Big Data and Hadoop Ecosystem Tutorial
Welkom bij de eerste les ‘Big Data and Hadoop Ecosystem’ van Big Data Hadoop tutorial die deel uitmaakt van ‘Big Data Hadoop and Spark Developer Certification course’ aangeboden door Simplilearn. Deze les is een inleiding tot Big Data en het Hadoop-ecosysteem. In het volgende deel bespreken we de doelstellingen van deze les.
Doelstellingen
Na het voltooien van deze les, zult u in staat zijn om:
-
Het concept van Big Data en de uitdagingen ervan begrijpen
-
Uitleggen wat Big Data is
-
Uitleggen wat Hadoop is en hoe het Big Data-uitdagingen aanpakt
-
Het Hadoop-ecosysteem beschrijven
Laten we nu eens kijken naar een overzicht van Big Data en Hadoop.
Overzicht van Big Data en Hadoop
Vóór het jaar 2000 waren de gegevens relatief klein in vergelijking met de huidige situatie, maar de gegevensberekening was complex. Alle gegevensberekeningen waren afhankelijk van de verwerkingskracht van de beschikbare computers.
Later, toen de gegevens groeiden, was de oplossing om computers te hebben met een groot geheugen en snelle processors. Na 2000 bleven de gegevens echter groeien en kon de aanvankelijke oplossing niet meer baten.
De laatste jaren is er een ongelooflijke explosie geweest in de hoeveelheid gegevens. IBM meldde dat er in 2012 elke dag 2,5 exabytes, of 2,5 miljard gigabytes, aan gegevens werd gegenereerd.
Hier zijn enkele statistieken die de proliferatie van gegevens aangeven uit Forbes, september 2015. 40.000 zoekopdrachten worden elke seconde uitgevoerd op Google. Tot 300 uur video wordt elke minuut geüpload naar YouTube.
In Facebook worden 31,25 miljoen berichten verzonden door de gebruikers en 2,77 miljoen video’s worden elke minuut bekeken. In 2017 zal bijna 80% van de foto’s op smartphones worden genomen.
In 2020 zal ten minste een derde van alle gegevens via de cloud (een netwerk van servers die via internet met elkaar zijn verbonden) gaan. Tegen het jaar 2020 zal er elke seconde ongeveer 1,7 megabyte aan nieuwe informatie worden gecreëerd voor elke mens op de planeet.
Data groeit sneller dan ooit tevoren. U kunt meer computers gebruiken om deze steeds groeiende gegevens te beheren. In plaats van één machine die het werk doet, kun je meerdere machines gebruiken. Dit wordt een gedistribueerd systeem genoemd.
U kunt de Big Data Hadoop and Spark Developer Certification-cursus Preview hier bekijken!
Laten we eens naar een voorbeeld kijken om te begrijpen hoe een gedistribueerd systeem werkt.
Hoe werkt een gedistribueerd systeem?
Stel dat je één machine hebt met vier invoer- en uitvoerkanalen. De snelheid van elk kanaal is 100 MB/sec en u wilt er één terabyte aan gegevens op verwerken.
Het duurt 45 minuten voor één machine om één terabyte aan gegevens te verwerken. Laten we nu eens aannemen dat één terabyte aan gegevens wordt verwerkt door 100 machines met dezelfde configuratie.
Het zal slechts 45 seconden duren voor 100 machines om één terabyte aan gegevens te verwerken. Gedistribueerde systemen hebben minder tijd nodig om Big Data te verwerken.
Laten we nu eens kijken naar de uitdagingen van een gedistribueerd systeem.
Uitdagingen van gedistribueerde systemen
Omdat er meerdere computers worden gebruikt in een gedistribueerd systeem, is de kans op systeemfalen groot. Ook is er een limiet aan de bandbreedte.
De complexiteit van programmeren is ook hoog omdat het moeilijk is om gegevens en processen te synchroniseren. Hadoop kan deze uitdagingen aan.
Laten we in de volgende sectie begrijpen wat Hadoop is.
Wat is Hadoop?
Hadoop is een raamwerk dat de gedistribueerde verwerking van grote datasets over clusters van computers mogelijk maakt met behulp van eenvoudige programmeermodellen. Het is geïnspireerd op een technisch document gepubliceerd door Google.
