Big Data and Hadoop Ecosystem Tutorial
Benvenuti alla prima lezione ‘Big Data and Hadoop Ecosystem’ del Big Data Hadoop tutorial che fa parte del ‘Big Data Hadoop and Spark Developer Certification course’ offerto da Simplilearn. Questa lezione è un’introduzione ai Big Data e all’ecosistema Hadoop. Nella prossima sezione, discuteremo gli obiettivi di questa lezione.
Obiettivi
Dopo aver completato questa lezione, sarai in grado di:
-
Comprendere il concetto di Big Data e le sue sfide
-
Spiegare cos’è Big Data
-
Spiegare cos’è Hadoop e come affronta le sfide dei Big Data
-
Descrivere l’ecosistema Hadoop
Diamo ora uno sguardo alla panoramica di Big Data e Hadoop.
Panoramica di Big Data e Hadoop
Prima dell’anno 2000, i dati erano relativamente piccoli rispetto a quelli attuali; tuttavia, il calcolo dei dati era complesso. Tutto il calcolo dei dati dipendeva dalla potenza di elaborazione dei computer disponibili.
Poi, con la crescita dei dati, la soluzione era avere computer con grande memoria e processori veloci. Tuttavia, dopo il 2000, i dati hanno continuato a crescere e la soluzione iniziale non poteva più aiutare.
Negli ultimi anni, c’è stata un’incredibile esplosione nel volume dei dati. IBM ha riferito che 2,5 exabyte, o 2,5 miliardi di gigabyte, di dati, sono stati generati ogni giorno nel 2012.
Ecco alcune statistiche che indicano la proliferazione dei dati da Forbes, settembre 2015. 40.000 query di ricerca vengono eseguite su Google ogni secondo. Su YouTube vengono caricate fino a 300 ore di video ogni minuto.
In Facebook, 31,25 milioni di messaggi vengono inviati dagli utenti e 2,77 milioni di video vengono visti ogni minuto. Entro il 2017, quasi l’80% delle foto saranno scattate con gli smartphone.
Entro il 2020, almeno un terzo di tutti i dati passerà attraverso il Cloud (una rete di server collegati su Internet). Entro il 2020, circa 1,7 megabyte di nuove informazioni saranno create ogni secondo per ogni essere umano sul pianeta.
I dati stanno crescendo più velocemente che mai. È possibile utilizzare più computer per gestire questi dati in continua crescita. Invece di una sola macchina che esegue il lavoro, si possono usare più macchine. Questo è chiamato un sistema distribuito.
Puoi controllare il corso di certificazione Big Data Hadoop and Spark Developer Preview qui!
Guardiamo un esempio per capire come funziona un sistema distribuito.
Come funziona un sistema distribuito?
Supponiamo di avere una macchina che ha quattro canali di input/output. La velocità di ogni canale è di 100 MB/sec e si vuole elaborare un terabyte di dati su di esso.
Una macchina impiegherà 45 minuti per elaborare un terabyte di dati. Ora, supponiamo che un terabyte di dati sia elaborato da 100 macchine con la stessa configurazione.
Ci vorranno solo 45 secondi per 100 macchine per elaborare un terabyte di dati. I sistemi distribuiti impiegano meno tempo per elaborare i Big Data.
Ora, guardiamo le sfide di un sistema distribuito.
Sfide dei sistemi distribuiti
Siccome in un sistema distribuito si usano più computer, ci sono alte possibilità di guasti al sistema. C’è anche un limite alla larghezza di banda.
La complessità della programmazione è anche alta perché è difficile sincronizzare i dati e i processi. Hadoop può affrontare queste sfide.
Comprendiamo cos’è Hadoop nella prossima sezione.
Che cos’è Hadoop?
Hadoop è un framework che permette l’elaborazione distribuita di grandi serie di dati su cluster di computer utilizzando semplici modelli di programmazione. È ispirato da un documento tecnico pubblicato da Google.
