Comment construire un moteur de règles métier moderne, un aperçu rapide
Ceci est un aperçu conceptuel de haut niveau de l’architecture du moteur de règles métier. Il se situe au-dessus du code réel. Si vous construisez un moteur de règles métier – il est très probable que vous trouverez ce texte utile.
De temps en temps, j’ai construit un moteur de règles métier qui permettait l’automatisation des affaires pour les petites et moyennes entreprises et qui avait également toutes les capacités et le potentiel pour bien servir les grandes entreprises. C’était un moyen de passer d’une application logicielle ordinaire à une solution sophistiquée et complexe qui répondait aux exigences difficiles d’évolutivité, de maintenabilité et d’extensibilité. Ce texte fournira une vue d’ensemble de ce qu’est le moteur de règles métier et décrira l’une des approches modernes de sa construction que vous pouvez envisager lors de la création de ce type de logiciel.
Pour commencer, il est important de définir les termes de base. Les moteurs de règles métier existent dans l’industrie depuis assez longtemps sous une forme ou une autre et il existe des définitions données pour à peu près tous les termes que nous allons utiliser. Commençons par une « règle métier » – il existe une définition bien connue de ce terme. Ainsi, une « règle métier » est :
Un énoncé qui définit ou contraint un aspect de l’entreprise. Elle est destinée à affirmer la structure de l’entreprise ou à contrôler ou influencer le comportement de l’entreprise.
T. Morgan, Règles d’entreprise et systèmes d’information. Boston : Addison-Wesley Publishing, 2002
Les règles métier ont un champ d’application très large et peuvent être appliquées à n’importe quel aspect de l’entreprise. Par exemple, la règle « Lorsqu’un client entre, accueillez-le avec un sourire chaleureux et un « Bonjour » amical » est appliquée par le salarié de l’entreprise lorsqu’il rencontre les clients. Une autre règle peut définir ou contraindre les approches de résolution des tâches de routine par un rôle spécifique dans une entreprise. Avec l’augmentation constante de la popularité des solutions logicielles telles que les systèmes de gestion de la relation client (CRM) et l’intégration totale des logiciels dans divers domaines d’activité, la majorité des processus commerciaux sont devenus partiellement ou totalement orientés vers les données. Par exemple, la règle de gestion « Lorsqu’un client achète quelque chose dans notre magasin, appelez-le plus tard pour lui demander s’il souhaite acheter d’autres produits connexes » s’est transformée en une règle plus moderne : « Lorsqu’un client achète quelque chose dans notre magasin en ligne, envoyez-lui un courrier électronique lui indiquant d’autres produits connexes plus tard ». Aujourd’hui, de nombreuses entreprises traitent principalement des données dans leurs activités quotidiennes. Compte tenu, que la majorité des entreprises de toutes tailles ont intégré des solutions logicielles à leurs activités commerciales, la définition du terme « règle métier » peut être définie de manière plus spécifique en ajoutant une précision (elle est en gras) à la définition susmentionnée de T. Morgan:
Une règle métier est une déclaration qui définit ou contraint un aspect de l’entreprise. Elle est destinée à affirmer la structure de l’entreprise ou à contrôler ou influencer le comportement de l’entreprise. Elle est stockée comme une construction de données dans le stockage persistant et détient un paquet atomique de la logique d’entreprise. Elle est gérée et appliquée aux processus d’affaires de l’entreprise de manière automatique via une solution logicielle.
Ayant défini le terme « règle d’affaires », le terme « système de gestion du moteur de règles d’affaires » (BRMS) est défini comme suit :
Le BRMS est une solution logicielle permettant de gérer (stockage, édition et suppression, etc.) les règles d’affaires ainsi que de les appliquer aux processus d’affaires de l’entreprise.
Les BRMS commerciaux peuvent être extrêmement coûteux pour l’achat de la licence et pour les intégrer dans l’infrastructure informatique de l’entreprise, c’est pourquoi les entreprises mettent souvent en œuvre des solutions internes lorsqu’elles rencontrent un besoin d’automatisation des processus métier ou d’autres types de processus.
Les BRMS peuvent devenir une partie essentielle et vitale de toute entreprise. Parfois, le succès d’une entreprise peut dépendre des règles métier qu’elle possède et de la façon dont ces règles métier sont gérées et appliquées.
La construction de données de règles métier
Une règle métier peut être représentée comme une série conséquente de commandes atomiques. Les commandes peuvent inclure des analyses de données conditionnelles, des commandes d’attente de temps, des commandes d’exécution d’actions, etc. L’exemple de règle métier « Lorsqu’un client achète quelque chose dans notre boutique en ligne, envoyez-lui plus tard un email listant d’autres biens connexes » est un bon exemple générique et de nombreuses autres règles métier peuvent avoir une structure logique très similaire :

Le flux de traitement des règles est lancé lorsqu’un achat a été effectué et qu’une certaine logique métier est appliquée en exécutant la commande « Envoyer à l’acheteur un email avec des offres de marchandises pertinentes ». Il se peut que l’acheteur ait désactivé l’abonnement au courrier électronique. Dans ce cas, la condition supplémentaire doit être ajoutée à la règle de gestion – « si l’acheteur a un abonnement au courrier électronique activé »:

