijdens het trainingsproces bepaald. Convolutionele lagen zijn in staat lokale kenmerken te extraheren omdat zij de receptieve velden van de verborgen lagen beperken tot lokaal.
Figuur 4: Typisch blokschema van een CNN
CNN’s worden gebruikt op uiteenlopende gebieden, waaronder beeld- en patroonherkenning, spraakherkenning, natuurlijke taalverwerking en videoanalyse. Er zijn een aantal redenen waarom convolutionele neurale netwerken belangrijk worden. In traditionele modellen voor patroonherkenning worden de kenmerk-extractoren met de hand ontworpen. In CNN’s worden de gewichten van zowel de convolutionele laag die voor de feature-extractie wordt gebruikt als de volledig aangesloten laag die voor de classificatie wordt gebruikt, tijdens het trainingsproces bepaald. De verbeterde netwerkstructuren van CNN’s leiden tot besparingen in geheugenvereisten en rekencomplexiteitsvereisten en leveren tegelijkertijd betere prestaties voor toepassingen waarbij de invoer lokale correlatie heeft (bijv. beeld en spraak).
In grote behoeften aan rekenhulpbronnen voor het trainen en evalueren van CNN’s wordt soms voorzien door grafische verwerkingseenheden (GPU’s), DSP’s of andere siliciumarchitecturen die zijn geoptimaliseerd voor hoge verwerkingscapaciteit en lage energie bij het uitvoeren van de idiosyncratische patronen van CNN-rekeningen. Geavanceerde processoren zoals de Tensilica Vision P5 DSP for Imaging and Computer Vision van Cadence beschikken over een vrijwel ideale set van reken- en geheugenbronnen die nodig zijn om CNN’s met hoge efficiëntie uit te voeren.
In patroon- en beeldherkenningstoepassingen zijn de best mogelijke correcte detectiepercentages (CDR’s) bereikt met CNN’s. CNN’s hebben bijvoorbeeld een CDR van 99,77% bereikt met de MNIST-database van handgeschreven cijfers, een CDR van 97,47% met de NORB-dataset van 3D-objecten, en een CDR van 97,6% op ~5600 afbeeldingen van meer dan 10 objecten. CNN’s geven niet alleen de beste prestaties in vergelijking met andere detectie-algoritmen, ze presteren zelfs beter dan mensen in gevallen zoals het classificeren van objecten in fijnkorrelige categorieën, zoals het specifieke ras van de hond of soort vogel. Figuur 5 toont een typische visie algoritme pijplijn, die bestaat uit vier stadia: pre-processing het beeld, het detecteren van regio’s van belang (ROI) die waarschijnlijke objecten bevatten, objectherkenning, en visie besluitvorming. De voorbewerkingsstap is gewoonlijk afhankelijk van de details van de invoer, met name het camerasysteem, en wordt vaak uitgevoerd in een hardwired eenheid buiten het vision-subsysteem. De besluitvorming aan het einde van de pijplijn werkt gewoonlijk op herkende objecten – het kan complexe beslissingen nemen, maar het werkt op veel minder gegevens, zodat deze beslissingen gewoonlijk geen rekenkundig moeilijke of geheugenintensieve problemen zijn. De grote uitdaging ligt in de fasen van objectdetectie en -herkenning, waar CNN’s nu een grote impact hebben.

Figuur 5: Vision algorithm pipeline
Lagen van CNN’s
Door meerdere en verschillende lagen in een CNN te stapelen, worden complexe architecturen gebouwd voor classificatieproblemen. Vier typen lagen komen het meest voor: convolutielagen, pooling/subsampling-lagen, niet-lineaire lagen, en volledig aangesloten lagen.
