Reddit AmItheAsshole è più gentile con le donne che con gli uomini – una prova SQL?
Quando i redditors chiedono “sono io lo stronzo” mentre parlano di donne, hanno un cambiamento maggiore di essere giudicati come lo stronzo. Controlliamo queste metriche – con BigQuery, dbt, e Data Studio
Assicuratevi di non prendere nulla di quello che ho scritto qui come la verità assoluta. Diverse persone su Twitter hanno notato problemi e aggiunto correzioni all’analisi che ho offerto. Leggere questo post come originariamente presentato – e le reazioni – può essere un ottimo modo per voi di imparare tanto quanto ho fatto io leggendo le risposte. Puoi trovare molti dei loro pensieri non filtrati seguendo questo thread di Twitter.
Context
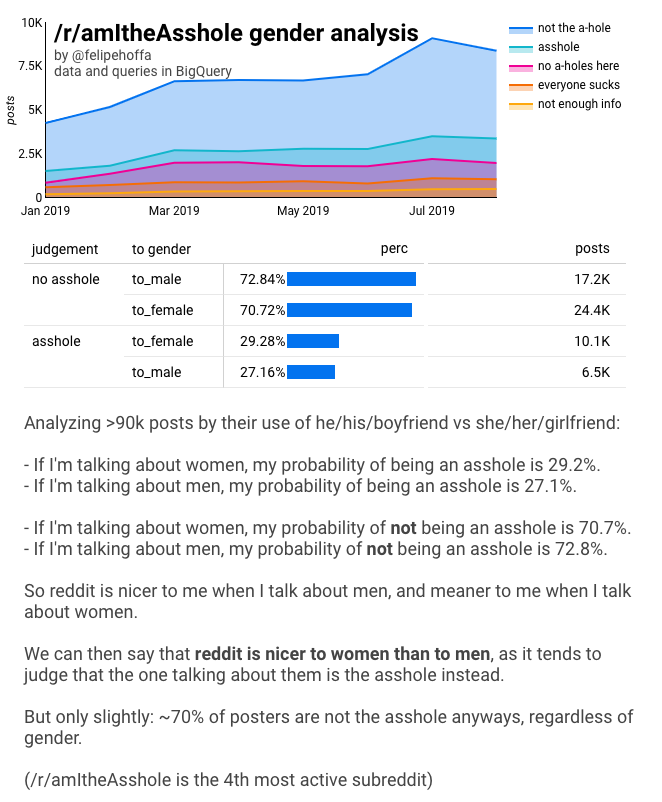
/r/amItheAsshole è cresciuto fino a diventare il 4° subreddit più attivo – per numero di commenti. Le persone vengono in questo subreddit per raccontare le loro storie, e chiedono agli altri redditors “sono io lo stronzo qui? Risulta che la maggior parte delle persone sono giudicate come “non lo stronzo”, come si vede in questo grafico:
Il mio tweet con questi risultati ha avuto molta attenzione:
Inclusa la domanda – reddit è più gentile con le donne o con gli uomini?
Decidere il genere
Guardando il titolo o il contenuto di un post, potresti avere difficoltà a decidere se “io” sia un uomo o una donna – ma è abbastanza facile contare il numero di “lei/lui/lui/il suo/la sua ragazza/fidanzato/fidanzata” presenti nella storia.
Guardiamo alcuni post a caso, e il conteggio di ciascuno di questi pronomi e parole di genere:

Possiamo vedere che il conteggio dei pronomi e delle parole di genere nell’esempio corrisponde a chi riguarda la storia. Queste storie riguardano un cliente maschio, una fidanzata femmina, un vicino maschio, un figlio maschio e una figlia adolescente femmina.
Con questi numeri, possiamo ora stabilire una regola arbitraria: se c’è più del doppio di pronomi maschili che femminili, quel post riguarda un uomo. Possiamo usare la regola opposta per dire che il post riguarda una donna. Se i numeri sono troppo vicini o nulli, chiameremo il post “neutro”.
Un’altra regola che possiamo fissare per semplificare l’analisi:
- Se il giudizio è “non il coglione” o “nessun coglione qui” allora possiamo dire “il poster non è un coglione”.
- Se il giudizio è ‘stronzo’ o ‘tutti fanno schifo’ allora possiamo dire ‘il poster è uno stronzo’.
Se aggregiamo tutti questi post, arriviamo ai numeri:

Quando ho presentato per la prima volta questi risultati, mi è stato detto “questi numeri sono troppo vicini, potrebbero essere un errore statistico”.
Significatività statistica?
Come possiamo dire che i numeri non sono solo un errore statistico? Vediamo la tendenza mese per mese – è stabile?

Sì! La tendenza varia di mese in mese, ma c’è una chiara maggiore possibilità di essere uno stronzo quando si parla di donne rispetto a quando si parla di uomini. Se la piccola differenza fosse solo un caso statistico, ci aspetteremmo invece che la tendenza saltasse selvaggiamente.
E si prega di notare che questi risultati sono molto specifici, come nota questo tweet:
A cui ho risposto
How-to
Questa volta sto usando dbt per la prima volta, e ho lasciato tutto il mio codice su GitHub. Grazie Claire Carroll per il tuo aiuto per iniziare con questo fantastico strumento!
Per estrarre tutti i post di /r/AmItheAsshole in BigQuery in una nuova tabella, puoi fare:
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Poi il genere e il giudizio per ogni post possono essere determinati con una query come:
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
E infine le statistiche presentate qui:
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Discussione
Troverete molte risposte perspicaci e divertenti sul thread di twitter per questo post:
Sentitevi liberi di partecipare alla discussione (e ditemi se sbaglio?). Ricordatevi di essere gentili l’uno con l’altro – la maggior parte delle persone non è comunque lo stronzo.
Vuoi di più?
Ho coperto solo fino ad agosto 2019 perché è quando l’attuale archivio reddit completo in BigQuery si ferma – fino ai futuri aggiornamenti previsti. Controlla il mio post precedente per maggiori dettagli sulla raccolta di dati dal vivo da pushshift.io. Grazie Jason Baumgartner per la fornitura costante!
Sono Felipe Hoffa, un Developer Advocate per Google Cloud. Seguitemi su @felipehoffa, trovate i miei post precedenti su medium.com/@hoffa, e tutto su BigQuery su reddit.com/r/bigquery.