Les commandes sont exécutées en conséquence et il y a maintenant une commande d’analyse de données pour vérifier si l’acheteur a un abonnement au courrier électronique actif. Si c’est le cas, passez à l’exécution de la commande suivante de la règle métier. Et si ce n’est pas le cas – ne pas procéder, la règle métier est considérée comme terminée, le flux de traitement s’arrête, les commandes suivantes ne sont pas exécutées.
L’acheteur peut également avoir un abonnement SMS, et s’il est actif, il devrait y avoir une autre commande également – « Envoyer un SMS avec l’offre promotionnelle associée ». Avec cela, la ramification est introduite dans la logique de la règle métier:
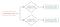
Les branches de la règle sont traitées indépendamment les unes des autres. Le traitement d’une des branches peut s’arrêter sur la commande d’évaluation de la condition et une autre branche peut être traitée jusqu’à la fin.
L’interface utilisateur de l’application côté client de BRMS pour représenter une règle métier peut être mise en œuvre de diverses manières (tout type de représentation graphique arborescente fonctionnera) :

La construction de données de règle métier est un graphe arborescent orienté enraciné (un graphe acyclique orienté, qui a un arbre comme graphe non orienté sous-jacent). Les sommets du graphe de règles métier sont représentés par différents types de commandes : commandes d’analyse de données, commandes d’exécution d’actions, commandes d’attente de temps, etc. Chaque arbre orienté et enraciné possède une racine – un sommet dont toutes les arêtes partent. Ainsi, chaque règle commence par un sommet spécial (ou sommet racine en termes de théorie des graphes) – le sommet qui désigne le point d’entrée pour le traitement de la règle.
OpérationsCRUD sur la construction de données de règles métier
Puisque la construction de données est représentée avec un arbre à racines dirigées et jamais aucun autre type de graphe, cela nous libère des inconvénients qui accompagnent le stockage de structures de graphes générales avec les SGBDR (comme le stockage des sommets et des arêtes dans différentes tables, ce qui peut entraîner un nombre accru de recherches pour une seule récupération de règles, etc.) Et ceci est critique parce qu’il est clair que pendant les opérations normales du SGRB, les recherches de données se produisent beaucoup plus souvent, que d’autres opérations comme les insertions, les mises à jour ou les suppressions.

Pour rappel – chaque sommet de la règle métier représente une commande atomique. Elle est sauvegardée dans la table du SGBDR en tant qu’enregistrement avec des attributs tels que le type de commande, la description et d’autres données supplémentaires. Dans un arbre, chaque sommet a un et un seul parent (à l’exception du sommet racine, qui n’a pas de parents), donc chaque enregistrement doit contenir un ID du sommet parent. Il est également pratique d’avoir une autre table qui abrite les enregistrements de règles avec les données relatives à la règle métier elle-même. Il n’y a aucun problème pour stocker les constructions de données de règles métier de n’importe quelle complexité avec cette approche.
Les opérations CRUD sont assez simples. Les modifications de la règle métier peuvent nécessiter des mises à jour d’une ou des deux tables – règle ou commande. Lors de la suppression ou de l’insertion de commandes, il est nécessaire de maintenir les références entre les commandes (il s’agit essentiellement de supprimer ou d’insérer des nœuds dans un arbre).
Un des composants du BRMS, appelons-le un gestionnaire, devrait effectuer les opérations de base de données décrites et fournir une API pour les opérations CRUD sur les règles métier.
Le traitement de la règle métier
Le traitement de la règle métier commence lorsqu’un événement métier particulier se produit. Cela peut être n’importe quoi – un utilisateur s’est connecté, un achat a été effectué, un certain montant d’argent a été transféré, etc. Ce type d’activité doit être suivi et le BRMS doit en être informé par le biais d’un transport. AMQP est très probablement le mieux adapté à ce type de tâche.

1. L’ensemble du concept est construit sur une architecture de microservices. Le microservice consommateur d’événements métier écoute tous les événements métier via la déclaration d’une file d’attente et sa liaison à un échange spécifique sur un serveur d’échange RabbitMQ. Lorsqu’une activité commerciale (considérée comme importante et faisant l’objet d’un suivi) se produit dans le système logiciel principal, le message est envoyé au serveur d’échange RabbitMQ. Il contient des informations sur ce qui s’est passé ainsi que des données supplémentaires pertinentes. L’événement commercial peut être identifié par un attribut de n’importe quel type transmis dans le message ou utilisé comme clé de routage, par exemple, une chaîne de caractères purchase.completed. Le message est ensuite consommé par le microservice consommateur d’événement d’affaires BRMS.

