Utilisation de réseaux neuronaux convolutifs pour la reconnaissance d’images
Cet article a été initialement publié sur le site de Cadence. Il est reproduit ici avec l’autorisation de Cadence.
Les réseaux neuronaux convolutifs (CNN) sont largement utilisés dans les problèmes de reconnaissance de formes et d’images car ils présentent un certain nombre d’avantages par rapport aux autres techniques. Ce livre blanc couvre les bases des CNN, y compris une description des différentes couches utilisées. En utilisant la reconnaissance des panneaux de signalisation comme exemple, nous discutons des défis du problème général et nous présentons des algorithmes et un logiciel de mise en œuvre développés par Cadence qui peuvent compenser la charge de calcul et l’énergie pour une dégradation modeste des taux de reconnaissance des panneaux. Nous soulignons les défis de l’utilisation des CNN dans les systèmes embarqués et présentons les caractéristiques clés du processeur de signal numérique (DSP) Cadence® Tensilica® Vision P5 pour l’imagerie et la vision par ordinateur et du logiciel qui le rendent si approprié pour les applications CNN à travers de nombreuses tâches d’imagerie et de reconnaissance connexes.
Qu’est-ce qu’un CNN?
Un réseau neuronal est un système de « neurones » artificiels interconnectés qui échangent des messages entre eux. Les connexions ont des poids numériques qui sont réglés pendant le processus de formation, de sorte qu’un réseau correctement formé répondra correctement lorsqu’on lui présentera une image ou un motif à reconnaître. Le réseau se compose de plusieurs couches de « neurones » de détection des caractéristiques. Chaque couche comporte de nombreux neurones qui répondent à différentes combinaisons d’entrées provenant des couches précédentes. Comme le montre la figure 1, les couches sont construites de telle sorte que la première couche détecte un ensemble de motifs primitifs dans l’entrée, la deuxième couche détecte des motifs de motifs, la troisième couche détecte des motifs de ces motifs, et ainsi de suite. Les CNN typiques utilisent 5 à 25 couches distinctes de reconnaissance de motifs.
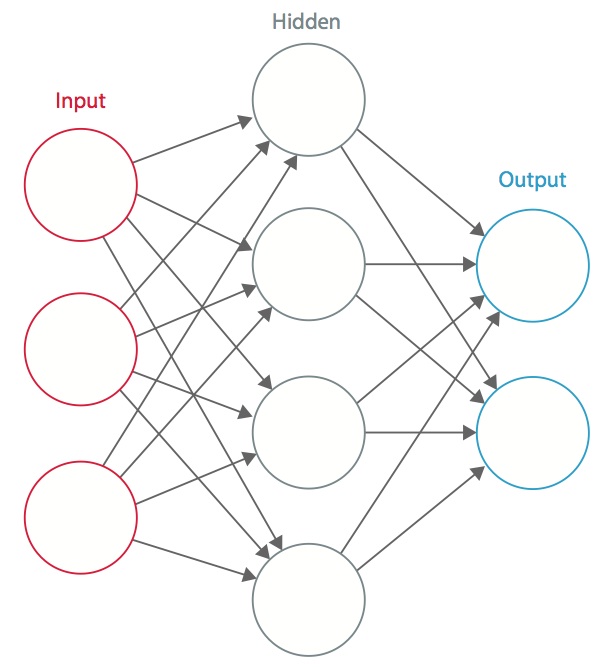
Figure 1 : Un réseau neuronal artificiel
L’entraînement est effectué à l’aide d’un ensemble de données « étiquetées » d’entrées dans un large assortiment de motifs d’entrée représentatifs qui sont étiquetés avec leur réponse de sortie prévue. La formation utilise des méthodes générales pour déterminer de manière itérative les poids des neurones de caractéristiques intermédiaires et finales. La figure 2 démontre le processus de formation au niveau des blocs.
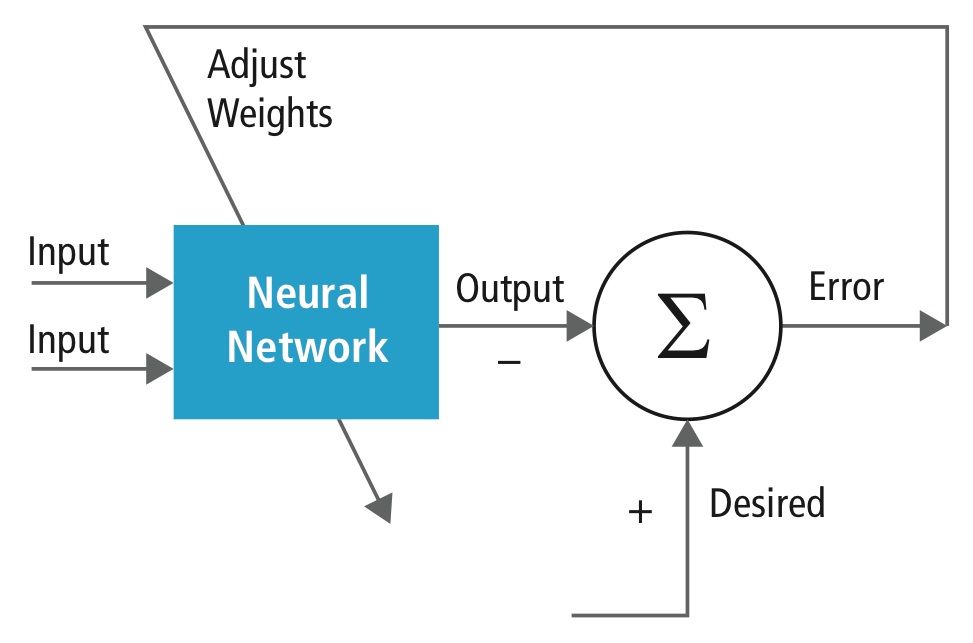
Figure 2 : Formation des réseaux neuronaux
Les réseaux neuronaux sont inspirés des systèmes neuronaux biologiques. L’unité de calcul de base du cerveau est un neurone et ils sont connectés par des synapses. La figure 3 compare un neurone biologique à un modèle mathématique de base .