Convolutielagen
De convolutiebewerking extraheert verschillende kenmerken van de invoer. De eerste convolutielaag extraheert kenmerken op laag niveau, zoals randen, lijnen en hoeken. Lagen op een hoger niveau extraheren kenmerken op een hoger niveau. Figuur 6 illustreert het proces van 3D-convolutie dat in CNN’s wordt gebruikt. De invoer heeft een grootte van N x N x D en wordt geconvolueerd met H kernels, elk met de grootte k x k x D afzonderlijk. Convolutie van een ingang met één kernel levert één uitgangskenmerk op, en convolutie met H kernels levert onafhankelijk H kenmerken op. Beginnend in de linkerbovenhoek van de invoer, wordt elke kernel van links naar rechts verplaatst, één element per keer. Zodra de rechterbovenhoek is bereikt, wordt de kernel één element naar beneden verplaatst, en opnieuw wordt de kernel van links naar rechts verplaatst, één element per keer. Dit proces wordt herhaald tot
de kernel de hoek rechtsonder bereikt. Voor het geval dat N = 32 en k = 5 zijn er 28 unieke posities van links naar rechts en 28 unieke posities van boven naar onder die de kernel kan innemen. Overeenkomstig deze posities zal elk kenmerk in de uitvoer 28×28 (d.w.z. (N-k+1) x (N-k+1)) elementen bevatten. Voor elke positie van de kernel in een schuifvensterproces worden k x k x D elementen van de input en k x k x D elementen van de kernel element-voor-element vermenigvuldigd en gecumuleerd. Dus om één element van één uitgangskenmerk te creëren, zijn k x k x D vermenigvuldigings-accumulatieoperaties nodig.
Figuur 6: Picturale voorstelling van het convolutieproces
Pooling/subsampling-lagen
De pooling/subsampling-laag verlaagt de resolutie van de kenmerken. Het maakt de kenmerken robuust tegen ruis en vervorming. Er zijn twee manieren om te poolen: max pooling en average pooling. In beide gevallen wordt de invoer verdeeld in niet-overlappende tweedimensionale ruimten. Bijvoorbeeld, in figuur 4 is laag 2 de poolinglaag. Elk ingangskenmerk is 28×28 en is verdeeld in 14×14 gebieden van 2×2. Voor average pooling wordt het gemiddelde van de vier waarden in de regio berekend. Voor max pooling wordt de maximale waarde van de vier waarden geselecteerd.
Figuur 7 werkt het poolingproces verder uit. De invoer is 4×4 groot. Bij 2×2 subsampling wordt een beeld van 4×4 verdeeld in vier niet-overlappende matrices van 2×2. In het geval van max pooling is de maximumwaarde van de vier waarden in de 2×2 matrix de uitvoer. In het geval van average pooling is het gemiddelde van de vier waarden de uitvoer. Merk op dat voor de uitvoer met index (2,2) het resultaat van de middeling een breuk is die is afgerond tot op het dichtstbijzijnde gehele getal.
Figuur 7: Illustratie van max pooling en average pooling
Niet-lineaire lagen
Neurale netwerken in het algemeen en CNN’s in het bijzonder berusten op een niet-lineaire “trigger”-functie voor het signaleren van afzonderlijke identificaties van waarschijnlijke kenmerken in elke verborgen laag. CNN’s kunnen gebruik maken van een verscheidenheid aan specifieke functies – zoals gerectificeerde lineaire eenheden (ReLU’s) en continue triggerfuncties (niet-lineair) – om deze niet-lineaire triggering efficiënt te implementeren.
ReLU
Een ReLU implementeert de functie y = max(x,0), zodat de input- en outputgrootte van deze laag gelijk zijn. Het verhoogt de niet-lineaire eigenschappen van de beslissingsfunctie en van het totale netwerk, zonder de receptieve velden van de convolutielaag aan te tasten. In vergelijking met de andere niet-lineaire functies die in CNN’s worden gebruikt (bv. hyperbolische tangens, absolute van hyperbolische tangens, en sigmoïde), is het voordeel van een ReLU dat het netwerk vele malen sneller traint. De ReLU-functionaliteit wordt geïllustreerd in figuur 8, met de overdrachtsfunctie uitgezet boven de pijl.
Figuur 8: Illustratieve weergave van de ReLU-functionaliteit
Continue trigger (niet-lineaire) functie
De niet-lineaire laag werkt element voor element in elk kenmerk. Een continue triggerfunctie kan hyperbolische tangens (afbeelding 9), absolute van hyperbolische tangens (afbeelding 10), of sigmoïde (afbeelding 11) zijn. Figuur 12 laat zien hoe niet-lineariteit element voor element wordt toegepast.
