Reddit AmItheAssholeは男性よりも女性に優しい – SQLによる証明?
redditorが女性について話しながら「私はアホか」と聞くと、アホと判断される変化が高くなるそうです。 これらの指標を確認してみましょう – BigQuery、dbt、Data Studioで
ここに書いたことを絶対的な真実として受け取らないように気をつけてください。 Twitter で何人かの人が問題を指摘し、私が提供した分析に修正を加えてくれました。 この投稿を最初に提示されたとおりに読むこと、そして反応を読むことは、私が反応を読みながら行ったように、あなたにとって多くのことを学ぶための素晴らしい方法となりえます。
Context
/r/amItheAsshole は、コメント数で、最も活発なサブレディット第 4 位に成長しました。 人々は自分の話をするためにこのサブレディットにやってきて、他のレディターに「私はここのアホか? 5788>
この結果の私のツイートは多くの関心を集めました。
Including the question – reddit is nicer to women or to men?
Deciding gender
投稿のタイトルや内容を見ると、「私」が男性か女性かを判断するのは難しいかもしれませんが、話の中に存在する「彼女/彼/女/男」の数を数えるのはかなり簡単です。
いくつかのランダムな投稿と、これらの代名詞と性別の単語のそれぞれのカウントを見てみましょう:

例の性別のある代名詞や単語のカウントは、その話が誰についてのものであるかと一致していることがわかります。 これらのストーリーは、男性の顧客、女性のガールフレンド、男性の隣人、男性の息子、および女性の 10 代の娘についてです。
これらの数字を使用して、任意のルールを設定できます。 逆に、女性についての投稿であるとするルールも使えます。 数字が近すぎるか無効の場合、その投稿を「中立」と呼ぶことにします。
分析を単純化するために設定できる別のルール:
- 判定が「アホではない」または「ここにアホはいない」なら「投稿者はアホではない」と言えるでしょう。
- 判定が『アホ』か『みんなクソ』なら『投稿者はアホ』と言える。
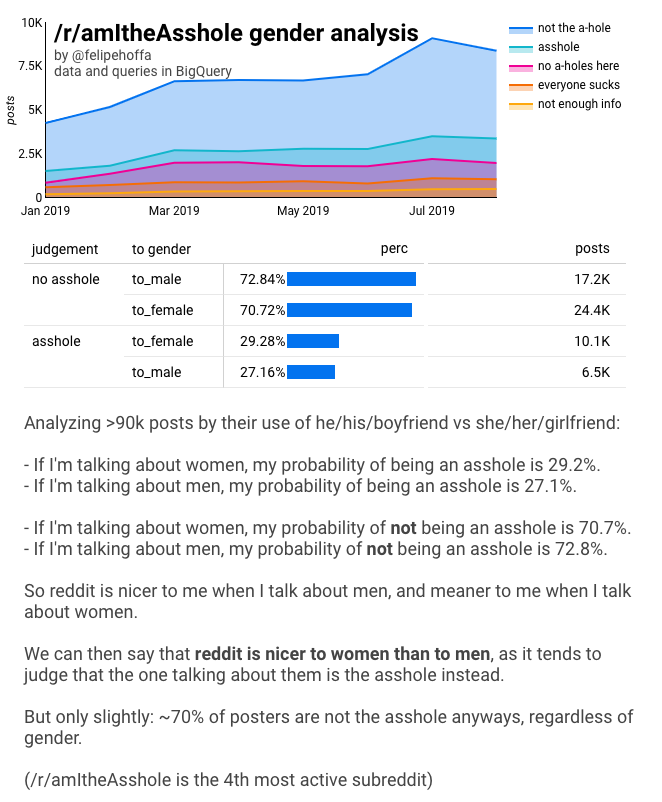
これらの投稿を全て集計すると、次のような数字になる:

この結果を最初に発表したとき、「この数字は近すぎる、統計的誤差かもしれない」と言われた。
Statistical significance?
どうすれば、数字が単なる統計誤差ではないと判断できるか? 月ごとの傾向を見てみよう-安定してるか?

そうだ!!
月ごとの判断は、その投稿者が女性を話題にしたら、その人はアホになる確率は高くなるんだね。 月によって傾向は異なるが、男性について話すときよりも女性について話すときのほうが、明らかにアホになる確率が高い。 もしこのわずかな差が統計的な偶然であれば、代わりに傾向が大きく跳ね上がることが予想されます。
また、このツイートにもあるように、この結果は非常に特殊であることに注意してください。
To I replied
How-to
今回初めて dbt を使用しましたが、全てのコードは GitHub に置いておきました。 この素晴らしいツールを使い始める手助けをしてくれた Claire Carroll に感謝します!
BigQueryですべての/r/AmItheAssholeの投稿を新しいテーブルに抽出するには:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
そして各投稿の性別と判定は:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
そして最後にここで紹介する統計があります。
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
議論
この投稿のTwitterスレッドには、たくさんの洞察に満ちた楽しい返信があります:
自由に議論に参加してください(そして私が間違っていたら教えてください)。). お互いに親切であることを忘れないでください – ほとんどの人はとにかくろくでなしではありません。
Want more?
私は、BigQuery の現在のフル reddit アーカイブが停止するときであるため、2019年8月までしかカバーしていません – 将来予想される更新まで。 pushshift.ioからライブデータを収集するための詳細については、私の以前の投稿を確認してください。 常に提供してくれる Jason Baumgartner に感謝します!
Google Cloud のデベロッパー アドボケート担当の Felipe Hoffa です。 私の過去の投稿は medium.com/@hoffa で、BigQuery については reddit.com/r/bigquery.
でご覧いただけます。