Tutoriel sur le Big Data et l’écosystème Hadoop
Bienvenue à la première leçon ‘Big Data et écosystème Hadoop’ du tutoriel Big Data Hadoop qui fait partie du ‘Cours de certification de développeur Big Data Hadoop et Spark’ proposé par Simplilearn. Cette leçon est une introduction au Big Data et à l’écosystème Hadoop. Dans la section suivante, nous allons discuter des objectifs de cette leçon.
Objectifs
Après avoir terminé cette leçon, vous serez en mesure de :
-
Comprendre le concept de Big Data et ses défis
-
Expliquer ce qu’est le Big Data
-
Expliquer ce qu’est Hadoop. et comment il relève les défis du Big Data
-
Décrire l’écosystème Hadoop
Passons maintenant en revue la vue d’ensemble du Big Data et d’Hadoop.
Overview to Big Data and Hadoop
Avant l’an 2000, les données étaient relativement petites qu’elles ne le sont actuellement ; cependant, le calcul des données était complexe. Tous les calculs de données dépendaient de la puissance de traitement des ordinateurs disponibles.
Plus tard, lorsque les données ont augmenté, la solution était d’avoir des ordinateurs avec une grande mémoire et des processeurs rapides. Cependant, après 2000, les données ont continué à croître et la solution initiale ne pouvait plus aider.
Au cours des dernières années, on a assisté à une explosion incroyable du volume des données. IBM a indiqué que 2,5 exaoctets, soit 2,5 milliards de gigaoctets, de données, étaient générés chaque jour en 2012.
Voici quelques statistiques indiquant la prolifération des données, tirées de Forbes, septembre 2015. 40 000 requêtes de recherche sont effectuées sur Google chaque seconde. Jusqu’à 300 heures de vidéo sont téléchargées sur YouTube chaque minute.
Sur Facebook, 31,25 millions de messages sont envoyés par les utilisateurs et 2,77 millions de vidéos sont visionnées chaque minute. En 2017, près de 80 % des photos seront prises sur des smartphones.
En 2020, au moins un tiers de toutes les données passeront par le Cloud (réseau de serveurs connectés sur Internet). D’ici 2020, environ 1,7 mégaoctet de nouvelles informations seront créées chaque seconde pour chaque être humain sur la planète.
Les données augmentent plus rapidement que jamais. Vous pouvez utiliser plus d’ordinateurs pour gérer ces données toujours plus nombreuses. Au lieu qu’une seule machine effectue le travail, vous pouvez utiliser plusieurs machines. C’est ce qu’on appelle un système distribué.
Vous pouvez consulter l’aperçu du cours de certification de développeur Big Data Hadoop et Spark ici !
Regardons un exemple pour comprendre comment fonctionne un système distribué.
Comment fonctionne un système distribué ?
Supposons que vous avez une machine qui a quatre canaux d’entrée/sortie. La vitesse de chaque canal est de 100 Mo/sec et vous voulez traiter un téraoctet de données sur celui-ci.
Il faudra 45 minutes à une machine pour traiter un téraoctet de données. Maintenant, supposons qu’un téraoctet de données est traité par 100 machines avec la même configuration.
Il ne faudra que 45 secondes à 100 machines pour traiter un téraoctet de données. Les systèmes distribués prennent moins de temps pour traiter les Big Data.
Maintenant, examinons les défis d’un système distribué.
Défis des systèmes distribués
Puisque plusieurs ordinateurs sont utilisés dans un système distribué, il y a de fortes chances de défaillance du système. Il y a également une limite sur la bande passante.
La complexité de programmation est également élevée car il est difficile de synchroniser les données et le processus. Hadoop peut relever ces défis.
Comprenons ce qu’est Hadoop dans la section suivante.
Qu’est-ce que Hadoop ?
Hadoop est un cadre qui permet le traitement distribué de grands ensembles de données sur des grappes d’ordinateurs en utilisant des modèles de programmation simples. Il s’inspire d’un document technique publié par Google.