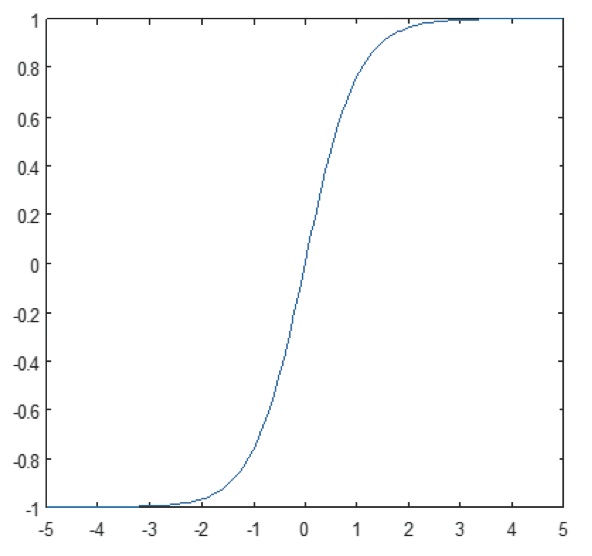
Figuur 9: Plot van hyperbolische tangensfunctie
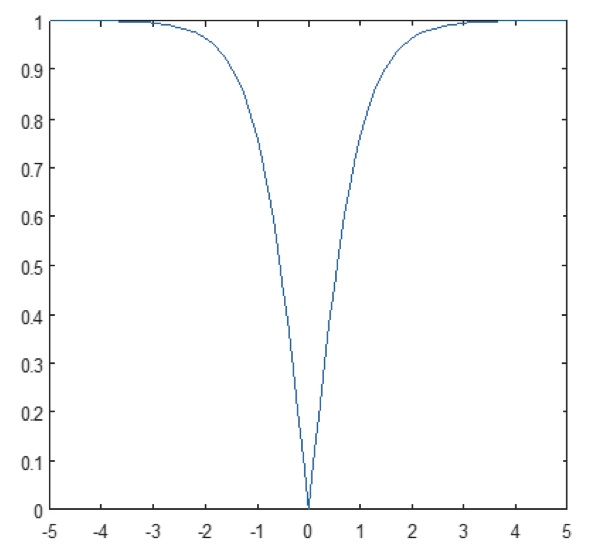
Figuur 10: Plot van absolute van hyperbolische tangensfunctie
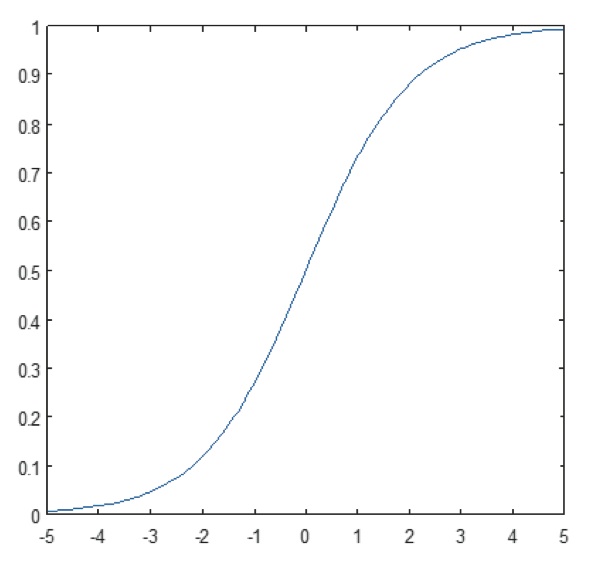
Figuur 11: Plot van sigmoid functie
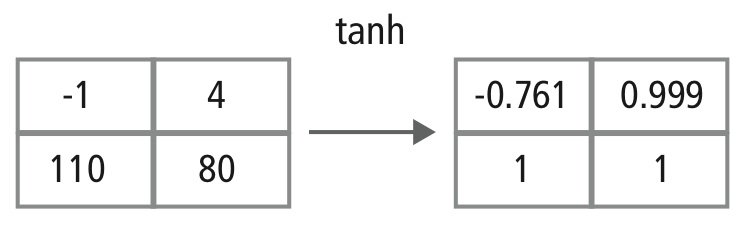
Figuur 12: Picturale voorstelling van tanh verwerking
Volledig verbonden lagen
Volledig verbonden lagen worden vaak gebruikt als de laatste lagen van een CNN. Deze lagen sommeren wiskundig een weging van de vorige laag kenmerken, en geven zo de precieze mix van “ingrediënten” aan om een specifiek beoogd uitvoerresultaat te bepalen. In het geval van een volledig aangesloten laag worden alle elementen van alle features van de vorige laag gebruikt bij de berekening van elk element van elk outputkenmerk.
Figuur 13 legt de volledig aangesloten laag L uit. Laag L-1 heeft twee features, die elk 2×2 zijn, d.w.z. vier elementen hebben. Laag L heeft twee features, elk met één element.