Het woord Hadoop heeft geen betekenis. Doug Cutting, die Hadoop ontdekte, noemde het naar zijn zoon geelgekleurde speelgoedolifant.
Laten we bespreken hoe Hadoop de drie uitdagingen van het gedistribueerde systeem oplost, zoals de grote kans op systeemfalen, de beperking van de bandbreedte en de complexiteit van de programmering.
De vier belangrijkste kenmerken van Hadoop zijn:
-
Economisch: De systemen zijn zeer economisch omdat gewone computers kunnen worden gebruikt voor gegevensverwerking.
-
Betrouwbaar: Het is betrouwbaar omdat het kopieën van de gegevens op verschillende machines opslaat en bestand is tegen hardwarefouten.
-
Schaalbaar: Het is gemakkelijk schaalbaar, zowel horizontaal als verticaal. Een paar extra nodes helpen bij het opschalen van het framework.
-
Flexibel: Het is flexibel en u kunt zoveel gestructureerde en ongestructureerde gegevens opslaan als u nodig hebt en besluiten om ze later te gebruiken.
Traditioneel werden gegevens op een centrale locatie opgeslagen en werden ze tijdens runtime naar de processor gestuurd. Deze methode werkte goed voor beperkte gegevens.
Moderne systemen ontvangen echter terabytes aan gegevens per dag, en het is moeilijk voor de traditionele computers of Relational Database Management System (RDBMS) om grote hoeveelheden gegevens naar de processor te sturen.
Hadoop bracht een radicale aanpak. In Hadoop gaat het programma naar de gegevens, niet omgekeerd. Het verdeelt de gegevens eerst over meerdere systemen en voert later de berekening uit waar de gegevens zich ook bevinden.
In de volgende sectie zullen we bespreken hoe Hadoop verschilt van het traditionele databasesysteem.
Verschil tussen traditioneel databasesysteem en Hadoop
De onderstaande tabel helpt u onderscheid te maken tussen traditioneel databasesysteem en Hadoop.
|
Traditioneel databasesysteem |
Hadoop |
|
Gegevens worden op een centrale plaats opgeslagen en tijdens runtime naar de processor gestuurd. |
In Hadoop gaat het programma naar de gegevens toe. Het verdeelt de gegevens eerst over meerdere systemen en voert later de berekening uit waar de gegevens zich ook bevinden. |
|
Traditionele databasesystemen kunnen niet worden gebruikt om een aanzienlijke hoeveelheid gegevens (big data) te verwerken en op te slaan. |
Hadoop werkt beter wanneer de gegevens een grote omvang hebben. Het kan een grote hoeveelheid gegevens efficiënt en effectief verwerken en opslaan. |
|
Traditioneel RDBMS wordt alleen gebruikt om gestructureerde en semigestructureerde gegevens te beheren. Het kan niet worden gebruikt om ongestructureerde gegevens te beheren. |
Hadoop kan een verscheidenheid aan gegevens verwerken en opslaan, of deze nu gestructureerd of ongestructureerd zijn. |
Laten we het verschil tussen een traditioneel RDBMS en Hadoop bespreken aan de hand van een analogie.
Je hebt vast wel eens het verschil opgemerkt in de eetstijl van een mens en een tijger. Een mens eet voedsel met behulp van een lepel, waarbij het voedsel naar de mond wordt gebracht. Terwijl, een tijger brengt zijn mond naar het voedsel.
Nu, als het voedsel is gegevens en de mond is een programma, de eetstijl van een mens verbeeldt traditionele RDBMS en die van de tijger verbeeldt Hadoop.
Laten we het Hadoop Ecosysteem bekijken in de volgende sectie.
Hadoop Ecosysteem
Hadoop Ecosysteem Hadoop heeft een ecosysteem dat zich heeft ontwikkeld vanuit zijn drie kerncomponenten verwerking, resource management, en opslag. In dit onderwerp leert u de componenten van het Hadoop-ecosysteem en hoe ze hun rol vervullen tijdens de verwerking van Big Data. Het
Hadoop-ecosysteem groeit voortdurend om te voldoen aan de behoeften van Big Data. Het bestaat uit de volgende twaalf componenten:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
In de volgende secties leert u meer over de rol van elke component van het Hadoop-ecosysteem.

Laat ons de rol van elke component van het Hadoop-ecosysteem begrijpen.
