Reddit AmItheAsshole est plus gentil avec les femmes qu’avec les hommes – une preuve SQL ?
Lorsque les redditeurs demandent « suis-je le connard » en parlant des femmes, ils ont plus de chances d’être jugés comme le connard. Vérifions ces métriques – avec BigQuery, dbt, et Data Studio
Faites attention à ne pas prendre tout ce que j’ai écrit ici comme la vérité absolue. Plusieurs personnes sur Twitter ont noté des problèmes et ajouté des corrections à l’analyse que je proposais. Lire ce billet tel qu’il a été présenté à l’origine – et les réactions – peut être un excellent moyen pour vous d’apprendre autant que je l’ai fait en lisant les réponses. Vous pouvez trouver beaucoup de leurs pensées non filtrées en suivant ce fil Twitter.
Contexte
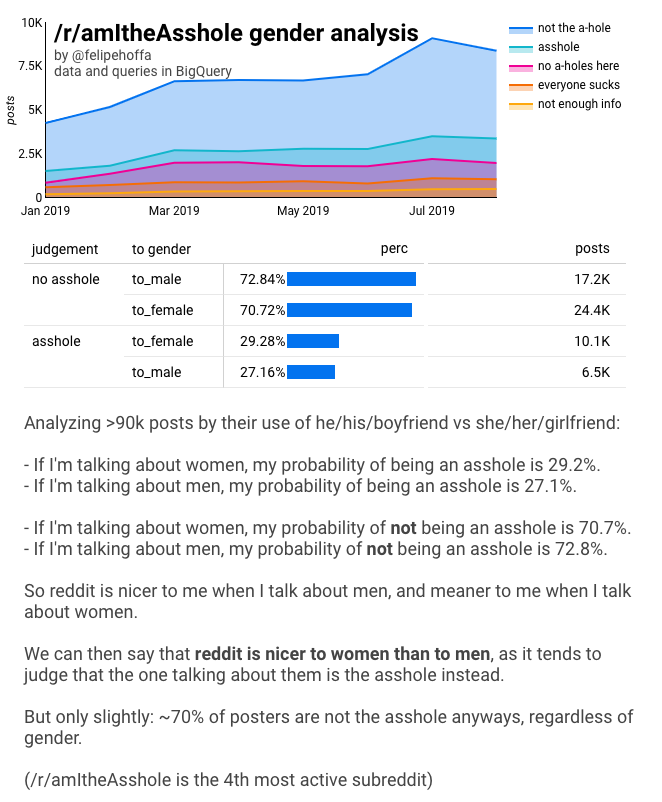
/r/amItheAsshole a grandi pour devenir le 4e subreddit le plus actif – par le nombre de commentaires. Les gens viennent sur ce subreddit pour raconter leurs histoires, et ils demandent aux autres redditeurs « c’est moi le trou du cul ici ? ». Il s’avère que la plupart des gens sont jugés comme n’étant « pas le trou du cul », comme le montre ce graphique :
Mon tweet avec ces résultats a reçu beaucoup d’attention :
Y compris la question – reddit est-il plus gentil avec les femmes ou avec les hommes ?
Décider du genre
En regardant le titre ou le contenu d’un post, vous pourriez avoir du mal à décider si « je » est un homme ou une femme – mais il est assez facile de compter le nombre de « elle/il/son/petit ami/petite amie » présents dans l’histoire.
Regardons quelques posts aléatoires, et le compte de chacun de ces pronoms et mots genrés:

Nous pouvons voir que le décompte des pronoms et des mots genrés dans l’exemple correspond à la personne dont parle l’histoire. Ces histoires parlent d’un client masculin, d’une petite amie féminine, d’un voisin masculin, d’un fils masculin et d’une fille adolescente féminine.
Avec ces chiffres, nous pouvons maintenant établir une règle arbitraire : s’il y a plus du double de pronoms masculins que féminins, ce post parle d’un homme. Nous pouvons utiliser la règle inverse pour dire que le message concerne une femme. Si les chiffres sont trop proches ou nuls, nous qualifierons le post de « neutre ».
Une autre règle que nous pouvons fixer pour simplifier l’analyse:
- Si le jugement est « pas le trou du cul » ou « pas de trou du cul ici », alors nous pouvons dire « le poster n’est pas un trou du cul ».
- Si le jugement est ‘trou du cul’ ou ‘tout le monde est nul’ alors on peut dire ‘l’affiche est un trou du cul’.
Si on agrège tous ces posts, on arrive aux chiffres :

Lorsque j’ai présenté ces résultats pour la première fois, on m’a dit « ces chiffres sont trop proches, ils pourraient être une erreur statistique ».
Signification statistique ?
Comment pouvons-nous dire que les chiffres ne sont pas une simple erreur statistique ? Voyons la tendance mois par mois – est-elle stable ?