Figure 3 : Illustration d’un neurone biologique (en haut) et de son modèle mathématique (en bas)
Dans un système neuronal animal réel, un neurone est perçu comme recevant des signaux d’entrée de ses dendrites et produisant des signaux de sortie le long de son axone. L’axone se ramifie et se connecte via des synapses aux dendrites d’autres neurones. Lorsque la combinaison des signaux d’entrée atteint une certaine condition de seuil parmi ses dendrites d’entrée, le neurone est déclenché et son activation est communiquée aux neurones successeurs.
Dans le modèle de calcul du réseau neuronal, les signaux qui se déplacent le long des axones (par exemple, x0) interagissent de manière multiplicative (par exemple, w0x0) avec les dendrites de l’autre neurone en fonction de la force synaptique à cette synapse (par exemple, w0). Les poids synaptiques peuvent être appris et contrôlent l’influence d’un neurone ou d’un autre. Les dendrites transportent le signal jusqu’au corps cellulaire, où ils sont tous additionnés. Si la somme finale est supérieure à un seuil donné, le neurone se déclenche, envoyant un pic le long de son axone. Dans le modèle de calcul, on suppose que le moment précis de la mise à feu n’a pas d’importance et que seule la fréquence de la mise à feu communique l’information. Sur la base de l’interprétation du code de taux, le taux de tir du neurone est modélisé par une fonction d’activation ƒ qui représente la fréquence des spikes le long de l’axone. Un choix courant de fonction d’activation est sigmoïde. En résumé, chaque neurone calcule le produit scalaire des entrées et des poids, ajoute le biais et applique la non-linéarité comme fonction de déclenchement (par exemple, en suivant une fonction de réponse sigmoïde).
Un CNN est un cas particulier du réseau neuronal décrit ci-dessus. Un CNN est constitué d’une ou plusieurs couches convolutionnelles, souvent avec une couche de sous-échantillonnage, qui sont suivies d’une ou plusieurs couches entièrement connectées comme dans un réseau de neurones standard.
La conception d’un CNN est motivée par la découverte d’un mécanisme visuel, le cortex visuel, dans le cerveau. Le cortex visuel contient de nombreuses cellules chargées de détecter la lumière dans de petites sous-régions du champ visuel qui se chevauchent, appelées champs réceptifs. Ces cellules agissent comme des filtres locaux sur l’espace d’entrée, et les cellules plus complexes ont des champs réceptifs plus grands. La couche de convolution dans un CNN exécute la fonction qui est exécutée par les cellules du cortex visuel .
Un CNN typique pour reconnaître les panneaux de signalisation est illustré à la figure 4. Chaque caractéristique d’une couche reçoit des entrées d’un ensemble de caractéristiques situées dans un petit voisinage dans la couche précédente, appelé champ réceptif local. Grâce aux champs réceptifs locaux, les caractéristiques peuvent extraire des caractéristiques visuelles élémentaires, telles que des bords orientés, des points d’extrémité, des coins, etc. qui sont ensuite combinés par les couches supérieures.
Dans le modèle traditionnel de reconnaissance des formes et des images, un extracteur de caractéristiques conçu à la main rassemble les informations pertinentes de l’entrée et élimine les variabilités non pertinentes. L’extracteur est suivi par un classificateur entraînable, un réseau neuronal standard qui classe les vecteurs de caractéristiques dans des classes.
Dans un CNN, les couches de convolution jouent le rôle d’extracteur de caractéristiques. Mais elles ne sont pas conçues à la main. Les poids des noyaux des filtres de convolution sont décidés dans le cadre du processus de formation. Les couches convolutionnelles sont capables d’extraire les caractéristiques locales parce qu’elles limitent les champs réceptifs des couches cachées à être locaux.
Figure 4 : Schéma fonctionnel typique d’un CNN
Les CNN sont utilisés dans divers domaines, notamment la reconnaissance d’images et de formes, la reconnaissance vocale, le traitement du langage naturel et l’analyse vidéo. L’importance des réseaux de neurones convolutifs s’explique par plusieurs raisons. Dans les modèles traditionnels de reconnaissance des formes, les extracteurs de caractéristiques sont conçus à la main. Dans les réseaux neuronaux convolutionnels, les poids de la couche convolutionnelle utilisée pour l’extraction des caractéristiques et de la couche entièrement connectée utilisée pour la classification sont déterminés pendant le processus de formation. Les structures de réseau améliorées des CNN permettent d’économiser les exigences de mémoire et de complexité de calcul et, en même temps, donnent de meilleures performances pour les applications où l’entrée a une corrélation locale (par exemple, l’image et la parole).
