VGG16 – Réseau convolutif pour la classification et la détection
VGG16 est un modèle de réseau neuronal convolutif proposé par K. Simonyan et A. Zisserman de l’Université d’Oxford dans l’article « Very Deep Convolutional Networks for Large-Scale Image Recognition ». Le modèle atteint une précision de 92,7 % dans le test top-5 d’ImageNet, qui est un ensemble de données de plus de 14 millions d’images appartenant à 1000 classes. C’est l’un des célèbres modèles soumis à l’ILSVRC-2014. Il améliore AlexNet en remplaçant les grands filtres à noyau (11 et 5 dans la première et la deuxième couche convolutive, respectivement) par de multiples filtres à noyau 3×3, l’un après l’autre. VGG16 a été entraîné pendant des semaines et utilisait des GPU NVIDIA Titan Black.
DataSet
ImageNet est un jeu de données de plus de 15 millions d’images haute résolution étiquetées appartenant à environ 22 000 catégories. Les images ont été collectées sur le Web et étiquetées par des étiqueteurs humains à l’aide de l’outil de crowd-sourcing Mechanical Turk d’Amazon. Depuis 2010, dans le cadre du Pascal Visual Object Challenge, une compétition annuelle appelée ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) est organisée. L’ILSVRC utilise un sous-ensemble d’ImageNet comprenant environ 1000 images dans chacune des 1000 catégories. Au total, il y a environ 1,2 million d’images d’entraînement, 50 000 images de validation et 150 000 images de test. ImageNet est composé d’images à résolution variable. Par conséquent, les images ont été sous-échantillonnées à une résolution fixe de 256×256. Étant donné une image rectangulaire, l’image est remise à l’échelle et recadre le patch central de 256×256 de l’image résultante.
L’architecture
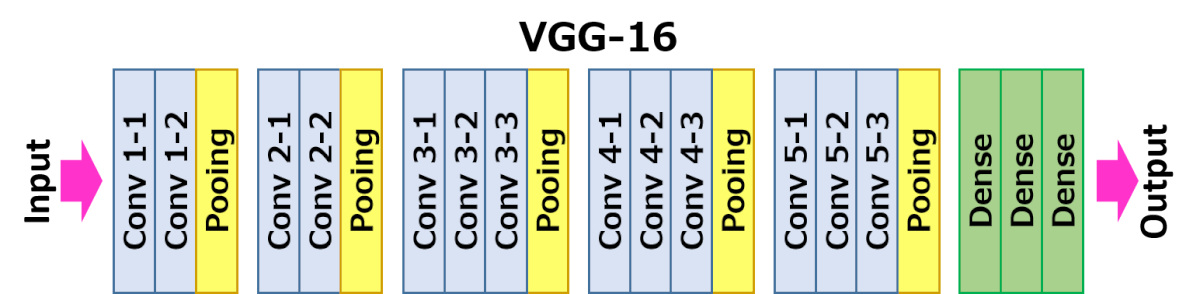
L’architecture représentée ci-dessous est VGG16.
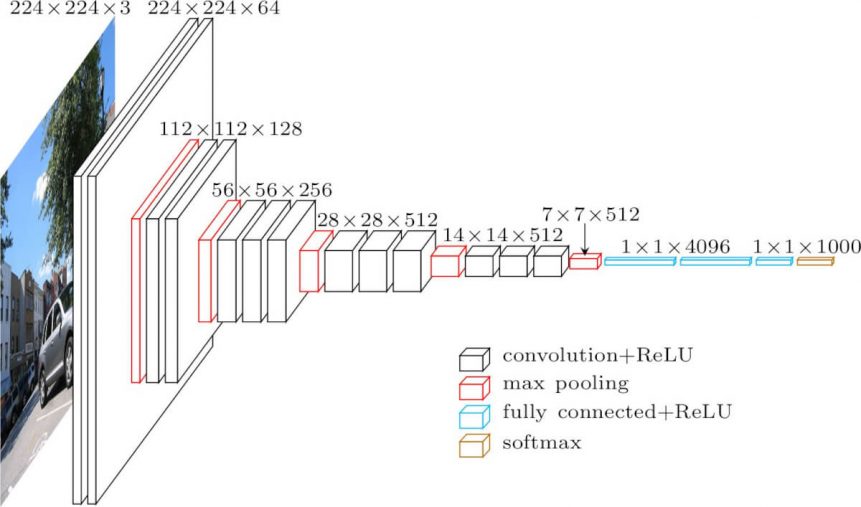
L’entrée de la couche cov1 est une image RVB de taille fixe 224 x 224. L’image passe par une pile de couches convolutionnelles (conv.), où les filtres ont été utilisés avec un champ réceptif très petit : 3×3 (qui est la plus petite taille pour capturer la notion de gauche/droite, haut/bas, centre). Dans l’une des configurations, il utilise également des filtres de convolution 1×1, qui peuvent être vus comme une transformation linéaire des canaux d’entrée (suivie d’une non-linéarité). Le pas de convolution est fixé à 1 pixel ; le remplissage spatial de l’entrée de la couche de convolution est tel que la résolution spatiale est préservée après convolution, c’est-à-dire que le remplissage est de 1 pixel pour les couches de convolution 3×3. La mise en commun spatiale est effectuée par cinq couches de max-pooling, qui suivent certaines des couches de convolution (toutes les couches de convolution ne sont pas suivies de max-pooling). Le max-pooling est effectué sur une fenêtre de 2×2 pixels, avec un stride de 2.