La parola Hadoop non ha alcun significato. Doug Cutting, che ha scoperto Hadoop, l’ha chiamato come suo figlio elefante giocattolo di colore giallo.
Discutiamo come Hadoop risolve le tre sfide del sistema distribuito, come le alte probabilità di fallimento del sistema, il limite della larghezza di banda, e la complessità della programmazione.
Le quattro caratteristiche chiave di Hadoop sono:
-
Economico: I suoi sistemi sono altamente economici in quanto i normali computer possono essere utilizzati per l’elaborazione dei dati.
-
Affidabile: È affidabile in quanto memorizza copie dei dati su diverse macchine ed è resistente ai guasti hardware.
-
Scalabile: È facilmente scalabile sia orizzontalmente che verticalmente. Alcuni nodi extra aiutano a scalare il framework.
-
Flessibile: È flessibile e puoi memorizzare tutti i dati strutturati e non strutturati di cui hai bisogno e decidere di usarli in seguito.
Tradizionalmente, i dati venivano memorizzati in una posizione centrale, e venivano inviati al processore in fase di esecuzione. Questo metodo funzionava bene per dati limitati.
Tuttavia, i sistemi moderni ricevono terabyte di dati al giorno, ed è difficile per i computer tradizionali o il Relational Database Management System (RDBMS) spingere alti volumi di dati al processore.
Hadoop ha portato un approccio radicale. In Hadoop, il programma va ai dati, non viceversa. Inizialmente distribuisce i dati a più sistemi e successivamente esegue il calcolo ovunque si trovino i dati.
Nella seguente sezione, parleremo di come Hadoop differisce dal tradizionale sistema di database.
Differenza tra il sistema di database tradizionale e Hadoop
La tabella seguente vi aiuterà a distinguere tra il sistema di database tradizionale e Hadoop.
|
Traditional Database System |
Hadoop |
|
I dati sono memorizzati in una posizione centrale e inviati al processore in fase di esecuzione. |
In Hadoop, il programma va ai dati. Inizialmente distribuisce i dati a più sistemi e successivamente esegue il calcolo ovunque si trovino i dati. |
|
I sistemi di database tradizionali non possono essere utilizzati per elaborare e memorizzare una quantità significativa di dati (big data). |
Hadoop funziona meglio quando le dimensioni dei dati sono grandi. Può elaborare e memorizzare una grande quantità di dati in modo efficiente ed efficace. |
|
L’RDBMS tradizionale è usato per gestire solo dati strutturati e semi-strutturati. Non può essere usato per controllare i dati non strutturati. |
Hadoop può elaborare e memorizzare una varietà di dati, sia strutturati che non strutturati. |
Discutiamo la differenza tra RDBMS tradizionale e Hadoop con l’aiuto di un’analogia.
Hai notato la differenza nello stile alimentare di un essere umano e una tigre. Un umano mangia il cibo con l’aiuto di un cucchiaio, dove il cibo viene portato alla bocca. Invece, una tigre porta la bocca verso il cibo.
Ora, se il cibo sono i dati e la bocca è un programma, lo stile di mangiare di un umano raffigura l’RDBMS tradizionale e quello della tigre raffigura Hadoop.
Guardiamo l’ecosistema Hadoop nella prossima sezione.
Ecosistema Hadoop
Ecosistema Hadoop Hadoop ha un ecosistema che si è evoluto dai suoi tre componenti principali: elaborazione, gestione delle risorse e archiviazione. In questo argomento, imparerai i componenti dell’ecosistema Hadoop e come svolgono i loro ruoli durante l’elaborazione dei Big Data. L
ecosistema Hadoop è in continua crescita per soddisfare le esigenze dei Big Data. Esso comprende i seguenti dodici componenti:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
Apprenderai il ruolo di ogni componente dell’ecosistema Hadoop nelle prossime sezioni.

Comprendiamo il ruolo di ogni componente dell’ecosistema Hadoop.