Les grandes exigences de ressources informatiques pour l’entraînement et l’évaluation des CNN sont parfois satisfaites par des unités de traitement graphique (GPU), des DSP, ou d’autres architectures de silicium optimisées pour un haut débit et une faible énergie lors de l’exécution des modèles idiosyncratiques de calcul CNN. En fait, les processeurs avancés tels que le DSP Tensilica Vision P5 pour l’imagerie et la vision par ordinateur de Cadence disposent d’un ensemble presque idéal de ressources de calcul et de mémoire nécessaires à l’exécution de CNN à haut rendement.
Dans les applications de reconnaissance des formes et des images, les meilleurs taux de détection correcte (CDR) possibles ont été obtenus en utilisant des CNN. Par exemple, les CNN ont atteint un CDR de 99,77% en utilisant la base de données MNIST de chiffres manuscrits , un CDR de 97,47% avec le jeu de données NORB d’objets 3D , et un CDR de 97,6% sur ~5600 images de plus de 10 objets . Les CNN ne donnent pas seulement les meilleures performances par rapport aux autres algorithmes de détection, ils surpassent même les humains dans des cas tels que la classification d’objets dans des catégories à grain fin, comme la race particulière de chien ou l’espèce d’oiseau .
La figure 5 montre un pipeline typique d’algorithmes de vision, qui comprend quatre étapes : le prétraitement de l’image, la détection des régions d’intérêt (ROI) qui contiennent des objets probables, la reconnaissance des objets et la prise de décision en matière de vision. L’étape de prétraitement dépend généralement des détails de l’entrée, notamment du système de caméra, et est souvent mise en œuvre dans une unité câblée en dehors du sous-système de vision. La prise de décision à la fin du pipeline opère généralement sur des objets reconnus – elle peut prendre des décisions complexes, mais elle opère sur beaucoup moins de données, de sorte que ces décisions ne sont généralement pas des problèmes difficiles à calculer ou gourmands en mémoire. Le grand défi est dans les étapes de détection et de reconnaissance d’objets, où les CNN ont maintenant un large impact.

Figure 5 : Pipeline d’algorithmes de vision
Couches de CNN
En empilant des couches multiples et différentes dans un CNN, des architectures complexes sont construites pour les problèmes de classification. Quatre types de couches sont les plus courants : les couches de convolution, les couches de mise en commun/sous-échantillonnage, les couches non linéaires et les couches entièrement connectées.
Couches de convolution
L’opération de convolution extrait différentes caractéristiques de l’entrée. La première couche de convolution extrait les caractéristiques de bas niveau comme les bords, les lignes et les coins. Les couches de niveau supérieur extraient des caractéristiques de plus haut niveau. La figure 6 illustre le processus de convolution 3D utilisé dans les CNN. L’entrée est de taille N x N x D et est convoluée avec H noyaux, chacun de
taille k x k x D séparément. La convolution d’une entrée avec un noyau produit une caractéristique de sortie, et avec H noyaux indépendamment produit H caractéristiques. En partant du coin supérieur gauche de l’entrée, chaque noyau est déplacé de gauche à droite, un élément à la fois. Une fois le coin supérieur droit atteint, le noyau est déplacé d’un élément vers le bas, et de nouveau le noyau est déplacé de gauche à droite, un élément à la fois. Ce processus est répété jusqu’à ce que
le noyau atteigne le coin inférieur droit. Dans le cas où N = 32 et k = 5 , il existe 28 positions uniques de gauche à droite et 28 positions uniques de haut en bas que le noyau peut prendre. En fonction de ces positions, chaque caractéristique de la sortie contiendra 28×28 (c’est-à-dire (N-k+1) x (N-k+1)) éléments. Pour chaque position du noyau dans un processus de fenêtre glissante, k x k x D éléments de l’entrée et k x k x D éléments du noyau sont multipliés et accumulés élément par élément. Ainsi, pour créer un élément d’une caractéristique de sortie, k x k x D opérations de multiplication-accumulation sont nécessaires.
Figure 6 : Représentation imagée du processus de convolution
Couches de regroupement/sous-échantillonnage
La couche de regroupement/sous-échantillonnage réduit la résolution des caractéristiques. Elle rend les caractéristiques robustes contre le bruit et la distorsion. Il existe deux façons de faire du pooling : le pooling max et le pooling moyen. Dans les deux cas, l’entrée est divisée en espaces bidimensionnels non chevauchants. Par exemple, dans la figure 4, la couche 2 est la couche de mise en commun. Chaque caractéristique d’entrée est de 28×28 et est divisée en 14×14 régions de taille 2×2. Pour la mise en commun moyenne, la moyenne des quatre valeurs de la région est calculée. Pour le pooling max, la valeur maximale des quatre valeurs est sélectionnée.
La figure 7 développe davantage le processus de pooling. L’entrée est de taille 4×4. Pour le sous-échantillonnage 2×2, une image 4×4 est divisée en quatre matrices non superposées de taille 2×2. Dans le cas d’une mise en commun maximale, la valeur maximale des quatre valeurs de la matrice 2×2 constitue la sortie. Dans le cas d’une mise en commun moyenne, la moyenne des quatre valeurs est la sortie. Veuillez noter que pour la sortie avec l’indice (2,2), le résultat du calcul de la moyenne est une fraction qui a été arrondie au nombre entier le plus proche.
