Real Time vs Batch Processing vs Stream Processing
Con il costante tasso di innovazione, gli sviluppatori possono aspettarsi di analizzare terabyte e persino petabyte di dati in qualsiasi periodo di tempo. (I dati, dopo tutto, attirano altri dati.)
Questo permette numerosi vantaggi, naturalmente. Ma cosa fare con tutti questi dati? Può essere difficile conoscere il modo migliore per accelerare e velocizzare queste tecnologie, specialmente quando le reazioni devono avvenire rapidamente.
Per le aziende digital-first, una domanda crescente è diventata come utilizzare al meglio l’elaborazione in tempo reale, l’elaborazione in batch e l’elaborazione in flusso. Questo post spiegherà le differenze di base tra questi tipi di elaborazione dati.
Sistemi operativi in tempo reale
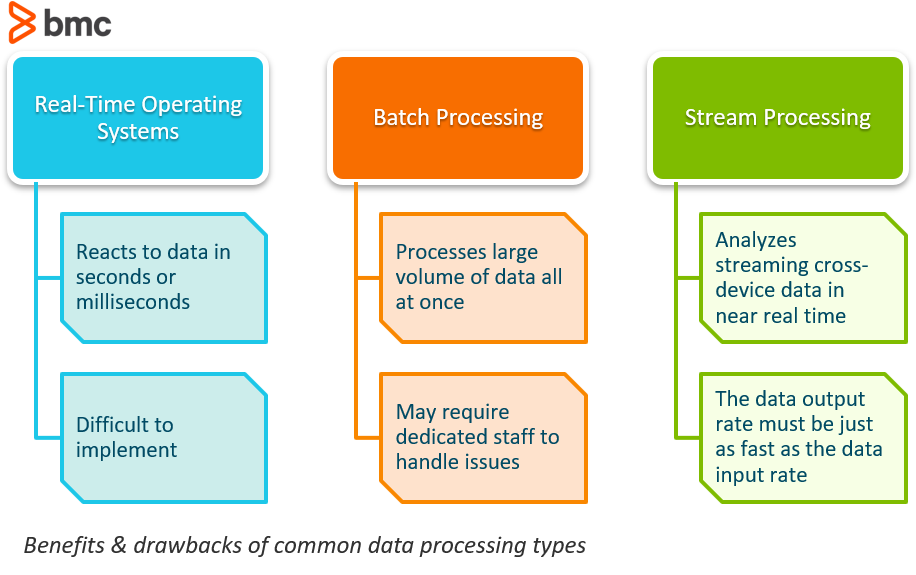
I sistemi operativi in tempo reale si riferiscono tipicamente alle reazioni ai dati. Un sistema può essere categorizzato come in tempo reale se può garantire che la reazione avverrà entro una stretta scadenza del mondo reale, di solito in una questione di secondi o millisecondi.
Uno dei migliori esempi di un sistema in tempo reale sono quelli usati nel mercato azionario. Se una quotazione azionaria dovesse arrivare dalla rete entro 10 millisecondi dall’immissione, questo sarebbe considerato un processo in tempo reale. Che questo sia stato ottenuto utilizzando un’architettura software che ha utilizzato l’elaborazione in flusso o solo l’elaborazione in hardware è irrilevante; la garanzia della scadenza stretta è ciò che lo rende in tempo reale.
Altre situazioni in cui l’uso di sistemi in tempo reale sarebbe vantaggioso sono:
- ATM
- Controllo del traffico aereo
- Sistema di frenata antibloccaggio nella vostra auto
Sfide
Mentre questo tipo di sistema suona come una svolta, la realtà è che i sistemi in tempo reale sono estremamente difficili da implementare attraverso l’uso di comuni sistemi software. Poiché questi sistemi prendono il controllo dell’esecuzione del programma, portano un livello completamente nuovo di astrazione.
Quello che significa è che la distinzione tra il flusso di controllo del vostro programma e il codice sorgente non è più evidente perché il sistema in tempo reale sceglie quale compito eseguire in quel momento. Questo è vantaggioso, in quanto permette una maggiore produttività usando una maggiore astrazione e può rendere più facile progettare sistemi complessi, ma significa meno controllo complessivo, che può essere difficile da debuggare e validare.
Un’altra sfida comune con i sistemi operativi in tempo reale è che i compiti non sono entità isolate. Il sistema decide quali programmare e invia i compiti a priorità più alta prima di quelli a priorità più bassa, ritardando così la loro esecuzione fino a quando tutti i compiti a priorità più alta sono completati.