Le mot Hadoop n’a pas de signification. Doug Cutting, qui a découvert Hadoop, l’a nommé d’après l’éléphant jouet de couleur jaune de son fils.
Discutons de la façon dont Hadoop résout les trois défis du système distribué, tels que les risques élevés de défaillance du système, la limite de la bande passante et la complexité de la programmation.
Les quatre caractéristiques clés d’Hadoop sont :
-
Economique : Ses systèmes sont très économiques car des ordinateurs ordinaires peuvent être utilisés pour le traitement des données.
-
Fiable : Il est fiable car il stocke des copies des données sur différentes machines et résiste aux défaillances matérielles.
-
Évolutifs : Il est facilement évolutif à la fois, horizontalement et verticalement. Quelques nœuds supplémentaires aident à mettre à l’échelle le cadre.
-
Flexible : Il est flexible et vous pouvez stocker autant de données structurées et non structurées que vous en avez besoin et décider de les utiliser plus tard.
Traditionnellement, les données étaient stockées dans un emplacement central et elles étaient envoyées au processeur au moment de l’exécution. Cette méthode fonctionnait bien pour des données limitées.
Toutefois, les systèmes modernes reçoivent des téraoctets de données par jour, et il est difficile pour les ordinateurs traditionnels ou le système de gestion de base de données relationnelle (SGBDR) de pousser de grands volumes de données vers le processeur.
Hadoop a apporté une approche radicale. Dans Hadoop, le programme va vers les données, et non l’inverse. Il distribue d’abord les données à plusieurs systèmes et exécute ensuite le calcul là où se trouvent les données.
Dans la section suivante, nous parlerons de la façon dont Hadoop diffère du système de base de données traditionnel.
Différence entre le système de base de données traditionnel et Hadoop
Le tableau ci-dessous vous aidera à distinguer le système de base de données traditionnel et Hadoop.
|
Système de base de données traditionnel |
Hadoop |
|
Les données sont stockées dans un emplacement central et envoyées au processeur au moment de l’exécution. |
Dans Hadoop, le programme va vers les données. Il distribue initialement les données à plusieurs systèmes et exécute plus tard le calcul là où se trouvent les données. |
|
Les systèmes de base de données traditionnels ne peuvent pas être utilisés pour traiter et stocker une quantité importante de données(big data). |
Hadoop fonctionne mieux lorsque la taille des données est importante. Il peut traiter et stocker une grande quantité de données de manière efficace et effective. |
|
Le SGBDR traditionnel est utilisé pour gérer uniquement les données structurées et semi-structurées. Il ne peut pas être utilisé pour contrôler des données non structurées. |
Hadoop peut traiter et stocker une variété de données, qu’elles soient structurées ou non structurées. |
Discutons de la différence entre le SGBDR traditionnel et Hadoop à l’aide d’une analogie.
Vous auriez remarqué la différence dans le style d’alimentation d’un être humain et d’un tigre. Un humain mange de la nourriture à l’aide d’une cuillère, où la nourriture est amenée à la bouche. Alors qu’un tigre amène sa bouche vers la nourriture.
Maintenant, si la nourriture est des données et la bouche est un programme, le style d’alimentation d’un humain représente le SGBDR traditionnel et celui du tigre représente Hadoop.
Regardons l’écosystème Hadoop dans la section suivante.
Écosystème Hadoop
Écosystème Hadoop a un écosystème qui a évolué à partir de ses trois composants de base : traitement, gestion des ressources et stockage. Dans ce sujet, vous apprendrez les composants de l’écosystème Hadoop et comment ils remplissent leurs rôles pendant le traitement des Big Data. L’écosystème
Hadoop se développe continuellement pour répondre aux besoins du Big Data. Il comprend les douze composants suivants :
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop. MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
Vous découvrirez le rôle de chaque composant de l’écosystème Hadoop dans les sections suivantes.

Comprenons le rôle de chaque composant de l’écosystème Hadoop.
Composants de l’écosystème Hadoop
Débutons par le premier composant HDFS de l’écosystème Hadoop.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS est une couche de stockage pour Hadoop.