Figure 7 : Représentation picturale de la mise en commun maximale et de la mise en commun moyenne
Couches non linéaires
Les réseaux neuronaux en général et les CNN en particulier reposent sur une fonction de « déclenchement » non linéaire pour signaler l’identification distincte de caractéristiques probables sur chaque couche cachée. Les CNN peuvent utiliser une variété de fonctions spécifiques – telles que les unités linéaires rectifiées (ReLU) et les fonctions de déclenchement continues (non linéaires) – pour mettre en œuvre efficacement ce déclenchement non linéaire.
ReLU
Un ReLU met en œuvre la fonction y = max(x,0), de sorte que les tailles d’entrée et de sortie de cette couche sont les mêmes. Il augmente les propriétés non linéaires de la fonction de décision et du réseau global sans affecter les champs réceptifs de la couche de convolution. Par rapport aux autres fonctions non linéaires utilisées dans les CNN (par exemple, la tangente hyperbolique, l’absolu de la tangente hyperbolique et la sigmoïde), l’avantage d’une ReLU est que le réseau s’entraîne beaucoup plus rapidement. La fonctionnalité ReLU est illustrée à la figure 8, avec sa fonction de transfert tracée au-dessus de la flèche.
Figure 8 : Représentation picturale de la fonctionnalité ReLU
Fonction de déclenchement continue (non linéaire)
La couche non linéaire opère élément par élément dans chaque caractéristique. Une fonction de déclenchement continue peut être la tangente hyperbolique (figure 9), l’absolu de la tangente hyperbolique (figure 10) ou la sigmoïde (figure 11). La figure 12 montre comment la non-linéarité est appliquée élément par élément.
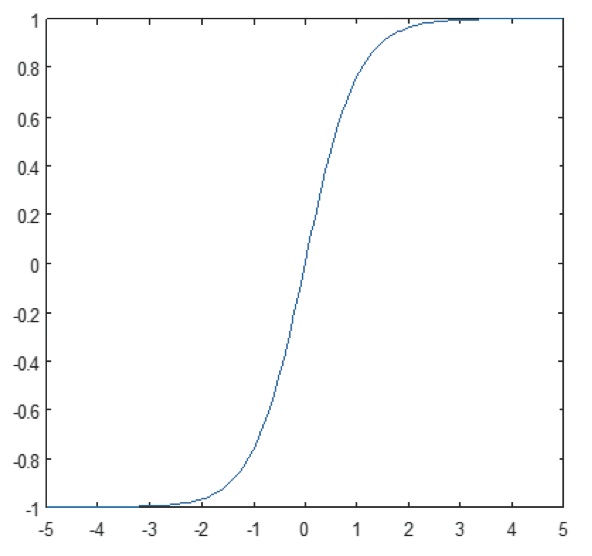
Figure 9 : Tracé de la fonction tangente hyperbolique
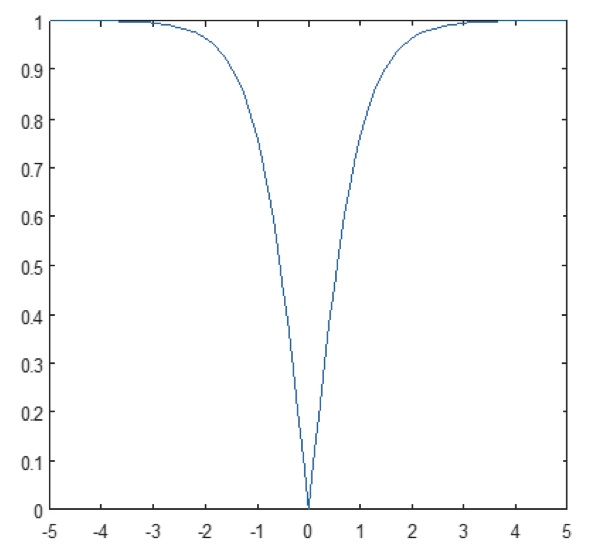
Figure 10 : Tracé de l’absolu de la fonction tangente hyperbolique
Figure 11 : Tracé de la fonction sigmoïde
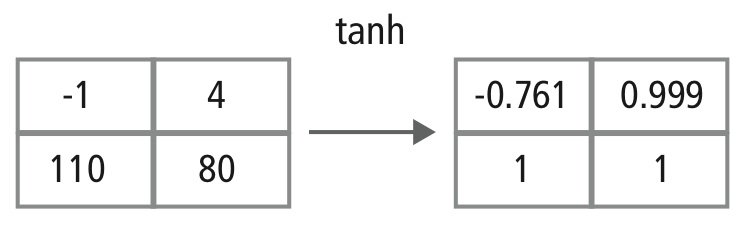
Figure 12 : Représentation picturale du traitement tanh
Couches entièrement connectées
Les couches entièrement connectées sont souvent utilisées comme couches finales d’un CNN. Ces couches additionnent mathématiquement une pondération de la couche précédente de caractéristiques, indiquant le mélange précis des « ingrédients » pour déterminer un résultat de sortie cible spécifique. Dans le cas d’une couche entièrement connectée, tous les éléments de toutes les caractéristiques de la couche précédente sont utilisés dans le calcul de chaque élément de chaque caractéristique de sortie.
La figure 13 explique la couche entièrement connectée L. La couche L-1 a deux caractéristiques, chacune étant 2×2, c’est-à-dire ayant quatre éléments. La couche L a deux caractéristiques, chacune ayant un seul élément.