Sempre più, alcuni sistemi software stanno iniziando a scegliere un tipo di elaborazione in tempo reale in cui la scadenza non è un assoluto ma una probabilità. Conosciuti come sistemi soft real-time, sono in grado di rispettare solitamente o generalmente la loro scadenza, anche se le prestazioni inizieranno a degradare se troppe scadenze non vengono rispettate.
L’elaborazione in lotti
L’elaborazione in lotti è l’elaborazione di un grande volume di dati tutti in una volta. I dati consistono facilmente in milioni di record per un giorno e possono essere memorizzati in una varietà di modi (file, record, ecc.). I lavori sono tipicamente completati simultaneamente in un ordine sequenziale non stop.
Un esempio di lavoro di elaborazione in batch sono tutte le transazioni che una società finanziaria potrebbe presentare nel corso di una settimana. Il batching può essere usato anche in:
- Pagamenti
- Fatture in linea
- Catena di fornitura e adempimento
L’elaborazione dei dati in batch è un modo estremamente efficiente per elaborare grandi quantità di dati che vengono raccolti in un periodo di tempo. Aiuta anche a ridurre i costi operativi che le aziende potrebbero spendere in manodopera perché non richiede impiegati specializzati nell’inserimento dei dati per sostenere il suo funzionamento. Può essere usato offline e dà ai manager il controllo completo su quando iniziare l’elaborazione, che sia durante la notte o alla fine di una settimana o di un periodo di paga.
Sfide
Come ogni cosa, ci sono alcuni svantaggi nell’utilizzo di un software di elaborazione batch. Uno dei maggiori problemi che le aziende vedono è che il debug di questi sistemi può essere difficile. Se non avete un team IT dedicato o un professionista, cercare di riparare il sistema quando si verifica un errore potrebbe essere dannoso, causando la necessità di un consulente esterno per assistere.
Un altro problema con l’elaborazione in batch è che le aziende di solito lo implementano per risparmiare denaro, ma il software e la formazione richiedono una discreta quantità di spese all’inizio. I manager dovranno essere addestrati per capire:
- Come programmare un batch
- Cosa li innesca
- Cosa significano certe notifiche
(Per saperne di più sulla moderna elaborazione dei batch.)
Stream Processing
Stream Processing è il processo di essere in grado di analizzare quasi istantaneamente i dati che scorrono da un dispositivo all’altro.
Questo metodo di calcolo continuo avviene mentre i dati scorrono attraverso il sistema senza limiti di tempo obbligatori sull’output. Con il flusso quasi istantaneo, i sistemi non richiedono grandi quantità di dati da memorizzare.
L’elaborazione in streaming è altamente vantaggiosa se gli eventi che si desidera tracciare accadono frequentemente e vicini nel tempo. È anche meglio da utilizzare se l’evento deve essere rilevato subito e rispondere rapidamente. L’elaborazione del flusso, quindi, è utile per compiti come il rilevamento delle frodi e la sicurezza informatica. Se i dati delle transazioni vengono elaborati in flusso, le transazioni fraudolente possono essere identificate e fermate prima ancora che siano completate.
Sfide
Una delle più grandi sfide che le organizzazioni affrontano con l’elaborazione in flusso è che la velocità di uscita dei dati a lungo termine del sistema deve essere altrettanto veloce, o più veloce, della velocità di ingresso dei dati a lungo termine, altrimenti il sistema inizierà ad avere problemi con lo stoccaggio e la memoria.
Un’altra sfida è cercare di capire il modo migliore per affrontare l’enorme quantità di dati che viene generata e spostata. Al fine di mantenere il flusso di dati attraverso il sistema che opera al massimo livello ottimale, è necessario per le organizzazioni creare un piano per come ridurre il numero di copie, come indirizzare i kernel di calcolo e come utilizzare la gerarchia della cache nel miglior modo possibile.
Conclusione
Mentre tutti questi sistemi hanno vantaggi, alla fine della giornata le organizzazioni dovrebbero considerare i potenziali benefici di ciascuno per decidere quale metodo è più adatto al caso d’uso.
Risorse aggiuntive
- BMC Workload Automation Blog
- BMC Big Data Blog
- Guida per principianti all’automazione del posto di lavoro
- Cos’è un Batch Job?
Gestisci sl come per i tuoi servizi batch joe goldberg di BMC Software
Approccio moderno all’elaborazione batch

Questi post sono miei e non rappresentano necessariamente la posizione, le strategie o le opinioni di BMC.
Vedi un errore o hai un suggerimento? Facci sapere inviando un’e-mail a [email protected].
.