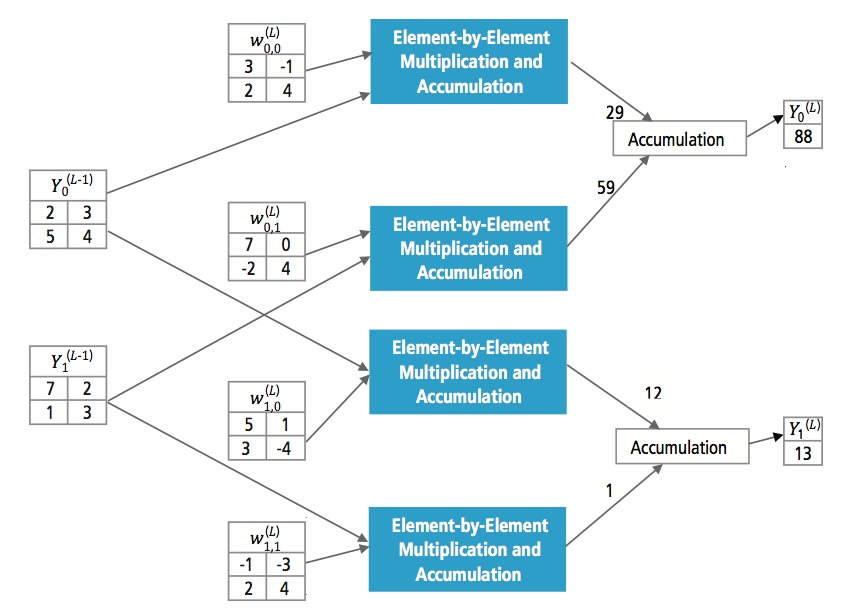
Figuur 13: Verwerking van een volledig aangesloten laag
Waarom CNN?
Terwijl neurale netwerken en andere methoden voor patroonherkenning al 50 jaar bestaan, heeft zich in het recente verleden een belangrijke ontwikkeling voorgedaan op het gebied van convolutionele neurale netwerken. Dit hoofdstuk behandelt de voordelen van het gebruik van CNN voor beeldherkenning.
Ruwheid tegen verschuivingen en vervorming in het beeld
Detectie met CNN is robuust tegen vervormingen zoals verandering in vorm door cameralens, verschillende lichtomstandigheden, verschillende poses, aanwezigheid van gedeeltelijke occlusies, horizontale en verticale verschuivingen, enz. CNN’s zijn echter verschuivingsinvariant omdat dezelfde gewichtsconfiguratie in de ruimte wordt gebruikt. In theorie kunnen we verschuivingsinvariantie ook bereiken met volledig aangesloten lagen. Maar het resultaat van de training is in dit geval meerdere eenheden met identieke gewichtspatronen op verschillende plaatsen van de invoer. Om deze gewichtsconfiguraties te leren, zou een groot aantal trainingsinstanties nodig zijn om de ruimte van mogelijke variaties te bestrijken.
Minder geheugen nodig
In ditzelfde hypothetische geval waarin we een volledig aangesloten laag gebruiken om de kenmerken te extraheren, zal het invoerbeeld van 32×32 en een verborgen laag met 1000 kenmerken een orde van 106 coëfficiënten vereisen, een enorm geheugenvereiste. In de convolutionele laag worden dezelfde coëfficiënten op verschillende plaatsen in de ruimte gebruikt, zodat het geheugengebruik drastisch afneemt.
Makkelijker en beter te trainen
Wanneer we het standaard neurale netwerk gebruiken dat gelijkwaardig zou zijn aan een CNN, zou, omdat het aantal parameters veel groter is, de trainingstijd ook evenredig toenemen. In een CNN is het aantal parameters drastisch verminderd, zodat de trainingstijd evenredig korter wordt. Ook kunnen we, uitgaande van een perfecte training, een standaard neuraal netwerk ontwerpen waarvan de prestaties gelijk zouden zijn aan die van een CNN. Maar bij praktische training zou een standaard neuraal netwerk dat gelijkwaardig is aan een CNN meer parameters hebben, waardoor tijdens het trainingsproces meer ruis zou worden toegevoegd. Vandaar dat de prestaties van een standaard neuraal netwerk dat equivalent is aan een CNN altijd slechter zullen zijn.