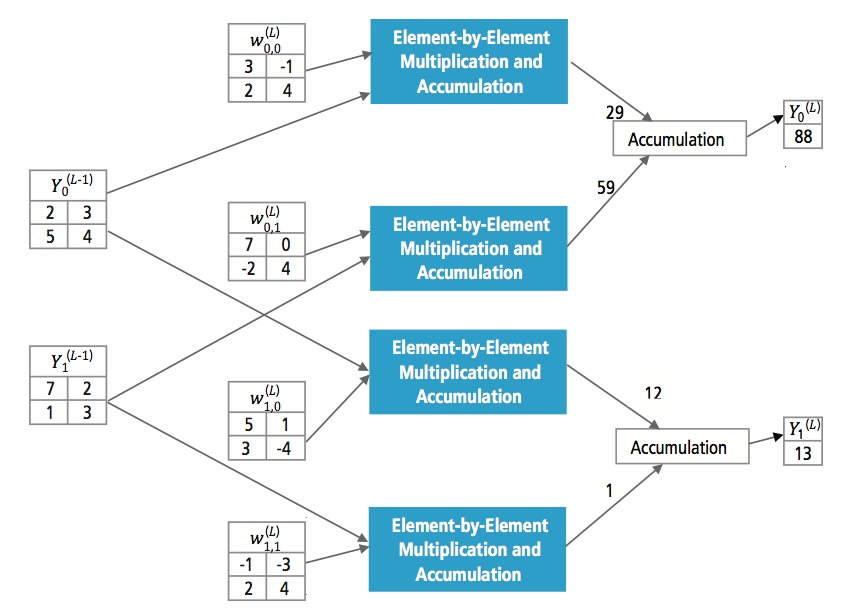
Figure 13 : Traitement d’une couche entièrement connectée
Pourquoi CNN?
Bien que les réseaux neuronaux et d’autres méthodes de détection de motifs existent depuis 50 ans, il y a eu un développement significatif dans le domaine des réseaux neuronaux convolutifs dans le passé récent. Cette section couvre les avantages de l’utilisation du CNN pour la reconnaissance d’images.
Résistance aux décalages et aux distorsions de l’image
La détection utilisant le CNN est résistante aux distorsions telles que le changement de forme dû à l’objectif de la caméra, aux différentes condi- tions d’éclairage, aux différentes poses, à la présence d’occlusions partielles, aux décalages horizontaux et verticaux, etc. Cependant, les CNN sont invariants par rapport au décalage puisque la même configuration de poids est utilisée dans tout l’espace. En théorie, nous pouvons également obtenir une invariance de décalage en utilisant des couches entièrement connectées. Mais dans ce cas, le résultat de la formation est une multitude d’unités avec des configurations de poids identiques à différents endroits de l’entrée. Pour apprendre ces configurations de poids, un grand nombre d’instances d’entraînement serait nécessaire pour couvrir l’espace des variations possibles.
Moins de besoins en mémoire
Dans ce même cas hypothétique où nous utilisons une couche entièrement connectée pour extraire les caractéristiques, l’image d’entrée de taille 32×32 et une couche cachée ayant 1000 caractéristiques nécessiteront un ordre de 106 coefficients, un énorme besoin en mémoire. Dans la couche convolutionnelle, les mêmes coefficients sont utilisés à travers différents emplacements dans l’espace, donc l’exigence de mémoire est drastiquement réduite.
Facile et meilleure formation
En utilisant le réseau neuronal standard qui serait équivalent à un CNN, parce que le nombre de param- etres serait beaucoup plus élevé, le temps de formation augmenterait aussi proportionnellement. Dans un CNN, comme le nombre de paramètres est considérablement réduit, le temps de formation est proportionnellement réduit. De plus, en supposant une formation parfaite, nous pouvons concevoir un réseau neuronal standard dont les performances seraient identiques à celles d’un CNN. Mais dans la formation pratique,
un réseau neuronal standard équivalent à un CNN aurait plus de paramètres, ce qui entraînerait l’ajout de plus de bruit pendant le processus de formation. Par conséquent, les performances d’un réseau neuronal standard équivalent à un CNN seront toujours moins bonnes.
Algorithme de reconnaissance pour le jeu de données GTSRB
Le German Traffic Sign Recognition Benchmark (GTSRB) était un défi de classification multi-classes, à image unique, organisé lors de la Conférence internationale conjointe sur les réseaux neuronaux (IJCNN) 2011, avec les exigences suivantes :
- 51 840 images de panneaux routiers allemands dans 43 classes (figures 14 et 15)
- La taille des images varie de 15×15 à 222×193
- Les images sont regroupées par classe et par piste avec au moins 30 images par piste
- Les images sont disponibles sous forme d’images couleur (RVB), de caractéristiques HOG, de caractéristiques Haar et d’histogrammes de couleur
- La compétition porte uniquement sur l’algorithme de classification ; L’algorithme pour trouver la région d’intérêt dans l’image n’est pas nécessaire
- L’information temporelle des séquences de test n’est pas partagée, donc la dimension temporelle ne peut pas être utilisée dans l’algorithme de classification

Figure 14 : Panneaux de signalisation idéaux du GTSRB

Figure 15 : Panneaux de signalisation du GTSRB avec dégradations
Algorithme Cadence pour la reconnaissance des panneaux de signalisation dans l’ensemble de données du GTSRB
Cadence a développé divers algorithmes dans MATLAB pour la reconnaissance des panneaux de signalisation en utilisant l’ensemble de données du GTSRB, en commençant par une configuration de base basée sur un article bien connu sur la reconnaissance des panneaux . Le taux de détection correct de 99,24 % et l’effort de calcul de près de >50 millions d’additions multiples par panneau sont représentés par un point vert épais dans la figure 16. Cadence a obtenu des résultats nettement meilleurs en utilisant notre nouvelle approche propriétaire CNN hiérarchique. Dans cet algorithme, 43 panneaux de signalisation ont été divisés en cinq familles. Au total, nous mettons en œuvre six CNN plus petits. Le premier CNN décide de la famille à laquelle appartient le panneau de signalisation reçu. Une fois que la famille du panneau est connue, le CNN (l’un des cinq restants) correspondant à la famille détectée est exécuté pour décider du panneau de signalisation au sein de cette famille. En utilisant cet algorithme, Cadence a obtenu un taux de détection correct de 99,58%, le meilleur CDR obtenu sur GTSRB à ce jour.