-
HDFS est adapté au stockage et au traitement distribués, c’est-à-dire que pendant que les données sont stockées, elles sont d’abord distribuées et ensuite traitées.
-
HDFS fournit un accès en streaming aux données du système de fichiers.
-
HDFS fournit la permission et l’authentification des fichiers.
-
HDFS utilise une interface en ligne de commande pour interagir avec Hadoop.
Qu’est-ce qui stocke les données dans HDFS ? C’est la HBase qui stocke les données dans HDFS.
HBase
-
La HBase est une base de données NoSQL ou base de données non relationnelle.
-
La HBase est importante et principalement utilisée lorsque vous avez besoin d’un accès aléatoire, en temps réel, en lecture ou en écriture à vos Big Data.
-
Il fournit un support à un grand volume de données et un débit élevé.
-
Dans un HBase, une table peut avoir des milliers de colonnes.
Nous avons discuté de la façon dont les données sont distribuées et stockées. Maintenant, comprenons comment ces données sont ingérées ou transférées vers HDFS. Sqoop fait exactement cela.
Qu’est-ce que Sqoop ?
-
Sqoop est un outil conçu pour transférer des données entre Hadoop et des serveurs de bases de données relationnelles.
-
Il est utilisé pour importer des données depuis des bases de données relationnelles (telles que Oracle et MySQL) vers HDFS et exporter des données depuis HDFS vers des bases de données relationnelles.
Si vous voulez ingérer des données d’événements telles que des données en streaming, des données de capteurs ou des fichiers journaux, alors vous pouvez utiliser Flume. Nous examinerons le flume dans la section suivante.
Flume
-
Flume est un service distribué qui collecte les données d’événements et les transfère à HDFS.
-
Il est idéalement adapté aux données d’événements provenant de plusieurs systèmes.
Après que les données sont transférées dans le HDFS, elles sont traitées. L’un des frameworks qui traite les données est Spark.
Qu’est-ce que Spark ?
-
Spark est un framework de cluster computing open source.
-
Il fournit des performances jusqu’à 100 fois plus rapides pour quelques applications avec des primitives en mémoire par rapport au paradigme MapReduce à deux étages sur disque d’Hadoop.
-
Spark peut fonctionner dans le cluster Hadoop et traiter les données dans HDFS.
-
Il prend également en charge une grande variété de charges de travail, ce qui inclut l’apprentissage automatique, la veille stratégique, le streaming et le traitement par lots.
Spark possède les principaux composants suivants :
-
Spark Core et Resilient Distributed datasets ou RDD
-
Spark SQL
-
Spark streaming
-
Bibliothèque d’apprentissage machine ou Mlib
-
Graphx.
Spark est maintenant largement utilisé, et vous en apprendrez davantage à son sujet dans les leçons suivantes.
Hadoop MapReduce
-
Hadoop MapReduce est l’autre cadre qui traite les données.
-
C’est le moteur de traitement original d’Hadoop, qui est principalement basé sur Java.
-
Il est basé sur le modèle de programmation map and reduces.
-
De nombreux outils tels que Hive et Pig sont construits sur un modèle de map-reduce.
-
Il a une tolérance aux pannes étendue et mature intégrée au cadre.
-
Il est encore très couramment utilisé mais perd du terrain face à Spark.
Après le traitement des données, celles-ci sont analysées. Il peut être fait par un système de flux de données de haut niveau open-source appelé Pig. Il est utilisé principalement pour l’analytique.
Comprenons maintenant comment Pig est utilisé pour l’analytique.
Pig
-
Pig convertit ses scripts en code Map et Reduce, ce qui évite à l’utilisateur d’écrire des programmes MapReduce complexes.
-
Les requêtes ad hoc comme Filter et Join, qui sont difficiles à réaliser en MapReduce, peuvent être facilement effectuées avec Pig.
-
Vous pouvez également utiliser Impala pour analyser les données.
