Temps réel vs traitement par lots vs traitement en flux
Avec le rythme constant de l’innovation, les développeurs peuvent s’attendre à analyser des téraoctets et même des pétaoctets de données dans une période donnée. (Les données, après tout, attirent d’autres données.)
Cela permet de nombreux avantages, bien sûr. Mais que faire de toutes ces données ? Il peut être difficile de connaître la meilleure façon d’accélérer et d’accélérer ces technologies, en particulier lorsque les réactions doivent se produire rapidement.
Pour les entreprises du digital-first, une question croissante est devenue la meilleure façon d’utiliser le traitement en temps réel, le traitement par lots et le traitement en flux. Ce post expliquera les différences fondamentales entre ces types de traitement de données.
Systèmes d’exploitation en temps réel
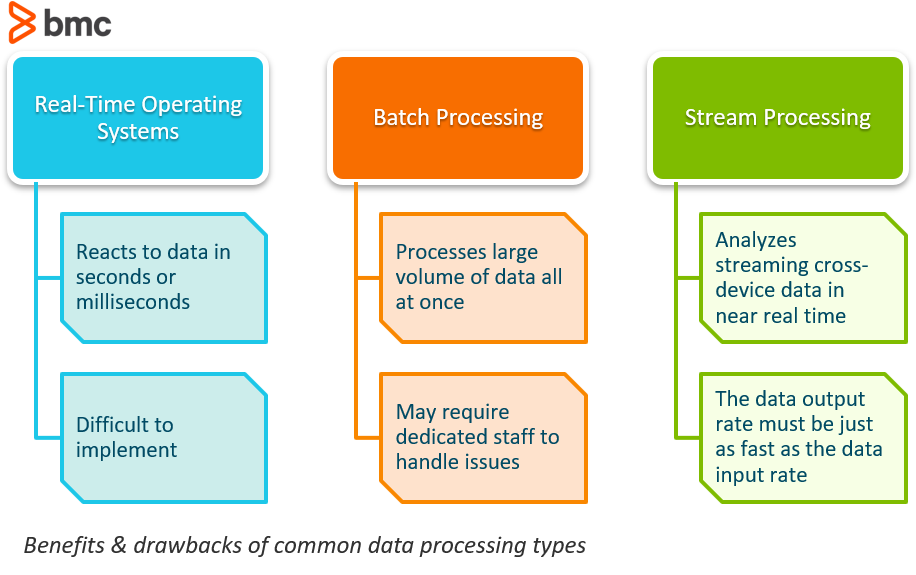
Les systèmes d’exploitation en temps réel font généralement référence aux réactions aux données. Un système peut être catégorisé comme étant en temps réel s’il peut garantir que la réaction se fera dans un délai serré du monde réel, généralement en quelques secondes ou millisecondes.
L’un des meilleurs exemples de système en temps réel sont ceux utilisés sur le marché boursier. Si une cotation boursière doit provenir du réseau dans les 10 millisecondes suivant sa mise en place, cela serait considéré comme un processus en temps réel. Que cela ait été obtenu en utilisant une architecture logicielle utilisant le traitement en flux ou simplement le traitement dans le matériel n’a pas d’importance ; la garantie du délai serré est ce qui en fait un temps réel.
D’autres situations où l’utilisation de systèmes en temps réel serait bénéfique sont :
- ATMs
- Contrôle du trafic aérien
- Systèmes de freinage antiblocage dans votre voiture
Défis
Bien que ce type de système semble changer la donne, la réalité est que les systèmes en temps réel sont extrêmement difficiles à mettre en œuvre par l’utilisation de systèmes logiciels communs. Comme ces systèmes prennent le contrôle de l’exécution du programme, cela apporte un tout nouveau niveau d’abstraction.
Ce que cela signifie, c’est que la distinction entre le flux de contrôle de votre programme et le code source n’est plus apparente parce que le système en temps réel choisit la tâche à exécuter à ce moment-là. Cela est bénéfique, car cela permet une plus grande productivité en utilisant une plus grande abstraction et peut faciliter la conception de systèmes complexes, mais cela signifie moins de contrôle dans l’ensemble, ce qui peut être difficile à déboguer et à valider.
Un autre défi commun avec les systèmes d’exploitation en temps réel est que les tâches ne sont pas des entités isolées. Le système décide lesquelles planifier et envoie les tâches les plus prioritaires avant les moins prioritaires, retardant ainsi leur exécution jusqu’à ce que toutes les tâches prioritaires soient terminées.