Herkenningsalgoritme voor GTSRB Dataset
De German Traffic Sign Recognition Benchmark (GTSRB) was een multi-class, single-image classificatie uitdaging gehouden op de International Joint Conference on Neural Networks (IJCNN) 2011, met de volgende eisen:
- 51.840 afbeeldingen van Duitse verkeersborden in 43 klassen (figuren 14 en 15)
- Grootte van afbeeldingen varieert van 15×15 tot 222×193
- Beelden zijn gegroepeerd per klasse en spoor met ten minste 30 afbeeldingen per spoor
- Beelden zijn beschikbaar als kleurenafbeeldingen (RGB), HOG-kenmerken, Haar-kenmerken, en kleurenhistogrammen
- Competitie is alleen voor het classificatiealgoritme; algoritme om interessegebied in het frame te vinden is niet nodig
- Temporele informatie van de testsequenties wordt niet gedeeld, zodat de temporele dimensie niet in het classificatiealgoritme kan worden gebruikt

Figuur 14: GTSRB ideale verkeersborden

Figuur 15: GTSRB verkeersborden met beperkingen
Cadence Algoritme voor verkeersbordherkenning in GTSRB Dataset
Cadence heeft verschillende algoritmen ontwikkeld in MATLAB voor verkeersbordherkenning met behulp van de GTSRB dataset, te beginnen met een basisconfiguratie gebaseerd op een bekend artikel over bordherkenning . Het correcte detectiepercentage van 99,24% en de rekeninspanning van bijna >50 miljoen multiply-adds per bord is weergegeven als een dikke groene punt in Figuur 16. Cadence heeft aanzienlijk betere resultaten bereikt met onze nieuwe gepatenteerde hiërarchische CNN-benadering. In dit algoritme zijn 43 verkeersborden onderverdeeld in vijf families. In totaal implementeren we zes kleinere CNN’s. De eerste CNN bepaalt tot welke familie het ontvangen verkeersbord behoort. Zodra de familie van het bord bekend is, wordt de CNN (een van de overige vijf) die overeenkomt met de gedetecteerde familie, uitgevoerd om het verkeersbord binnen die familie te bepalen. Met behulp van dit algoritme heeft Cadence een correcte detectiegraad van 99,58% bereikt, de beste CDR die tot nu toe op GTSRB is bereikt.
Algoritme voor afweging tussen prestaties en complexiteit
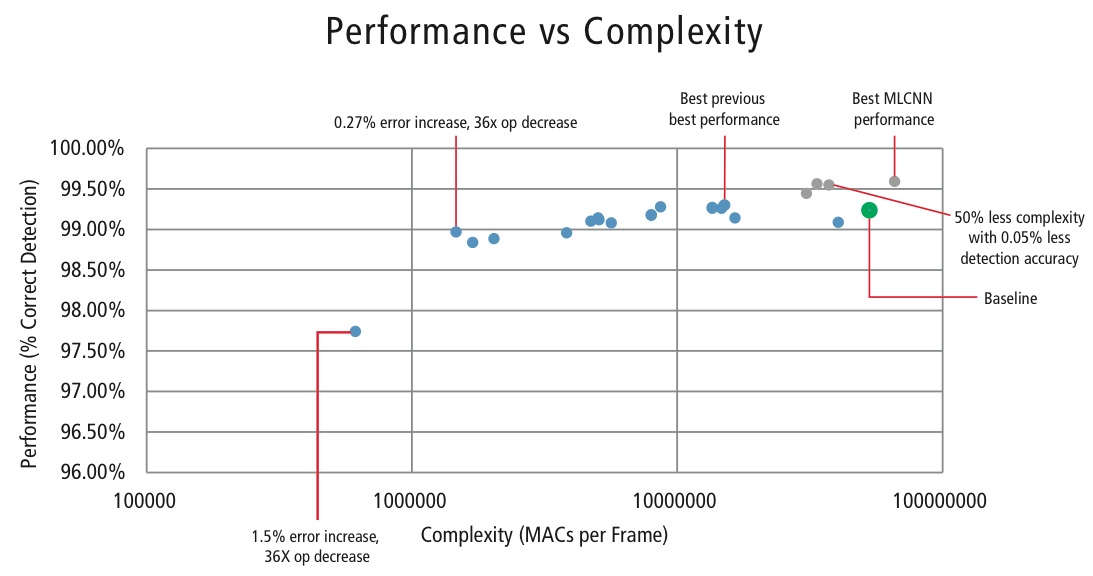
Om de complexiteit van CNN’s in embedded toepassingen te beheersen, heeft Cadence ook een eigen algoritme ontwikkeld dat gebruik maakt van eigenwaarde-decompositie en dat een getrainde CNN terugbrengt tot zijn canonieke dimensie. Met behulp van dit algoritme zijn we in staat geweest de complexiteit van de CNN drastisch te verminderen zonder enige prestatievermindering, of met een kleine gecontroleerde CDR vermindering. Figuur 16 toont de bereikte resultaten:
Figuur 16: Performance vs. complexity plot voor verschillende CNN-configuraties voor het detecteren van verkeersborden in de GTSRB-dataset
De groene punt in figuur 16 is de baseline-configuratie. Deze configuratie ligt vrij dicht bij de configuratie voorgesteld in Reference . Er zijn 53 MMAC’s per frame nodig voor een foutenpercentage van 0,76%.