Componenti dell’ecosistema Hadoop
Iniziamo con il primo componente HDFS dell’ecosistema Hadoop.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS è uno strato di storage per Hadoop.
-
HDFS è adatto per lo stoccaggio e l’elaborazione distribuiti, cioè, mentre i dati vengono memorizzati, prima vengono distribuiti e poi vengono elaborati.
-
HDFS fornisce un accesso in streaming ai dati del file system.
-
HDFS fornisce i permessi e l’autenticazione dei file.
-
HDFS utilizza un’interfaccia a riga di comando per interagire con Hadoop.
Quindi cosa memorizza i dati in HDFS? È HBase che memorizza i dati in HDFS.
HBase
-
HBase è un database NoSQL o database non relazionale.
-
HBase è importante e principalmente utilizzato quando hai bisogno di un accesso casuale, in tempo reale, in lettura o scrittura ai tuoi Big Data.
-
Fornisce supporto ad un alto volume di dati e ad un alto throughput.
-
In un HBase, una tabella può avere migliaia di colonne.
Abbiamo discusso come i dati vengono distribuiti e memorizzati. Ora, cerchiamo di capire come questi dati vengono ingeriti o trasferiti a HDFS. Sqoop fa esattamente questo.
Che cos’è Sqoop?
-
Sqoop è uno strumento progettato per trasferire dati tra Hadoop e server di database relazionali.
-
E’ usato per importare dati da database relazionali (come Oracle e MySQL) a HDFS e per esportare dati da HDFS a database relazionali.
Se vuoi ingerire dati di eventi come dati in streaming, dati di sensori o file di log, allora puoi usare Flume. Vedremo Flume nella prossima sezione.
Flume
-
Flume è un servizio distribuito che raccoglie dati di eventi e li trasferisce su HDFS.
-
E’ ideale per dati di eventi provenienti da più sistemi.
Dopo che i dati vengono trasferiti su HDFS, vengono elaborati. Uno dei framework che elaborano i dati è Spark.
Che cos’è Spark?
-
Spark è un framework open source per il cluster computing.
-
Fornisce prestazioni fino a 100 volte più veloci per alcune applicazioni con primitive in-memoria rispetto al paradigma MapReduce a due fasi basato su disco di Hadoop.
-
Spark può essere eseguito nel cluster Hadoop ed elaborare dati in HDFS.
-
Supporta anche un’ampia varietà di carichi di lavoro, che includono Machine learning, Business intelligence, Streaming e Batch processing.
Spark ha i seguenti componenti principali:
-
Spark Core e Resilient Distributed datasets o RDD
-
Spark SQL
-
Spark streaming
-
Machine learning library o Mlib
-
Graphx.
Spark è ora ampiamente usato, e ne imparerai di più nelle lezioni successive.
Hadoop MapReduce
-
Hadoop MapReduce è l’altro framework che elabora i dati.
-
È il motore di elaborazione originale di Hadoop, che è principalmente basato su Java.
-
È basato sul modello di programmazione map and reduces.
-
Molti strumenti come Hive e Pig sono costruiti su un modello map-reduce.
-
Ha un’estesa e matura tolleranza agli errori incorporata nel framework.
-
È ancora molto usato ma sta perdendo terreno rispetto a Spark.
Dopo che i dati vengono elaborati, vengono analizzati. Può essere fatto da un sistema open-source ad alto livello di flusso di dati chiamato Pig. È usato principalmente per l’analisi.
Comprendiamo ora come Pig è usato per l’analisi.
Pig
-
Pig converte i suoi script in codice Map e Reduce, risparmiando così all’utente di scrivere complessi programmi MapReduce.
-
Le query ad hoc come Filter e Join, che sono difficili da eseguire in MapReduce, possono essere facilmente eseguite utilizzando Pig.
-
È inoltre possibile utilizzare Impala per analizzare i dati.
-
È un motore SQL open-source ad alte prestazioni, che gira sul cluster Hadoop.
-
È ideale per l’analisi interattiva e ha una latenza molto bassa che può essere misurata in millisecondi.