Algorithme pour le compromis performance vs complexité
Afin de contrôler la complexité des CNN dans les applications embarquées, Cadence a également développé un algorithme propriétaire utilisant la décomposition en valeurs propres qui réduit un CNN entraîné à sa dimension canonique. En utilisant cet algorithme, nous avons été en mesure de réduire drastiquement la complexité du CNN sans aucune dégra- dation des performances, ou avec une petite réduction contrôlée du CDR. La figure 16 montre les résultats obtenus :
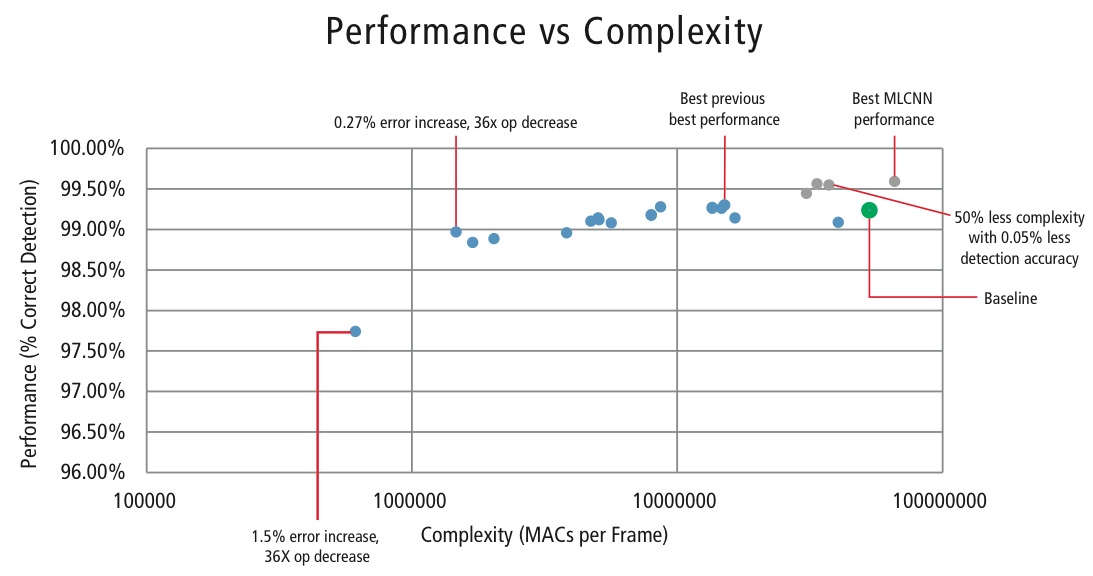
Figure 16 : Tracé de la performance par rapport à la complexité pour différentes configurations CNN pour détecter les panneaux de signalisation dans le jeu de données GTSRB
Le point vert dans la figure 16 est la configuration de base. Cette configuration est assez proche de la configuration suggérée dans la référence . Elle nécessite 53 MMACs par trame pour un taux d’erreur de 0,76%.
- Le deuxième point à partir de la gauche nécessite 1,47 million de MACs par trame pour un taux d’erreur de 1,03%, c’est-à-dire, pour une augmentation du taux d’erreur de 0,27%, le besoin en MAC a été réduit par un facteur de 36,14.
- Le point le plus à gauche nécessite 0,61 MMACs par trame pour atteindre un taux d’erreur de 2,26%, c’est-à-dire que le nombre de MACs est réduit par un facteur de 86,4 fois.
- Les points en bleu sont pour un CNN à un seul niveau, tandis que les points en rouge sont pour un CNN hiérarchique. Une performance de 99,58 % dans le meilleur des cas est obtenue par le CNN hiérarchique.
CNNs in Embedded Systems
Comme le montre la figure 5, un sous-système de vision nécessite beaucoup de traitement d’image en plus d’un CNN. Afin d’exécuter des CNN sur un système embarqué à alimentation limitée qui prend en charge le traitement d’images, il doit remplir les conditions suivantes :
- Disponibilité de hautes performances de calcul : Pour une mise en œuvre typique de CNN, des milliards de MAC par seconde sont nécessaires.
- La largeur de bande de chargement/stockage plus importante : Dans le cas d’une couche entièrement connectée utilisée à des fins de classification, chaque coefficient est utilisé dans la multiplication une seule fois. Ainsi, l’exigence de bande passante charge-stockage est plus grande que le nombre de MAC effectués par le processeur.
- Faible exigence de puissance dynamique : Le système doit consommer moins d’énergie. Pour résoudre ce problème, une mise en œuvre en virgule fixe est nécessaire, ce qui impose de répondre aux exigences de performance en utilisant le nombre fini de bits le plus faible possible.