- Het tweede punt van links vereist 1,47 miljoen MAC’s per frame voor een foutenpercentage van 1,03%, d.w.z, voor een toename van de foutenmarge met 0,27% is het aantal MAC’s met een factor 36,14 verminderd.
- Het meest linkse punt vereist 0,61 MMAC’s per frame voor het bereiken van een foutenmarge van 2,26%, d.w.z. het aantal MAC’s is met een factor 86,4 verminderd.
- De punten in blauw zijn voor een CNN met één niveau, terwijl de punten in rood zijn voor een hiërarchisch CNN. Een best-case prestatie van 99,58% wordt bereikt door de hiërarchische CNN.
CNNs in Embedded Systems
Zoals in figuur 5 is te zien, vereist een vision-subsysteem naast een CNN nog veel meer beeldverwerking. Om CNN’s te kunnen gebruiken op een embedded systeem met beperkte stroomtoevoer dat beeldverwerking ondersteunt, moet het aan de volgende eisen voldoen:
- Beschikbaarheid van hoge rekenprestaties: Voor een typische CNN-implementatie zijn miljarden MAC’s per seconde vereist.
- Grote laad-/opslagbandbreedte: In het geval van een volledig aangesloten laag die wordt gebruikt voor classificatiedoeleinden, wordt elke coëfficiënt slechts eenmaal gebruikt bij de vermenigvuldiging. Dus is de vereiste load-store bandbreedte groter dan het aantal MAC’s dat door de processor wordt uitgevoerd.
- Lage dynamische vermogensbehoefte: Het systeem moet minder stroom verbruiken. Om dit probleem aan te pakken is een fixed-point-implementatie vereist, die de eis oplegt dat aan de prestatie-eisen moet worden voldaan met gebruikmaking van het kleinst mogelijke eindige aantal bits.
- Flexibiliteit: Het moet mogelijk zijn om het bestaande ontwerp gemakkelijk te upgraden naar een nieuw ontwerp met betere prestaties.
Omdat computationele middelen altijd een beperking zijn in ingebedde systemen, als de use case een kleine degradatie in de prestaties toelaat, is het nuttig om een algoritme te hebben dat enorme besparingen in computationele complexiteit kan bereiken ten koste van een gecontroleerde kleine degradatie in de prestaties. Het werk van Cadence aan een algoritme om complexiteit versus een performance tradeoff te bereiken, zoals uitgelegd in de vorige sectie, is dus van groot belang voor het implementeren van CNNs op embedded systemen.
CNNs on Tensilica Processors
De Tensilica Vision P5 DSP is een krachtige, laag-vermogen DSP die speciaal is ontworpen voor beeld- en computervisieverwerking. De DSP heeft een VLIW architectuur met SIMD ondersteuning. Hij heeft vijf uitgifteslots in een instructiewoord van maximaal 96 bits en kan elke cyclus tot 1024-bits woorden uit het geheugen laden. De interne registers en bewerkingseenheden variëren van 512 bits tot 1536 bits, waarbij de gegevens worden weergegeven als 16, 32 of 64 segmenten van 8b, 16b, 24b, 32b of 48b pixeldata.
De DSP gaat alle uitdagingen aan voor de implementatie van CNN’s in embedded systemen, zoals besproken in de vorige sectie.