Oui ! La tendance varie d’un mois à l’autre, mais il y a clairement plus de chances d’être un connard quand on parle de femmes que quand on parle d’hommes. Si la petite différence n’était qu’un coup de chance statistique, on s’attendrait plutôt à ce que la tendance fasse un saut sauvage.
Et notez bien que ces résultats sont très spécifiques, comme le note ce tweet :
A quoi j’ai répondu
Comment
Cette fois, j’utilise dbt pour la première fois, et j’ai laissé tout mon code sur GitHub. Merci Claire Carroll pour votre aide à démarrer avec cet outil génial !
Pour extraire tous les posts de /r/AmItheAsshole dans BigQuery vers une nouvelle table, vous pouvez faire :
CREATE TABLE temp.data ASSELECT *
FROM `fh-bigquery.reddit_posts.20*'
WHERE subreddit = 'AmItheAsshole'
AND _table_suffix > '19_'
Puis le sexe et le jugement pour chaque post peuvent être déterminés avec une requête comme :
WITH data AS (
SELECT *
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhe\b')) hes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bshe\b')) shes
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bher\b')) hers
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bhis\b')) hiss
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bthey\b')) theys
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bgirlfriend\b')) gfs
, ARRAY_LENGTH(REGEXP_EXTRACT_ALL(CONCAT(selftext, title), r'(?i)\bboyfriend\b')) bfs
FROM {{ref('aita_posts')}}
WHERE link_flair_text IS NOT NULL
)
, gendered_data AS (
SELECT *
, CASE
WHEN males > 2+females*2 THEN 'to_male'
WHEN females > 2+males*2 THEN 'to_female'
ELSE 'neutral'
END to_gender
FROM (
SELECT *, hes+shes+hers+hiss+theys+gfs+bfs totalgender, hes+hiss+bfs males, shes+hers+gfs females
FROM data
)
)
SELECT CASE link_flair_text
WHEN 'not the a-hole' THEN 'no asshole'
WHEN 'no a-holes here' THEN 'no asshole'
WHEN 'everyone sucks' THEN 'asshole'
WHEN 'asshole' THEN 'asshole'
END judgement
, *
FROM gendered_data
WHERE link_flair_text IS NOT NULL
Et enfin les statistiques présentées ici :
SELECT *, c/total_gender AS perc
FROM (
SELECT *, SUM(c) OVER(PARTITION BY to_gender, MONTH ) total_gender, SUM(c) OVER(PARTITION BY judgement, MONTH) total_judgement
FROM (
SELECT to_gender, judgement, CONCAT(to_gender, ': ', judgement) to_gender_judgement, month, COUNT(*) c, ARRAY_AGG(STRUCT(title, selftext) ORDER BY RAND() LIMIT 1) sample_title
FROM {{ref('aita_posts_gendered')}}
WHERE judgement IS NOT null
AND to_gender != 'neutral'
GROUP BY 1,2,3,4
)
)
WHERE c/total_gender > 0.01
AND total_judgement > 10
ORDER BY to_gender, perc DESC
Discussion
Vous trouverez de nombreuses réponses perspicaces et divertissantes sur le fil twitter de ce post :
N’hésitez pas à rejoindre la discussion (et à me dire si j’ai tort ?). N’oubliez pas d’être gentil les uns avec les autres – la plupart des gens ne sont pas le trou du cul de toute façon.
Vous en voulez plus ?
Je n’ai couvert que jusqu’en août 2019 car c’est quand l’archive reddit complète actuelle dans BigQuery s’arrête – jusqu’aux futures mises à jour prévues. Consultez mon précédent post pour plus de détails sur la collecte de données en direct de pushshift.io. Merci Jason Baumgartner pour l’approvisionnement constant !
Je suis Felipe Hoffa, un défenseur des développeurs pour Google Cloud. Suivez-moi sur @felipehoffa, retrouvez mes précédents posts sur medium.com/@hoffa, et tout sur BigQuery sur reddit.com/r/bigquery.