- Flexibilité : Il devrait être possible de mettre facilement à niveau la conception existante vers une nouvelle conception plus performante.
Comme les ressources de calcul sont toujours une contrainte dans les systèmes embarqués, si le cas d’utilisation permet une petite dégra- dation de la performance, il est utile d’avoir un algorithme qui peut réaliser d’énormes économies dans la complexité de calcul au prix d’une petite dégradation contrôlée de la performance. Ainsi, le travail de Cadence sur un algorithme permettant d’obtenir un compromis entre complexité et performance, comme expliqué dans la section précédente, est très pertinent pour la mise en œuvre de CNN sur des systèmes embarqués.
CNNs sur les processeurs Tensilica
Le DSP Tensilica Vision P5 est un DSP à haute performance et à faible puissance spécifiquement conçu pour le traitement de l’image et de la vision par ordinateur. Le DSP a une architecture VLIW avec un support SIMD. Il dispose de cinq emplacements d’émission dans un mot d’instruction allant jusqu’à 96 bits et peut charger jusqu’à 1024 bits de mots de mémoire à chaque cycle. Les registres internes et les unités d’opération vont de 512 bits à 1536 bits, où les données sont représentées comme 16, 32 ou 64 tranches de données de 8b, 16b, 24b, 32b ou 48b pixels.
Le DSP répond à tous les défis pour la mise en œuvre des CNN dans les systèmes embarqués, comme discuté dans la section précédente.
- Disponibilité de hautes performances de calcul : En plus du support avancé pour la mise en œuvre du traitement du signal d’image, le DSP dispose d’un support d’instructions pour toutes les étapes des CNN. Pour les opérations de convolution, il dispose d’un jeu d’instructions très riche prenant en charge les opérations de multiplication/multiplication-accumulation supportant les opérations 8b x 8b, 8b x 16b et 16b x 16b pour les données signées/non signées. Il peut effectuer jusqu’à 64 opérations de multiplication/multiplication-accumulation 8b x 16b et 8b x 8b en un cycle et 32 opérations de multiplication/multiplication-accumulation 16b x 16b en un cycle. Pour la mise en commun maximale et la fonctionnalité ReLU, le DSP a des instructions pour effectuer 64 comparaisons de 8 bits en un cycle. Pour implémenter des fonctions non linéaires avec des plages finies comme tanh et signum, il a des instructions pour implémenter une table de recherche pour 64 valeurs de 7 bits en un cycle. Dans la plupart des cas, les instructions de comparaison et de table de consultation sont programmées en parallèle avec les instructions de multiplication/multiplication-accumulation et ne prennent pas de cycles supplémentaires.
- La bande passante de chargement/stockage plus importante : le DSP peut effectuer jusqu’à deux opérations de chargement/stockage de 512 bits par cycle.
- La faible puissance dynamique requise : Le DSP est une machine à virgule fixe. En raison de la manipulation flexible d’une variété de types de données, la pleine performance et l’avantage énergétique du calcul mixte 16b et 8b peuvent être atteints avec une perte minimale de précision.
- Flexibilité : Le DSP étant un processeur programmable, le système peut être mis à niveau vers une nouvelle version simplement en effectuant une mise à niveau du micrologiciel.
- Point flottant : Pour les algorithmes nécessitant une plage dynamique étendue pour leurs données et/ou leurs coefficients, le DSP dispose d’une unité vectorielle à virgule flottante en option.
Le DSP Vision P5 est livré avec un ensemble complet d’outils logiciels qui comprend un compilateur C/C++ haute performance avec vectorisation et ordonnancement automatiques pour prendre en charge l’architecture SIMD et VLIW sans avoir à écrire de langage d’assemblage. Ce jeu d’outils complet comprend également un éditeur de liens, un assembleur, un débogueur, un profileur et des outils de visualisation graphique. Un simulateur de jeu d’instructions (ISS) complet permet au concepteur de simuler et d’évaluer rapidement les performances. Lorsque vous travaillez avec de grands systèmes ou de longs vecteurs de test, l’option de simulateur rapide et fonctionnel TurboXim atteint des vitesses de 40 à 80 fois supérieures à celles de l’ISS pour un développement logiciel et une vérification fonctionnelle efficaces.
Cadence a mis en œuvre une architecture à couche unique CNN sur le DSP pour la reconnaissance des panneaux de signalisation allemands. Cadence a obtenu un CDR de 99,403% avec une quantification de 16 bits pour les échantillons de données et une quantification de 8 bits pour les coefficients dans toutes les couches pour cette architecture. Elle comporte deux couches de convolution, trois couches entièrement connectées, quatre couches ReLU, trois couches de regroupement max et une couche non linéaire tanh. Cadence a atteint une performance de 38,58 MACs/cycle en moyenne pour le réseau complet, y compris les cycles pour toutes les couches max pooling, tanh et ReLU. Dans le meilleur des cas, Cadence a obtenu une performance de 58,43 MAC par cycle pour la troisième couche, y compris les cycles pour les fonctionnalités tanh et ReLU. Ce DSP fonctionnant à 600MHz peut traiter plus de 850 panneaux de signalisation en une seconde.
Le futur des CNN
Parmi les domaines prometteurs de la recherche sur les réseaux neuronaux, on trouve les réseaux neuronaux récurrents (RNN) utilisant la mémoire à long court terme (LSTM). Ces domaines fournissent l’état actuel de l’art dans les tâches de reconnaissance de séries temporelles comme la reconnaissance de la parole et de l’écriture manuscrite. Les RNN/auto-codeurs sont également capables de générer des images d’écriture manuscrite/de parole avec une certaine distribution connue ,,,,.