- Beschikbaarheid van hoge rekenprestaties: Naast de geavanceerde ondersteuning voor het implementeren van beeldsignaalverwerking, heeft de DSP instructie-ondersteuning voor alle stadia van CNN’s. Voor convolutiebewerkingen beschikt hij over een zeer rijke instructieset die multiply/multiply-accumulate-bewerkingen ondersteunt met 8b x 8b, 8b x 16b en 16b x 16b bewerkingen voor signed/unsigned data. Hij kan tot 64 8b x 16b en 8b x 8b multiply/multiply-accumulate-bewerkingen in één cyclus uitvoeren en 32 16b x 16b multiply/multiply-accumulate-bewerkingen in één cyclus. Voor max pooling en ReLU-functionaliteit heeft de DSP instructies om 64 8-bit vergelijkingen in één cyclus uit te voeren. Voor het implementeren van niet-lineaire functies met eindige bereiken, zoals tanh en signum, heeft hij instructies om een opzoektabel te implementeren voor 64 7-bits waarden in één cyclus. In de meeste gevallen worden de instructies voor de vergelijking en de naslagtabel parallel aan de vermenigvuldigings- en vermenigvuldigingsaccumulatie-instructies gepland en nemen ze geen extra cycli in beslag.
- Grote laad-/opslagbandbreedte: de DSP kan tot twee 512-bit laad-/opslagbewerkingen per cyclus uitvoeren.
- Laag dynamisch stroomverbruik: De DSP is een fixed-point machine. Dankzij de flexibele verwerking van een verscheidenheid aan datatypes kan het volledige prestatie- en energievoordeel van gemengde 16b- en 8b-rekeningen worden bereikt met minimaal verlies van nauwkeurigheid.
- Flexibiliteit: Aangezien de DSP een programmeerbare processor is, kan het systeem worden opgewaardeerd naar een nieuwe versie door alleen maar een firmware-upgrade uit te voeren.
- Floating Point: Voor algoritmen die een groter dynamisch bereik voor hun data en/of coëfficiënten vereisen, beschikt de DSP over een optionele vector floating-point unit.
De Vision P5 DSP wordt geleverd met een complete set softwaretools, waaronder een krachtige C/C++ compiler met automatische vectorisatie en scheduling ter ondersteuning van de SIMD- en VLIW-architectuur zonder dat assembly-taal hoeft te worden geschreven. Deze uitgebreide toolset omvat ook de linker, assembler, debugger, profiler, en grafische visualisatie tools. Een uitgebreide instructieset simulator (ISS) stelt de ontwerper in staat om snel prestaties te simuleren en te evalueren. Bij het werken met grote systemen of lange test vectoren, bereikt de snelle, functionele TurboXim simulator optie snelheden die 40X tot 80X sneller zijn dan de ISS voor efficiënte software ontwikkeling en functionele verificatie.
Cadence heeft een enkellaags architectuur CNN op de DSP geïmplementeerd voor Duitse verkeersbordherkenning. Cadence heeft voor deze architectuur een CDR van 99,403% bereikt met 16-bit kwantisatie voor datasamples en 8-bit kwantisatie voor coëfficiënten in alle lagen. Het heeft twee convolutielagen, drie volledig aangesloten lagen, vier ReLU-lagen, drie max pooling lagen, en een tanh niet-lineaire laag. Cadence heeft een gemiddelde prestatie van 38,58 MAC’s/cyclus bereikt voor het volledige netwerk inclusief de cycli voor alle max pooling, tanh, en ReLU lagen. Cadence heeft een best-case prestatie van 58,43 MAC’s per cyclus bereikt voor de derde laag, inclusief de cycli voor tanh en ReLU functionaliteiten. Deze op 600 MHz draaiende DSP kan meer dan 850 verkeersborden in één seconde verwerken.
De toekomst van CNN’s
Tot de veelbelovende gebieden van neurale netwerken-onderzoek behoren recurrente neurale netwerken (RNN’s) die gebruik maken van lange-korte-termijn geheugen (LSTM). Deze gebieden leveren de huidige stand van de techniek in time-series herkenningstaken zoals spraakherkenning en handschriftherkenning. RNN/autoencoders zijn ook in staat om handschrift/spraak/beelden te genereren met een bekende verdeling ,,,,.
Deep belief networks, een ander veelbelovend type netwerk dat gebruik maakt van restricted Boltzman machines (RMBs)/autoencoders, zijn in staat om gulzig getraind te worden, één laag per keer, en zijn dus gemakkelijker trainbaar voor zeer diepe netwerken ,.