-
C’est un moteur SQL open-source haute performance, qui fonctionne sur le cluster Hadoop.
-
Il est idéal pour l’analyse interactive et a une latence très faible qui peut être mesurée en millisecondes.
Impala
-
Impala supporte un dialecte de SQL, ainsi les données dans HDFS sont modélisées comme une table de base de données.
-
Vous pouvez également effectuer des analyses de données en utilisant HIVE. Il s’agit d’une couche d’abstraction au-dessus d’Hadoop.
-
Il est très similaire à Impala. Cependant, il est préféré pour le traitement des données et les opérations d’Extract Transform Load, aussi appelé ETL.
-
Impala est préféré pour les requêtes ad-hoc.
HIVE
-
HIVE exécute des requêtes en utilisant MapReduce ; cependant, un utilisateur n’a pas besoin d’écrire de code en MapReduce de bas niveau.
-
Hive convient aux données structurées. Une fois les données analysées, elles sont prêtes à être consultées par les utilisateurs.
Maintenant que nous savons ce que fait Hive, nous allons discuter de ce qui prend en charge la recherche de données. La recherche de données se fait à l’aide de Cloudera Search.
Cloudera Search
-
Search est l’un des produits d’accès en temps quasi réel de Cloudera. Il permet aux utilisateurs non techniques de rechercher et d’explorer les données stockées dans ou ingérées dans Hadoop et HBase.
-
Les utilisateurs n’ont pas besoin de compétences en SQL ou en programmation pour utiliser Cloudera Search car il fournit une interface simple de recherche en texte intégral.
-
Un autre avantage de Cloudera Search par rapport aux solutions de recherche autonomes est la plateforme de traitement des données entièrement intégrée.
-
Cloudera Search utilise le système de stockage flexible, évolutif et robuste inclus dans CDH ou Cloudera Distribution, y compris Hadoop. Cela élimine le besoin de déplacer de grands ensembles de données à travers les infrastructures pour répondre aux tâches métier.
-
Les tâches Hadoop telles que MapReduce, Pig, Hive et Sqoop ont des flux de travail.
Oozie
-
Oozie est un workflow ou un système de coordination que vous pouvez utiliser pour gérer les jobs Hadoop.
Le cycle de vie d’une application Oozie est illustré dans le diagramme ci-dessous.
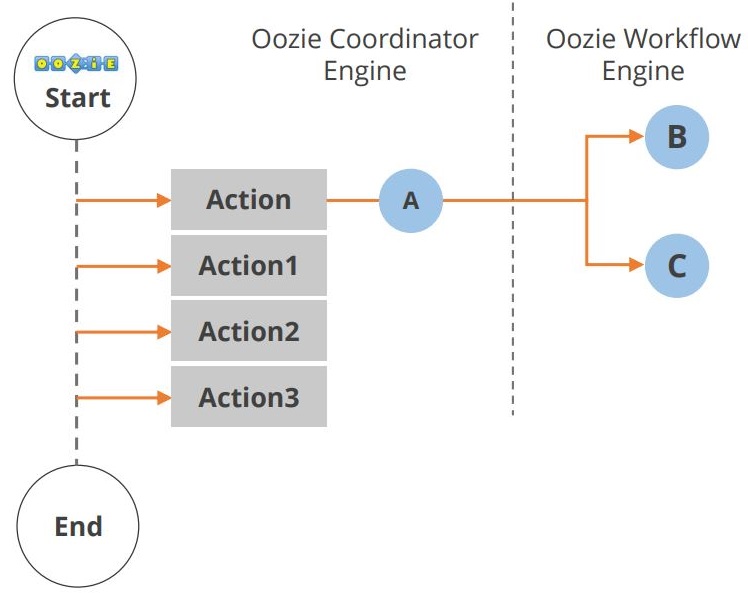 Comme vous pouvez le voir, de multiples actions se produisent entre le début et la fin du workflow. Un autre composant de l’écosystème Hadoop est Hue. Examinons maintenant le Hue.