Les réseaux de croyance profonds, un autre type de réseau prometteur utilisant des machines de Boltzman restreintes (RMB)/auto-codeurs, sont capables d’être entraînés de manière avide, une couche à la fois, et sont donc plus facilement entraînables pour les réseaux très profonds ,.
Conclusion
LesCNN donnent les meilleures performances dans les problèmes de reconnaissance de formes/image et surpassent même les humains dans certains cas. Cadence a obtenu les meilleurs résultats de l’industrie en utilisant des algorithmes et des architectures propriétaires avec les CNN. Nous avons développé des CNNs hiérarchiques pour la reconnaissance des panneaux de signalisation dans le GTSRB, atteignant la meilleure performance jamais obtenue sur ce jeu de données. Nous avons développé un autre algorithme pour le compromis performance versus complexité et avons pu obtenir une réduction de la complexité d’un facteur 86 pour une dégradation du CDR de moins de 2%. Le DSP Tensilica Vision P5 pour l’imagerie et la vision par ordinateur de Cadence possède toutes les caractéristiques nécessaires à l’implémentation de CNNs en plus des caractéristiques nécessaires au traitement du signal d’image. Plus de 850 reconnaissances de panneaux de signalisation peuvent être effectuées en utilisant le DSP à 600 MHz. Le DSP Tensilica Vision P5 de Cadence possède un ensemble de caractéristiques presque idéal pour exécuter des CNN.
« Réseau neuronal artificiel. » Wikipédia. https://en.wikipedia.org/wiki/Artificial_neural_network
Karpathy, Andrej. 2015. « Réseaux neuronaux partie 1 : mise en place de l’architecture ». Notes pour CS231n Réseaux neuronaux convolutifs pour la reconnaissance visuelle, Université de Stanford. http://cs231n.github.io/neural-networks-1/
« Réseau neuronal convolutif. » Wikipédia. https://en.wikipedia.org/wiki/Convolutional_neural_network
Sermanet, Pierre, et Yann LeCun. 2011. « Reconnaissance de panneaux de signalisation avec des réseaux multi-échelles ». Institut Courant des sciences mathématiques, Université de New York. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6033589
Ciresan, Dan, Ueli Meier, et Jürgen Schmidhuber. 2012. « Réseaux neuronaux profonds multi-colonnes pour la classi- fication d’images ». 2012 IEEE Conference on Computer Vision and Pattern Recognition (New York, NY : Institute of Electrical and Electronics Engineers (IEEE)). http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6248110
Ciresan, Dan, Ueli Meier, Jonathan Masci, Luca M. Gambardella, et Jurgen Schmidhuber. 2011. « Réseaux neuronaux convolutifs flexibles et haute performance pour la classification d’images ». Actes de la vingt-deuxième conférence internationale conjointe sur l’intelligence artificielle – volume deux : 1237-1242. Consulté le 17 novembre 2013. http://people.idsia.ch/~juergen/ijcai2011.pdf
Lawrence, Steve, C. Lee Giles, Ah Chung Tsoi, et Andrew D. Back. 1997. » Reconnaissance des visages : A Convolutional Neural Network Approach ». IEEE Transactions on Neural Networks, volume 8 ; numéro 1. http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=554195
Russakovsky, O. et al. 2014. « Défi de reconnaissance visuelle à grande échelle ImageNet ». International Journal of Computer Vision. http://link.springer.com/article/10.1007/s11263-015-0816-y#
Ovtcharov, Kalin, Olatunji Ruwarse, Joo-Young Kim et al. 22 février 2015. « Accélération des réseaux convolutifs profonds à l’aide de matériel spécialisé ». Microsoft Research. http://research-srv.microsoft.com/pubs/240715/CNN%20Whitepaper.pdf
Stallkamp, J., M. Schlipsing, J. Salmen, et C. Igel. » Man Vs. Computer : Benchmarking Machine Learning Algorithms For Traffic Sign Application ». IJCNN 2011. http://www.sciencedirect.com/science/article/pii/S0893608012000457
Hochreiter, Sepp, et Jürgen Schmidhuber. 1997. « Mémoire à long terme à court terme ». Neural Computation, 9(8):1735-1780. ftp://ftp.idsia.ch/pub/juergen/lstm.pdf
Graves, Alex. 2014. « Générer des séquences avec des réseaux neuronaux récurrents ». http://arxiv.org/abs/1308.0850
Schmidhuber, Jurgen. 2015. « Réseaux neuronaux récurrents ». http://people.idsia.ch/~juergen/rnn.html
Olshausen, Bruno A., et David J. Field. 1996. « Emergence des propriétés des champs réceptifs des cellules simples par l’apprentissage d’un code clairsemé pour les images naturelles ». Nature 381.6583 : 607-609. http://www.nature.com/nature/journal/v381/n6583/abs/381607a0.html
Hinton, G. E. et Salakhutdinov, R. R. 2006. « Réduire la dimensionnalité des données avec les réseaux neuronaux ». Science vol. 313 no. 5786 pp. 504-507. http://www.sciencemag.org/content/suppl/2006/08/04/313.5786.504.DC1.
Hinton, Geoffrey E. 2009. « Réseaux de croyance profonds ». Scholarpedia, 4(5):5947.
http://www.scholarpedia.org/article/Deep_belief_networks