De plus en plus, certains systèmes logiciels commencent à opter pour une saveur de traitement en temps réel où la date limite n’est pas tant un absolu qu’une probabilité. Connus sous le nom de systèmes en temps réel doux, ils sont capables de respecter habituellement ou généralement leur délai, bien que les performances commencent à se dégrader si trop de délais sont manqués.
Traitement par lots
Le traitement par lots est le traitement d’un grand volume de données en une seule fois. Les données se composent facilement de millions d’enregistrements pour une journée et peuvent être stockées de différentes manières (fichier, enregistrement, etc). Les travaux sont généralement effectués simultanément, sans interruption, dans un ordre séquentiel.
Un exemple courant de travail de traitement par lots est l’ensemble des transactions qu’une entreprise financière pourrait soumettre au cours d’une semaine. Le traitement par lots peut également être utilisé dans :
- Les processus de paie
- Les factures d’articles de ligne
- La chaîne d’approvisionnement et l’exécution
Le traitement de données par lots est un moyen extrêmement efficace de traiter de grandes quantités de données qui sont collectées sur une période de temps. Il permet également de réduire les coûts opérationnels que les entreprises pourraient consacrer à la main-d’œuvre, car il ne nécessite pas de commis spécialisés dans la saisie de données pour soutenir son fonctionnement. Il peut être utilisé hors ligne et donne aux gestionnaires un contrôle complet sur le moment de commencer le traitement, que ce soit pendant la nuit ou à la fin d’une semaine ou d’une période de paie.
Défis
Comme pour tout, il y a quelques inconvénients à utiliser un logiciel de traitement par lots. L’un des plus grands problèmes que les entreprises voient est que le débogage de ces systèmes peut être délicat. Si vous n’avez pas d’équipe ou de professionnel informatique dédié, essayer de réparer le système lorsqu’une erreur se produit pourrait être préjudiciable, entraînant la nécessité d’un consultant externe pour aider.
Un autre problème avec le traitement par lots est que les entreprises le mettent généralement en œuvre pour économiser de l’argent, mais le logiciel et la formation nécessitent un montant décent de dépenses au début. Les gestionnaires devront être formés pour comprendre :
- Comment programmer un lot
- Ce qui les déclenche
- Ce que signifient certaines notifications
(En savoir plus sur le traitement par lots moderne.)
Traitement en flux
Le traitement en flux est le processus qui consiste à être capable d’analyser presque instantanément les données qui passent d’un appareil à un autre.
Cette méthode de calcul continu se produit au fur et à mesure que les données circulent dans le système, sans limite de temps obligatoire pour la sortie. Avec le flux presque instantané, les systèmes ne nécessitent pas de grandes quantités de données à stocker.
Le traitement en flux est très bénéfique si les événements que vous souhaitez suivre se produisent fréquemment et sont proches dans le temps. Il est également préférable de l’utiliser si l’événement doit être détecté tout de suite et faire l’objet d’une réponse rapide. Le traitement en continu est donc utile pour des tâches telles que la détection des fraudes et la cybersécurité. Si les données de transaction sont traitées en flux, les transactions frauduleuses peuvent être identifiées et arrêtées avant même qu’elles ne soient terminées.
Défis
L’un des plus grands défis auxquels les organisations sont confrontées avec le traitement en flux est que le taux de sortie des données à long terme du système doit être aussi rapide, voire plus rapide, que le taux d’entrée des données à long terme, sinon le système commencera à avoir des problèmes de stockage et de mémoire.
Un autre défi est d’essayer de trouver la meilleure façon de faire face à l’énorme quantité de données qui sont générées et déplacées. Afin de maintenir le flux de données à travers le système fonctionnant au niveau optimal le plus élevé, il est nécessaire pour les organisations de créer un plan pour savoir comment réduire le nombre de copies, comment cibler les noyaux de calcul et comment utiliser la hiérarchie de cache de la meilleure façon possible.
Conclusion
Bien que tous ces systèmes aient des avantages, à la fin de la journée, les organisations devraient considérer les avantages potentiels de chacun pour décider de la méthode la mieux adaptée au cas d’utilisation.
Ressources supplémentaires
- BMC Workload Automation Blog
- BMC Big Data Blog
- Guide du débutant pour l’automatisation du lieu de travail
- Qu’est-ce qu’une tâche par lot ?
- Qu’est-ce qu’un pipeline de données ?
Gérer le sl comme pour vos services batch joe goldberg de BMC Software
Amener une approche moderne du traitement batch

Ces affichages sont les miens et ne représentent pas nécessairement la position, les stratégies ou l’opinion de BMC.
Vous voyez une erreur ou avez une suggestion ? Faites-le nous savoir en envoyant un courriel à [email protected].