Comme vous pouvez le voir, de multiples actions se produisent entre le début et la fin du workflow. Un autre composant de l’écosystème Hadoop est Hue. Examinons maintenant le Hue.
Hue
Hue est un acronyme pour Hadoop User Experience. Il s’agit d’une interface web open-source pour Hadoop. Vous pouvez effectuer les opérations suivantes en utilisant Hue :
-
Transférer et parcourir des données
-
Interroger une table dans HIVE et Impala
-
Exécuter des tâches et des flux de travail Spark et Pig Rechercher des données
-
En somme, Hue facilite l’utilisation d’Hadoop.
-
Il fournit également un éditeur SQL pour HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL et Solr SQL.
Après ce bref aperçu des douze composants de l’écosystème Hadoop, nous allons maintenant discuter de la façon dont ces composants fonctionnent ensemble pour traiter les Big Data.
Étapes du traitement des Big Data
Il existe quatre étapes de traitement des Big Data : Ingestion, Traitement, Analyse, Accès. Examinons-les en détail.
Ingestion
La première étape du traitement des Big Data est l’ingestion. Les données sont ingérées ou transférées vers Hadoop à partir de diverses sources telles que des bases de données relationnelles, des systèmes ou des fichiers locaux. Sqoop transfère les données du SGBDR vers HDFS, tandis que Flume transfère les données d’événements.
Traitement
La deuxième étape est le traitement. Dans cette étape, les données sont stockées et traitées. Les données sont stockées dans le système de fichiers distribué, HDFS, et dans les données distribuées NoSQL, HBase. Spark et MapReduce effectuent le traitement des données.
Analyse
La troisième étape est l’analyse. Ici, les données sont analysées par des cadres de traitement tels que Pig, Hive et Impala.
Pig convertit les données à l’aide d’un map and reduce et les analyse ensuite. Hive est également basé sur la programmation map and reduce et est plus adapté aux données structurées.
Access
La quatrième étape est l’accès, qui est effectué par des outils tels que Hue et Cloudera Search. Dans cette étape, les données analysées peuvent être consultées par les utilisateurs.
Hue est l’interface web, tandis que Cloudera Search fournit une interface texte pour l’exploration des données.
Check out the Big Data Hadoop and Spark Developer Certification course Here !
Sommaire
Résumons maintenant ce que nous avons appris dans cette leçon.
-
Hadoop est un cadre pour le stockage et le traitement distribués.
-
Les composants de base d’Hadoop comprennent HDFS pour le stockage, YARN pour la gestion des ressources du cluster, et MapReduce ou Spark pour le traitement.
-
L’écosystème Hadoop comprend de multiples composants qui prennent en charge chaque étape du traitement des Big Data.
-
Flume et Sqoop ingèrent les données, HDFS et HBase stockent les données, Spark et MapReduce traitent les données, Pig, Hive et Impala analysent les données, Hue et Cloudera Search aident à explorer les données.
-
Oozie gère le workflow des jobs Hadoop.
Conclusion
Ceci conclut la leçon sur le Big Data et l’écosystème Hadoop. Dans la prochaine leçon, nous aborderons HDFS et YARN.
Trouvez nos cours de formation en ligne de développeur Big Data Hadoop et Spark dans les principales villes :
| Nom | Date | Lieu | |
|---|---|---|---|
| Big Data Hadoop et Spark Developer | 3 avr -15 mai 2021, Lot week-end | Votre ville | Voir les détails |
| Big Data Hadoop and Spark Developer | 12 avr -4 mai 2021, Lot jours de semaine | Votre ville | Voir les détails |
| Big Data Hadoop et Spark Developer | 24 avr -5 juin 2021, Lot de week-end | Votre ville | Voir les détails |
{{lectureCoursePreviewTitle} Voir la transcription Regarder la vidéo
Pour en savoir plus, suivez le cours
Formation de certification de développeur Big Data Hadoop et Spark
Aller au cours
Pour en savoir plus, suivez le cours
Formation de certification de développeur Big Data Hadoop et Spark Allez au cours
.