Componenten van het Hadoop-ecosysteem
Laten we beginnen met de eerste component HDFS van het Hadoop-ecosysteem.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS is een opslaglaag voor Hadoop.
-
HDFS is geschikt voor gedistribueerde opslag en verwerking, dat wil zeggen dat de gegevens tijdens de opslag eerst worden gedistribueerd en vervolgens worden verwerkt.
-
HDFS biedt streaming-toegang tot bestandssysteemgegevens.
-
HDFS biedt bestandstoestemming en authenticatie.
-
HDFS gebruikt een opdrachtregelinterface voor interactie met Hadoop.
Wat slaat gegevens op in HDFS? Het is HBase dat gegevens opslaat in HDFS.
HBase
-
HBase is een NoSQL database of niet-relationele database.
-
HBase is belangrijk en wordt voornamelijk gebruikt wanneer u willekeurige, real-time, lees- of schrijftoegang tot uw Big Data nodig hebt.
-
Het biedt ondersteuning voor een grote hoeveelheid gegevens en een hoge verwerkingscapaciteit.
-
In een HBase kan een tabel duizenden kolommen bevatten.
We hebben besproken hoe gegevens worden gedistribueerd en opgeslagen. Laten we nu eens begrijpen hoe deze gegevens worden opgenomen of overgebracht naar HDFS. Sqoop doet precies dit.
Wat is Sqoop?
-
Sqoop is een tool die is ontworpen om gegevens over te brengen tussen Hadoop en relationele databaseservers.
-
Het wordt gebruikt om gegevens te importeren van relationele databases (zoals Oracle en MySQL) naar HDFS en om gegevens te exporteren van HDFS naar relationele databases.
Als u eventgegevens wilt opnemen, zoals streaming data, sensorgegevens of logbestanden, dan kunt u Flume gebruiken. We zullen Flume in de volgende sectie bekijken.
Flume
-
Flume is een gedistribueerde service die gebeurtenisgegevens verzamelt en naar HDFS overdraagt.
-
Het is bij uitstek geschikt voor gebeurtenisgegevens van meerdere systemen.
Nadat de gegevens naar HDFS zijn overgedragen, worden ze verwerkt. Een van de frameworks die gegevens verwerken is Spark.
Wat is Spark?
-
Spark is een open source cluster computing framework.
-
Het biedt tot 100 keer snellere prestaties voor enkele toepassingen met in-memory primitieven in vergelijking met het tweetraps schijfgebaseerde MapReduce-paradigma van Hadoop.
-
Spark kan in het Hadoop-cluster worden uitgevoerd en gegevens in HDFS verwerken.
-
Het ondersteunt ook een breed scala aan workloads, waaronder Machine learning, Business intelligence, Streaming en Batch processing.
Spark heeft de volgende hoofdcomponenten:
-
Spark Core en Resilient Distributed datasets of RDD
-
Spark SQL
-
Spark streaming
-
Machine learning library of Mlib
-
Graphx.
Spark wordt nu veel gebruikt, en u zult er in volgende lessen meer over leren.
Hadoop MapReduce
-
Hadoop MapReduce is het andere framework dat gegevens verwerkt.
-
Het is de oorspronkelijke Hadoop-verwerkingsengine, die hoofdzakelijk op Java is gebaseerd.
-
Het is gebaseerd op het map and reduces-programmeermodel.
-
Veel tools zoals Hive en Pig zijn gebouwd op een map-reduce-model.
-
Het heeft een uitgebreide en volwassen fouttolerantie ingebouwd in het framework.
-
Het wordt nog steeds veel gebruikt, maar verliest terrein aan Spark.
Nadat de gegevens zijn verwerkt, worden ze geanalyseerd. Dit kan worden gedaan door een open-source high-level data flow systeem genaamd Pig. Het wordt voornamelijk gebruikt voor analytics.
Laten we nu begrijpen hoe Pig wordt gebruikt voor analytics.
Pig
-
Pig converteert zijn scripts naar Map en Reduce code, waardoor de gebruiker geen complexe MapReduce programma’s hoeft te schrijven.
-
Ad-hocquery’s zoals Filter en Join, die moeilijk zijn uit te voeren in MapReduce, kunnen eenvoudig worden uitgevoerd met Pig.
