Reddit AmItheAsshole is aardiger voor vrouwen dan voor mannen – een SQL bewijs?
Wanneer redditors vragen “ben ik de klootzak” terwijl ze het over vrouwen hebben, hebben ze een grotere kans om als de klootzak te worden beoordeeld. Laten we eens kijken naar deze statistieken – met BigQuery, dbt, en Data Studio
Neem niet alles wat ik hier heb geschreven als de absolute waarheid. Verschillende mensen op Twitter hebben problemen opgemerkt en correcties toegevoegd aan de analyse die ik heb aangeboden. Het lezen van dit bericht zoals oorspronkelijk gepresenteerd – en de reacties – kan een geweldige manier voor u zijn om net zo veel te leren als ik deed bij het lezen van de reacties. U kunt veel van hun ongefilterde gedachten vinden door deze Twitter thread te volgen.
Context
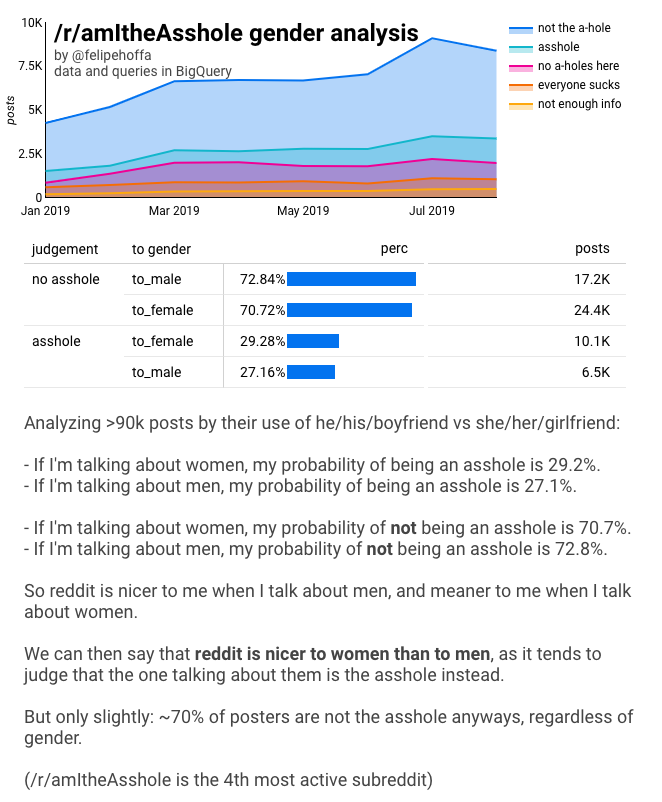
/r/amItheAsshole is uitgegroeid tot de 4e meest actieve subreddit – door het aantal reacties. Mensen komen naar deze subreddit om hun verhalen te vertellen, en ze vragen andere redditors “ben ik de klootzak hier?”. Blijkt dat de meeste mensen worden beoordeeld als “niet de lul”, zoals te zien in deze grafiek:
Mijn tweet met deze resultaten kreeg veel aandacht:
Inclusief de vraag – is reddit aardiger voor vrouwen of voor mannen?
Geslacht bepalen
Als je naar de titel of inhoud van een bericht kijkt, is het misschien moeilijk om te bepalen of “ik” een man of een vrouw ben – maar het is vrij eenvoudig om het aantal “zij/hij/zijn/vriendin/vriendin” te tellen dat in het verhaal voorkomt.
Laten we eens kijken naar wat willekeurige berichten, en de telling voor elk van deze voornaamwoorden en geslachtswoorden:

We kunnen zien dat het aantal geslachtsuitgesproken voornaamwoorden en woorden in het voorbeeld overeenkomt met waar het verhaal over gaat. Deze verhalen gaan over een mannelijke klant, een vrouwelijke vriendin, een mannelijke buurman, een mannelijke zoon en een vrouwelijke tienerdochter.
Met deze getallen kunnen we nu een arbitraire regel instellen: als er meer dan het dubbele aantal mannelijke voornaamwoorden is dan vrouwelijke, dan gaat dat bericht over een man. We kunnen de tegenovergestelde regel gebruiken om te zeggen dat de post over een vrouw gaat. Als de aantallen te dicht bij elkaar liggen of nihil zijn, noemen we de post “neutraal”.
Een andere regel die we kunnen instellen om de analyse te vereenvoudigen:
- Als het oordeel is ‘niet de a-gat’ of ‘geen a-gaten hier’ dan kunnen we zeggen ‘de poster is geen a-gat’.
- Als het oordeel is ‘klootzak’ of ‘iedereen zuigt’ dan kunnen we zeggen ‘de poster is een klootzak’.
Als we al deze posts samenvoegen, komen we op de getallen:

Toen ik deze resultaten voor het eerst presenteerde, kreeg ik te horen “deze cijfers liggen te dicht bij elkaar, het zou een statistische fout kunnen zijn”.
Statistische significantie?
Hoe kunnen we zien dat de cijfers niet slechts een statistische fout zijn? Laten we de trend maand na maand bekijken – is die stabiel?

Ja! De trend verschilt van maand tot maand, maar er is een duidelijk hogere kans om een klootzak te zijn wanneer het over vrouwen gaat dan wanneer het over mannen gaat. Als het kleine verschil slechts een statistische toevalstreffer was, zouden we verwachten dat de trend in plaats daarvan wild zou verspringen.
En let op: deze resultaten zijn zeer specifiek, zoals deze tweet opmerkt:
Waarop ik antwoordde
How-to
Deze keer gebruik ik dbt voor de eerste keer, en ik heb al mijn code op GitHub achtergelaten. Bedankt Claire Carroll voor je hulp om met deze geweldige tool aan de slag te gaan!
Om alle /r/AmItheAsshole-posts in BigQuery naar een nieuwe tabel te extraheren, kunt u doen:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Dan kan het geslacht en de beoordeling voor elke post worden bepaald met een query als:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
En ten slotte de statistieken die hier worden gepresenteerd:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Discussie
U vindt veel inzichtelijke en onderhoudende antwoorden op de twitter thread voor dit bericht:
Voel je vrij om deel te nemen aan de discussie (en vertel me als ik het mis heb?). Vergeet niet om aardig tegen elkaar te zijn – de meeste mensen zijn toch niet de lul.
Wil je meer?
Ik heb alleen gedekt tot augustus 2019 omdat dat is wanneer het huidige volledige reddit-archief in BigQuery stopt – tot toekomstige verwachte updates. Bekijk mijn vorige post voor meer details over het verzamelen van live gegevens van pushshift.io. Bedankt Jason Baumgartner voor de constante aanvoer!
Ik ben Felipe Hoffa, een Developer Advocate voor Google Cloud. Volg me op @felipehoffa, vind mijn eerdere berichten op medium.com/@hoffa, en alles over BigQuery op reddit.com/r/bigquery.