Impala
-
Impala supporta un dialetto di SQL, quindi i dati in HDFS sono modellati come una tabella di database.
-
È anche possibile eseguire analisi dei dati utilizzando HIVE. È un livello di astrazione sopra Hadoop.
-
È molto simile a Impala. Tuttavia, è preferito per l’elaborazione dei dati e le operazioni di Extract Transform Load, note anche come ETL.
-
Impala è preferito per le query ad-hoc.
HIVE
-
HIVE esegue le query usando MapReduce; tuttavia, un utente non ha bisogno di scrivere alcun codice in MapReduce di basso livello.
-
Hive è adatto ai dati strutturati. Dopo che i dati sono stati analizzati, sono pronti per l’accesso da parte degli utenti.
Ora che sappiamo cosa fa HIVE, discuteremo cosa supporta la ricerca dei dati. La ricerca dei dati viene fatta usando Cloudera Search.
Cloudera Search
-
Search è uno dei prodotti di accesso quasi in tempo reale di Cloudera. Consente agli utenti non tecnici di cercare ed esplorare i dati memorizzati o ingeriti in Hadoop e HBase.
-
Gli utenti non hanno bisogno di competenze SQL o di programmazione per utilizzare Cloudera Search perché fornisce una semplice interfaccia full-text per la ricerca.
-
Un altro vantaggio di Cloudera Search rispetto alle soluzioni di ricerca stand-alone è la piattaforma di elaborazione dati completamente integrata.
-
Cloudera Search utilizza il sistema di storage flessibile, scalabile e robusto incluso in CDH o Cloudera Distribution, incluso Hadoop. Questo elimina la necessità di spostare grandi insiemi di dati attraverso le infrastrutture per affrontare i compiti aziendali.
-
I lavori Hadoop come MapReduce, Pig, Hive e Sqoop hanno flussi di lavoro.
Oozie
-
Oozie è un flusso di lavoro o un sistema di coordinamento che puoi usare per gestire i lavori Hadoop.
Il ciclo di vita dell’applicazione Oozie è mostrato nel diagramma sottostante.
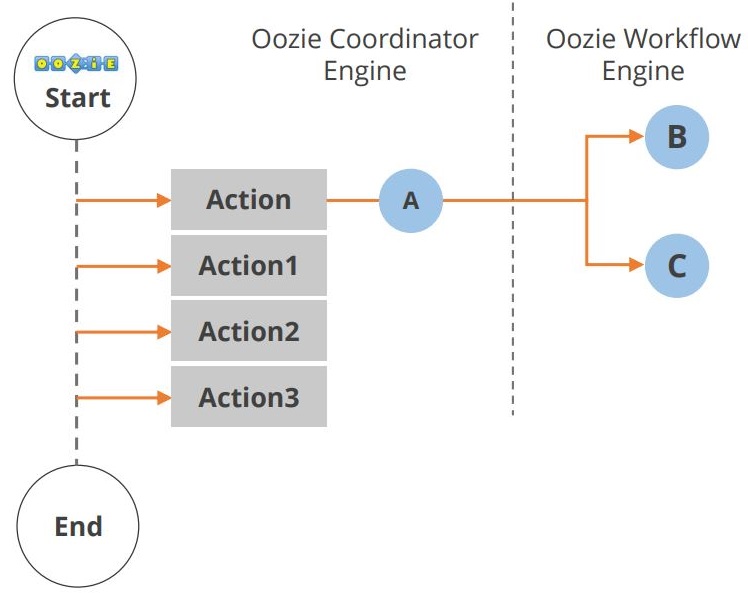 Come puoi vedere, tra l’inizio e la fine del flusso di lavoro avvengono più azioni. Un altro componente dell’ecosistema Hadoop è Hue. Guardiamo ora Hue.
Come puoi vedere, tra l’inizio e la fine del flusso di lavoro avvengono più azioni. Un altro componente dell’ecosistema Hadoop è Hue. Guardiamo ora Hue.
