Real Time vs Batch Processing vs Stream Processing
Met de constante snelheid van innovatie, kunnen ontwikkelaars verwachten terabytes en zelfs petabytes aan data te analyseren in een bepaalde periode van tijd. (Data, immers, trekt meer data aan.)
Dit biedt natuurlijk tal van voordelen. Maar wat te doen met al deze gegevens? Het kan moeilijk zijn om te weten wat de beste manier is om deze technologieën te versnellen en te versnellen, vooral wanneer reacties snel moeten plaatsvinden.
Voor digital-first bedrijven is een groeiende vraag geworden hoe real-time verwerking, batchverwerking en streamverwerking het beste kunnen worden gebruikt. In dit bericht worden de basisverschillen tussen deze typen gegevensverwerking toegelicht.
Realtime besturingssystemen
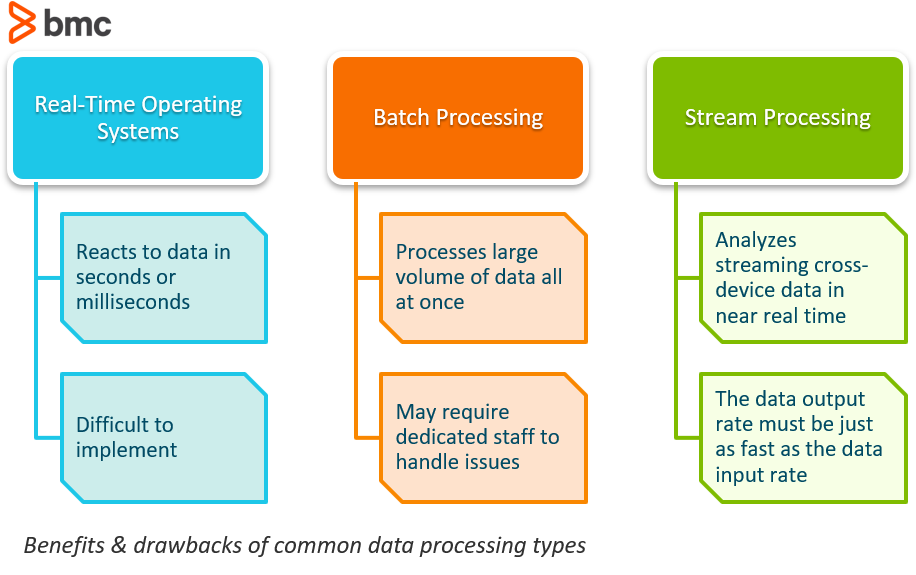
Realtime besturingssystemen verwijzen doorgaans naar de reacties op gegevens. Een systeem kan worden gecategoriseerd als real-time als het kan garanderen dat de reactie binnen een strakke real-world deadline zal zijn, meestal in een kwestie van seconden of milliseconden.
Een van de beste voorbeelden van een real-time systeem zijn die welke worden gebruikt op de aandelenmarkt. Als een beursnotering binnen 10 milliseconden na plaatsing uit het netwerk moet komen, zou dit als een real-time proces worden beschouwd. Of dit nu wordt bereikt door gebruik te maken van een software architectuur die gebruik maakt van stream processing of gewoon verwerking in hardware is irrelevant; de garantie van de strakke deadline is wat het real-time maakt.
Andere situaties waarin het gebruik van real-time systemen voordelig zou zijn, zijn:
- ATM’s
- Luchtverkeersleiding
- Anti-lock remsystemen in uw auto
Uitdagingen
Hoewel dit soort systemen klinkt als een game changer, is de realiteit dat real-time systemen uiterst moeilijk te implementeren zijn door het gebruik van gangbare softwaresystemen. Aangezien deze systemen de controle over de programma-uitvoering overnemen, brengt dit een geheel nieuw abstractieniveau met zich mee.
Wat dit betekent is dat het onderscheid tussen de control-flow van uw programma en de broncode niet langer duidelijk is, omdat het real-time systeem kiest welke taak op dat moment moet worden uitgevoerd. Dit is gunstig, omdat het een hogere productiviteit mogelijk maakt door gebruik te maken van een hogere abstractie en het gemakkelijker kan maken om complexe systemen te ontwerpen, maar het betekent minder controle over het geheel, wat moeilijk kan zijn om te debuggen en te valideren.
Een andere veel voorkomende uitdaging met real-time besturingssystemen is dat de taken geen geïsoleerde entiteiten zijn. Het systeem beslist welke taken worden ingepland en stuurt taken met een hogere prioriteit voor taken met een lagere prioriteit, waardoor hun uitvoering wordt vertraagd totdat alle taken met een hogere prioriteit zijn voltooid.