-
U kunt Impala ook gebruiken om gegevens te analyseren.
-
Het is een open-source SQL-engine met hoge prestaties, die op het Hadoop-cluster draait.
-
Het is ideaal voor interactieve analyse en heeft een zeer lage latentie, die in milliseconden kan worden gemeten.
Impala
-
Impala ondersteunt een dialect van SQL, zodat gegevens in HDFS worden gemodelleerd als een databasetabel.
-
U kunt ook gegevensanalyses uitvoeren met HIVE. Het is een abstractielaag bovenop Hadoop.
-
HIVE lijkt erg op Impala. Het verdient echter de voorkeur voor gegevensverwerking en Extract Transform Load, ook bekend als ETL, bewerkingen.
-
Impala verdient de voorkeur voor ad-hoc query’s.
HIVE
-
HIVE voert query’s uit met behulp van MapReduce; een gebruiker hoeft echter geen code op low-level MapReduce te schrijven.
-
Hive is geschikt voor gestructureerde gegevens. Nadat de gegevens zijn geanalyseerd, zijn ze klaar voor de gebruikers om te worden geopend.
Nu we weten wat HIVE doet, zullen we bespreken wat het zoeken van gegevens ondersteunt. Het zoeken van gegevens gebeurt met Cloudera Search.
Cloudera Search
-
Search is een van Cloudera’s near-real-time toegangsproducten. Het stelt niet-technische gebruikers in staat om gegevens die zijn opgeslagen in of opgenomen in Hadoop en HBase te doorzoeken en te verkennen.
-
Gebruikers hebben geen SQL- of programmeerkennis nodig om Cloudera Search te gebruiken, omdat het een eenvoudige, full-text interface biedt voor zoekopdrachten.
-
Een ander voordeel van Cloudera Search ten opzichte van stand-alone zoekoplossingen is het volledig geïntegreerde platform voor gegevensverwerking.
-
Cloudera Search maakt gebruik van het flexibele, schaalbare en robuuste opslagsysteem dat bij CDH of Cloudera Distribution, inclusief Hadoop, wordt geleverd. Hierdoor is het niet langer nodig om grote datasets te verplaatsen tussen infrastructuren om zakelijke taken uit te voeren.
-
Hadoop-taken zoals MapReduce, Pig, Hive en Sqoop hebben workflows.
Oozie
-
Oozie is een workflow- of coördinatiesysteem dat u kunt gebruiken om Hadoop-taken te beheren.
De levenscyclus van Oozie-toepassingen wordt in het onderstaande diagram weergegeven.
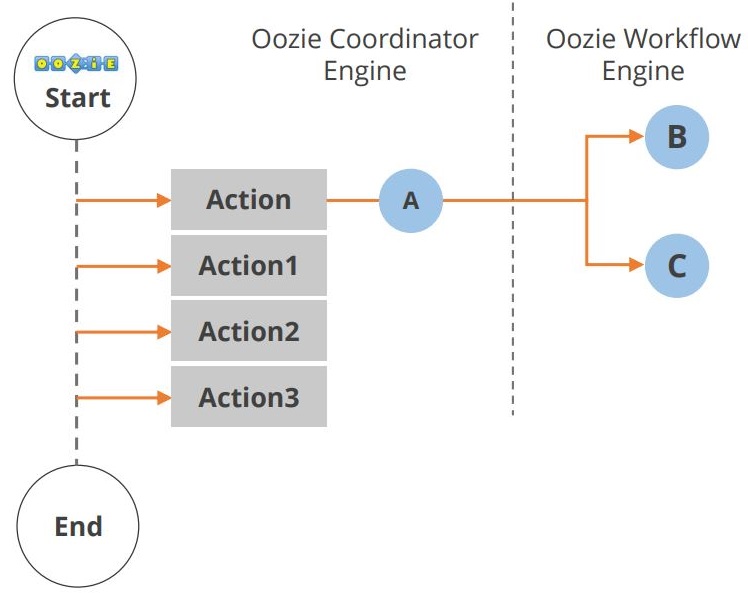 Zoals u kunt zien, vinden er meerdere acties plaats tussen het begin en het einde van de workflow. Een andere component in het Hadoop-ecosysteem is Hue. Laten we nu eens naar Hue kijken.