Conclusie
CNNs geven de beste prestaties in patroon/beeldherkenningsproblemen en presteren in bepaalde gevallen zelfs beter dan mensen. Cadence heeft de beste resultaten in de industrie bereikt door gebruik te maken van eigen algoritmen en architecturen met CNN’s. We hebben hiërarchische CNN’s ontwikkeld voor het herkennen van verkeersborden in de GTSRB, waarbij we de beste prestaties ooit hebben behaald op deze dataset. We hebben een ander algoritme ontwikkeld voor de afweging tussen prestaties en complexiteit en zijn erin geslaagd de complexiteit met een factor 86 te verminderen bij een CDR-verlies van minder dan 2%. De Tensilica Vision P5 DSP voor beeldvorming en computervisie van Cadence beschikt over alle functies die nodig zijn om CNN’s te implementeren, naast de functies die nodig zijn om beeldsignaalverwerking te doen. Meer dan 850 verkeersbordherkenningen kunnen worden uitgevoerd met de DSP op 600MHz. De Tensilica Vision P5 DSP van Cadence heeft een bijna ideale set eigenschappen om CNN’s uit te voeren.
“Kunstmatig neuraal netwerk.” Wikipedia. https://en.wikipedia.org/wiki/Artificial_neural_network
Karpathy, Andrej. 2015. “Neurale Netwerken Deel 1: Het opzetten van de architectuur.” Aantekeningen voor CS231n Convolutional Neural Networks for Visual Recognition, Stanford University. http://cs231n.github.io/neural-networks-1/
“Convolutioneel neuraal netwerk.” Wikipedia. https://en.wikipedia.org/wiki/Convolutional_neural_network
Sermanet, Pierre, and Yann LeCun. 2011. “Traffic Sign Recognition with Multi Scale Networks.” Courant Institute of Mathematical Sciences, New York University. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6033589
Ciresan, Dan, Ueli Meier, and Jürgen Schmidhuber. 2012. “Meer-koloms diepe neurale netwerken voor beeldclassificatie.” 2012 IEEE Conference on Computer Vision and Pattern Recognition (New York, NY: Institute of Electrical and Electronics Engineers (IEEE)). http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6248110
Ciresan, Dan, Ueli Meier, Jonathan Masci, Luca M. Gambardella, and Jurgen Schmidhuber. 2011. “Flexibele, hoogperformante Convolutionele Neurale Netwerken voor Beeldclassificatie. Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence-Volume Two: 1237-1242. Op 17 november 2013 ontleend. http://people.idsia.ch/~juergen/ijcai2011.pdf
Lawrence, Steve, C. Lee Giles, Ah Chung Tsoi, and Andrew D. Back. 1997. “Gezichtsherkenning: A Convolutional Neural Network Approach.” IEEE Transactions on Neural Networks, Volume 8; Issue 1. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=554195
Russakovsky, O. et al. 2014. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision. http://link.springer.com/article/10.1007/s11263-015-0816-y#
Ovtcharov, Kalin, Olatunji Ruwarse, Joo-Young Kim et al. Feb 22, 2015. “Versnellen van Diepe Convolutionele Netwerken met behulp van Gespecialiseerde Hardware.” Microsoft Research. http://research-srv.microsoft.com/pubs/240715/CNN%20Whitepaper.pdf
Stallkamp, J., M. Schlipsing, J. Salmen, en C. Igel. “Man vs. computer: Benchmarking Machine Learning Algorithms For Traffic Sign Application.” IJCNN 2011. http://www.sciencedirect.com/science/article/pii/S0893608012000457
Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. “Long Short-Term Memory.” Neural Computation, 9(8):1735-1780. ftp://ftp.idsia.ch/pub/juergen/lstm.pdf
Graves, Alex. 2014. “Generating Sequences With Recurrent Neural Networks.” http://arxiv.org/abs/1308.0850
Schmidhuber, Jurgen. 2015. “Recurrent Neural Networks.” http://people.idsia.ch/~juergen/rnn.html
Olshausen, Bruno A., and David J. Field. 1996. “Emergence of simple-cell receptive field properties by learning a sparse code for natural images.” Nature 381.6583: 607-609. http://www.nature.com/nature/journal/v381/n6583/abs/381607a0.html
Hinton, G. E. and Salakhutdinov, R. R. 2006. “Vermindering van de dimensionaliteit van gegevens met neurale netwerken. Science vol. 313 no. 5786 pp. 504-507. http://www.sciencemag.org/content/suppl/2006/08/04/313.5786.504.DC1.
Hinton, Geoffrey E. 2009. “Deep belief networks.” Scholarpedia, 4(5):5947.
http://www.scholarpedia.org/article/Deep_belief_networks