Hue
Hue è un acronimo per Hadoop User Experience. È un’interfaccia web open-source per Hadoop. Puoi eseguire le seguenti operazioni usando Hue:
-
Carica e sfoglia i dati
-
Cerca una tabella in HIVE e Impala
-
Esegui lavori e flussi di lavoro Spark e Pig Cerca dati
-
Tutto sommato, Hue rende Hadoop più facile da usare.
-
Fornisce anche un editor SQL per HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL, e Solr SQL.
Dopo questa breve panoramica dei dodici componenti dell’ecosistema Hadoop, discuteremo ora come questi componenti lavorano insieme per elaborare i Big Data.
Fasi dell’elaborazione dei Big Data
Ci sono quattro fasi di elaborazione dei Big Data: Ingest, Processing, Analyze, Access. Vediamole in dettaglio.
Ingestione
La prima fase dell’elaborazione dei Big Data è l’Ingest. I dati vengono ingeriti o trasferiti a Hadoop da varie fonti come database relazionali, sistemi o file locali. Sqoop trasferisce i dati da RDBMS a HDFS, mentre Flume trasferisce i dati degli eventi.
L’elaborazione
La seconda fase è l’elaborazione. In questa fase, i dati vengono memorizzati ed elaborati. I dati sono memorizzati nel file system distribuito, HDFS, e nei dati distribuiti NoSQL, HBase. Spark e MapReduce eseguono l’elaborazione dei dati.
Analyze
La terza fase è Analyze. Qui, i dati vengono analizzati da framework di elaborazione come Pig, Hive e Impala.
Pig converte i dati usando una mappa e riduce e poi li analizza. Anche Hive è basato sulla programmazione map and reduce ed è più adatto per i dati strutturati.
Access
La quarta fase è Access, che viene eseguita da strumenti come Hue e Cloudera Search. In questa fase, i dati analizzati possono essere accessibili agli utenti.
Hue è l’interfaccia web, mentre Cloudera Search fornisce un’interfaccia di testo per l’esplorazione dei dati.
Guarda qui il corso di certificazione Big Data Hadoop e Spark Developer!
Sommario
Riassumiamo ora ciò che abbiamo imparato in questa lezione.
-
Hadoop è un framework per lo stoccaggio e l’elaborazione distribuita.
-
I componenti principali di Hadoop includono HDFS per lo storage, YARN per la gestione delle risorse dei cluster, e MapReduce o Spark per l’elaborazione.
-
L’ecosistema Hadoop include più componenti che supportano ogni fase dell’elaborazione dei Big Data.
-
Flume e Sqoop ingeriscono i dati, HDFS e HBase memorizzano i dati, Spark e MapReduce elaborano i dati, Pig, Hive e Impala analizzano i dati, Hue e Cloudera Search aiutano ad esplorare i dati.
-
Oozie gestisce il flusso di lavoro di Hadoop.
Conclusione
Questo conclude la lezione sui Big Data e l’ecosistema Hadoop. Nella prossima lezione parleremo di HDFS e YARN.
Trova i nostri corsi di formazione online per sviluppatori di Big Data Hadoop e Spark nelle migliori città:
| Nome | Data | Luogo | |
|---|---|---|---|
| Sviluppatore Big Data Hadoop e Spark | 3 aprile -15 maggio 2021, Weekend batch | La tua città | Vedi i dettagli |
| Big Data Hadoop and Spark Developer | 12 Apr -4 May 2021, Weekdays batch | La tua città | Vedi dettagli |
| Sviluppatore Big Data Hadoop e Spark | 24 Apr -5 Giu 2021, Weekend batch | La tua città | Vedi dettagli |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Per saperne di più, segui il Corso
Big Data Hadoop and Spark Developer Certification Training
Vai al Corso
Per saperne di più, segui il corso
Formazione per la certificazione di sviluppatori Big Data Hadoop e Spark Vai al corso