Zoals u kunt zien, vinden er meerdere acties plaats tussen het begin en het einde van de workflow. Een andere component in het Hadoop-ecosysteem is Hue. Laten we nu eens naar Hue kijken.
Hue
Hue is een acroniem voor Hadoop User Experience. Het is een open-source webinterface voor Hadoop. U kunt de volgende bewerkingen uitvoeren met Hue:
-
Upload en browse data
-
Query een tabel in HIVE en Impala
-
Run Spark en Pig jobs en workflows Search data
-
Al met al maakt Hue Hadoop eenvoudiger te gebruiken.
-
Het biedt ook SQL-editors voor HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL en Solr SQL.
Na dit korte overzicht van de twaalf componenten van het Hadoop-ecosysteem, bespreken we nu hoe deze componenten samenwerken om Big Data te verwerken.
Fasen van Big Data-verwerking
Er zijn vier fasen van Big Data-verwerking: Ingest, Verwerken, Analyseren, Toegang. Laten we ze in detail bekijken.
Ingest
De eerste fase van Big Data-verwerking is Ingest. De gegevens worden ingested of overgebracht naar Hadoop vanuit verschillende bronnen, zoals relationele databases, systemen of lokale bestanden. Sqoop brengt gegevens over van RDBMS naar HDFS, terwijl Flume eventgegevens overbrengt.
Verwerking
De tweede fase is Verwerking. In dit stadium worden de gegevens opgeslagen en verwerkt. De gegevens worden opgeslagen in het gedistribueerde bestandssysteem, HDFS, en de NoSQL gedistribueerde gegevens, HBase. Spark en MapReduce voeren de gegevensverwerking uit.
Analyze
De derde fase is Analyze. Hier worden de gegevens geanalyseerd door verwerkingsframeworks zoals Pig, Hive en Impala.
Pig converteert de gegevens met behulp van een map en reduce en analyseert ze vervolgens. Hive is ook gebaseerd op de map en reduce programmering en is het meest geschikt voor gestructureerde gegevens.
Toegang
De vierde fase is Toegang, die wordt uitgevoerd door tools zoals Hue en Cloudera Search. In dit stadium hebben gebruikers toegang tot de geanalyseerde gegevens.
Hue is de webinterface, terwijl Cloudera Search een tekstinterface biedt voor het verkennen van gegevens.
Bekijk hier de cursus Big Data Hadoop en Spark Developer Certificering!
Samenvatting
Laten we nu samenvatten wat we in deze les hebben geleerd.
-
Hadoop is een raamwerk voor gedistribueerde opslag en verwerking.
-
De kerncomponenten van Hadoop zijn HDFS voor opslag, YARN voor cluster-resourcebeheer en MapReduce of Spark voor verwerking.
-
Het Hadoop-ecosysteem omvat meerdere componenten die elke fase van de verwerking van Big Data ondersteunen.
-
Flume en Sqoop nemen gegevens op, HDFS en HBase slaan gegevens op, Spark en MapReduce verwerken gegevens, Pig, Hive en Impala analyseren gegevens, Hue en Cloudera Search helpen bij het onderzoeken van gegevens.
-
Ozie beheert de workflow van Hadoop-taken.
Conclusie
Dit is het einde van de les over Big Data en het Hadoop-ecosysteem. In de volgende les zullen we HDFS en YARN bespreken.
Vind onze Big Data Hadoop en Spark Developer Online Classroom training klassen in top steden:
| Naam | Datum | Plaats | |
|---|---|---|---|
| Big Data Hadoop en Spark Developer | 3 apr -15 mei 2021, Weekend batch | Uw stad | Bekijk details |
| Big Data Hadoop en Spark Developer | 12 apr -4 mei 2021, Weekdagen batch | Jouw Stad | Bekijk Details |
| Big Data Hadoop en Spark Developer | 24 Apr -5 Jun 2021, Weekend batch | Uw Stad | Bekijk Details |
{{lectureCoursePreviewTitle}} Bekijk Transcript Bekijk Video
Om meer te leren, volg de Cursus
Big Data Hadoop and Spark Developer Certification Training
Ga naar Cursus
Om meer te leren, volg de Cursus
Big Data Hadoop and Spark Developer Certification Training
Om meer te leren, volg de Cursus
Big Data Hadoop en Spark Developer Certification Training Ga naar Cursus