Meer en meer beginnen sommige softwaresystemen te kiezen voor een vorm van real-time verwerking waarbij de deadline niet zozeer een absolute als wel een waarschijnlijkheid is. Bekend als zachte real-time systemen, zijn ze in staat om meestal of over het algemeen hun deadline te halen, hoewel de prestaties zullen beginnen te verminderen als te veel deadlines worden gemist.
Batch Processing
Batch processing is de verwerking van een groot volume van gegevens in een keer. De gegevens bestaan gemakkelijk uit miljoenen records voor een dag en kunnen op verschillende manieren worden opgeslagen (bestand, record, enz.). De opdrachten worden meestal gelijktijdig voltooid in non-stop, sequentiële volgorde.
Een goed voorbeeld van een batchverwerkingstaak zijn alle transacties die een financieel bedrijf in de loop van een week zou kunnen indienen. Batching kan ook worden gebruikt in:
- Payroll-processen
- Line item facturen
- Supply chain en fulfillment
Batch data processing is een uiterst efficiënte manier om grote hoeveelheden gegevens te verwerken die over een bepaalde periode zijn verzameld. Het helpt ook om de operationele kosten die bedrijven kunnen besteden aan arbeid te verminderen, omdat het niet nodig gespecialiseerde data entry klerken om de werking te ondersteunen. Het kan offline worden gebruikt en geeft managers volledige controle over wanneer de verwerking te starten, of het nu ’s nachts of aan het eind van een week of pay period.
Challenges
Zoals met alles, zijn er een paar nadelen aan het gebruik van batch processing software. Een van de grootste problemen die bedrijven zien, is dat het debuggen van deze systemen lastig kan zijn. Als u niet beschikt over een toegewijd IT-team of professional, proberen om het systeem te repareren wanneer er een fout optreedt kan schadelijk zijn, waardoor de behoefte aan een externe consultant om te helpen.
Een ander probleem met batch processing is dat bedrijven meestal implementeren om geld te besparen, maar de software en opleiding vereist een behoorlijke hoeveelheid kosten in het begin. Managers zullen moeten worden opgeleid om te begrijpen:
- Hoe een batch te plannen
- Wat ze triggert
- Wat bepaalde meldingen betekenen
(Meer informatie over moderne batchverwerking.
Streamverwerking
Streamverwerking is het proces waarbij gegevens die van het ene apparaat naar het andere stromen, vrijwel ogenblikkelijk kunnen worden geanalyseerd.
Deze methode van continue berekening vindt plaats terwijl gegevens door het systeem stromen, zonder verplichte tijdsbeperkingen voor de uitvoer. Met de bijna onmiddellijke stroom, hebben systemen geen grote hoeveelheden gegevens nodig die moeten worden opgeslagen.
Stream processing is zeer gunstig als de gebeurtenissen die u wilt volgen vaak en dicht bij elkaar in de tijd plaatsvinden. Het is ook het beste te gebruiken als de gebeurtenis meteen moet worden gedetecteerd en er snel op moet worden gereageerd. Stream processing is dus nuttig voor taken als fraudedetectie en cyberbeveiliging. Als transactiegegevens worden gestreamd, kunnen frauduleuze transacties worden geïdentificeerd en gestopt nog voordat ze zijn voltooid.
Uitdagingen
Een van de grootste uitdagingen waarmee organisaties bij stream processing worden geconfronteerd, is dat de outputsnelheid van het systeem voor langetermijngegevens net zo snel of sneller moet zijn dan de inputsnelheid van de langetermijngegevens, anders krijgt het systeem problemen met de opslag en het geheugen.
Een andere uitdaging is het uitzoeken van de beste manier om om te gaan met de enorme hoeveelheid gegevens die wordt gegenereerd en verplaatst. Om de gegevensstroom door het systeem op het hoogst optimale niveau te houden, is het noodzakelijk dat organisaties een plan maken voor het verminderen van het aantal kopieën, het richten van rekenkernen en het optimaal benutten van de cache-hiërarchie.
Conclusie
Weliswaar hebben al deze systemen voordelen, maar uiteindelijk moeten organisaties de potentiële voordelen van elk bekijken om te besluiten welke methode het meest geschikt is voor de use-case.
Aanvullende bronnen
- BMC Workload Automation Blog
- BMC Big Data Blog
- Beginner’s Guide To Workplace Automation
- What is een Batch Job?
- What is een Data Pipeline?
Beheer sl as voor uw batch services joe goldberg van BMC Software
Take a modern approach to batch processing

Deze postings zijn mijn eigen postings en vertegenwoordigen niet noodzakelijkerwijs de positie, strategieën of mening van BMC.
Ziet u een fout of heeft u een suggestie? Laat het ons weten door een e-mail te sturen naar [email protected].