Trois couches entièrement connectées (FC) suivent une pile de couches convolutionnelles (qui a une profondeur différente dans différentes architectures) : les deux premières ont 4096 canaux chacune, la troisième effectue une classification ILSVRC à 1000 voies et contient donc 1000 canaux (un pour chaque classe). La dernière couche est la couche soft-max. La configuration des couches entièrement connectées est la même dans tous les réseaux.
Toutes les couches cachées sont équipées de la non-linéarité de rectification (ReLU). On note également qu’aucun des réseaux (sauf un) ne contient de normalisation de réponse locale (LRN), une telle normalisation n’améliore pas les performances sur le jeu de données ILSVRC, mais entraîne une augmentation de la consommation de mémoire et du temps de calcul.
Configurations
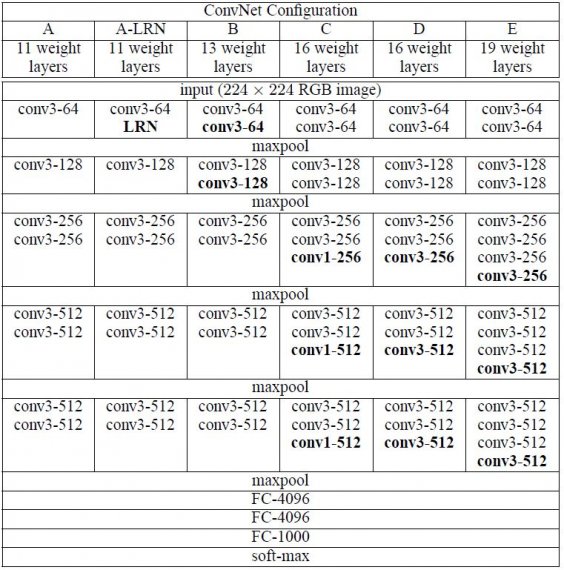
Les configurations des ConvNet sont décrites dans la figure 2. Les réseaux sont désignés par leur nom (A-E). Toutes les configurations suivent la conception générique présente dans l’architecture et ne diffèrent que par la profondeur : de 11 couches de poids dans le réseau A (8 couches conv. et 3 couches FC) à 19 couches de poids dans le réseau E (16 couches conv. et 3 couches FC). La largeur des couches conv. (le nombre de canaux) est plutôt petite, commençant par 64 dans la première couche et augmentant ensuite d’un facteur 2 après chaque couche de max-pooling, jusqu’à atteindre 512.
Cas d’utilisation et mise en œuvre
Malheureusement, il y a deux inconvénients majeurs avec VGGNet:
- Il est douloureusement lent à entraîner.
- Les poids de l’architecture du réseau eux-mêmes sont assez grands (concernant le disque/la bande passante).
En raison de sa profondeur et du nombre de nœuds entièrement connectés, VGG16 est plus de 533MB. Cela rend le déploiement de VGG une tâche fastidieuse.VGG16 est utilisé dans de nombreux problèmes de classification d’images par apprentissage profond ; cependant, des architectures de réseau plus petites sont souvent plus souhaitables (comme SqueezeNet, GoogLeNet, etc.). Mais c’est un excellent bloc de construction à des fins d’apprentissage car il est facile à mettre en œuvre.
Résultat
VGG16 surpasse significativement la génération précédente de modèles dans les compétitions ILSVRC-2012 et ILSVRC-2013. Le résultat de VGG16 est également en concurrence avec le gagnant de la tâche de classification (GoogLeNet avec 6,7 % d’erreur) et surpasse considérablement la soumission Clarifai, gagnante de l’ILSVRC-2013, qui a obtenu 11,2 % avec des données d’entraînement externes et 11,7 % sans. En ce qui concerne la performance du réseau unique, l’architecture VGG16 obtient le meilleur résultat (erreur de test de 7,0 %), surpassant un GoogLeNet unique de 0,9 %.
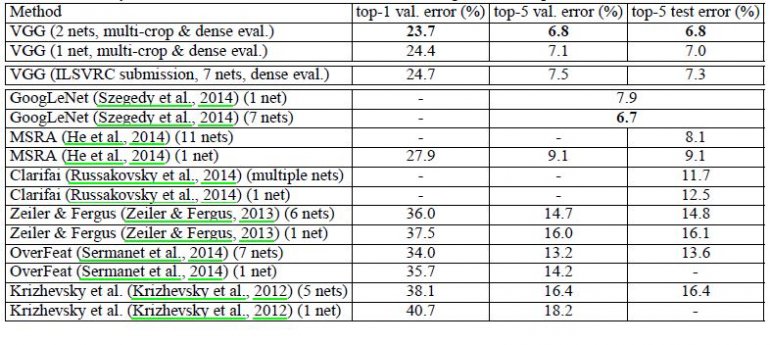
Il a été démontré que la profondeur de représentation est bénéfique pour la précision de la classification, et que la performance de pointe sur le jeu de données du défi ImageNet peut être obtenue en utilisant une architecture ConvNet conventionnelle avec une profondeur sensiblement accrue.