2. Lorsque le microservice consommateur d’événement d’affaires reçoit le message du système logiciel principal, il interroge alors le microservice gestionnaire s’il existe des règles d’affaires dans la base de données qui ont le déclencheur de règle approprié pour l’événement d’activité d’affaires. Et s’il existe une règle métier correspondante, le microservice gestionnaire renvoie les données de la commande initiale au microservice consommateur d’événement métier. Cette récupération de données à partir du gestionnaire est effectuée via gRPC et est visualisée avec une ligne pointillée.
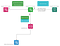
3. Juste après que le microservice gestionnaire réponde avec les données de commande initiale, le microservice consommateur d’événements métier est prêt à initialiser le traitement de la règle métier. Le consommateur d’événement métier forme un autre message qui encapsule les données de commande initiale (reçues du microservice gestionnaire), et les données de l’événement métier, reçues du système logiciel principal. Il l’envoie via l’AMQP à un échange interne du BRMS. La clé de routage du message correspond au type de commande.
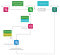
4. Le microservice de traitement initial des commandes consomme le message (il écoute la file d’attente où sont empilés les messages avec la clé de routage initial). Ensuite, il fait sa logique (dans un cas de base le bloc initial n’abrite aucune logique) et interroge le gestionnaire s’il y a des commandes ultérieures dans la règle métier (ce sont les commandes avec parent_id égal au id de la commande qui est actuellement traitée). Et si c’est le cas, il reçoit les données de la commande suivante et envoie à la fois les données de l’événement métier et les données de la commande suivante au serveur RabbitMQ interne. Oui, cela ressemble maintenant à une traversée de liste liée, et lorsque la règle a des branches, c’est une traversée d’arbre ! C’est ainsi que la règle métier est traitée commande par commande. Une autre chose importante ici – dans ce contexte, les données de l’événement commercial sont transmises à chaque commande enfant. Il s’agit d’un contexte d’exécution de la règle métier unique. Il peut être utilisé plus tard dans le processeur de commande d’analyse de données et le processeur de commande d’action.
À des fins d’illustration, supposons que la règle d’exemple a une structure comme celle-ci : commande initiale -> commande d’analyse de données conditionnelle -> commande d’action métier. Alors la commande suivante après initial est la commande d’analyse de données.

5. Le processeur de commande d’analyse consomme le message avec la clé de routage analysis provenant de l’échange interne. Sur la base de l’évaluation des conditions, qui sont décrites dans la commande d’analyse de la règle métier et en utilisant les données de l’événement métier, le flux d’exécution de la règle peut continuer ou s’arrêter ici. S’il s’arrête, aucune autre commande de règle métier n’est exécutée. Si le flux d’exécution continue, le processeur de commande d’analyse interroge le gestionnaire pour les prochaines commandes de règle métier, les récupère et publie un autre message sur le serveur d’échange interne.
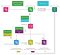
6. Enfin, il y a un message dans l’échange interne, qui est prêt à être consommé par le processeur de commande d’action. Si le flux d’exécution de la règle métier est arrivé jusqu’à cette commande, cela signifie que dans cette branche de la règle, toutes les conditions présentes dans la commande d’analyse des données étaient vraies et que le flux d’exécution n’a pas été interrompu. Le processeur de commande d’action exécute l’action, par exemple envoie un email.
Ce type de traversée du graphe est en profondeur d’abord, et quand une commande avec 2 ou plusieurs commandes filles est rencontrée, la traversée simultanée en profondeur d’abord commence pour chaque branche en raison de la nature asynchrone du traitement des règles métier dans le système décrit.
Scaling
L’approche décrite permet non seulement une grande séparation des préoccupations mais peut également économiser beaucoup d’argent quand il s’agit de payer les factures IaaS. Les utilisateurs finaux créent une variété de règles métier avec différents nombres de commandes de différents types et différents nombres de branches. Mais les scénarios de mise à l’échelle les plus courants sont les suivants :
1. Le nombre d’événements métier augmente – le consommateur d’événements métier passe à l’échelle.
2. Le nombre de règles métier associées (déclenchées) par les événements métier augmente – le processeur de commandes initiales passe à l’échelle en même temps que le gestionnaire.
3. Il y a beaucoup de commandes d’analyse dans les règles métier – le processeur de commandes d’analyse passe à l’échelle
4. Trop de commandes d’action doivent être exécutées – le processeur de commandes d’action passe à l’échelle.
Fiabilité
Le vaisseau sanguin du système est le transport. Pour que le système reste opérationnel sous une charge élevée, l’échange de messages interne doit être hautement fiable. RabbitMQ fournit le clustering et satisfait bien les exigences de fiabilité (https://www.rabbitmq.com/clustering.html).
Autres types de commande
Toute autre logique commerciale peut être introduite dans le système. L’un des types de commande les plus populaires et les plus demandés est la commande d’attente temporelle (par exemple, » Attendre 45 minutes, puis continuer « ). Avec l’introduction de la commande d’attente, le traitement de la règle métier n’est plus un traitement en temps réel puisqu’il peut être suspendu pendant un certain temps. De tels changements nécessitent des processeurs de commande supplémentaires et quelques modifications des structures de données qui sortent du cadre de ce texte. Jouer avec le temps peut être difficile et écrire un service qui exploite les horaires et le temps peut être un défi, voici un exemple d’un bon : https://github.com/nextiva/krolib
Alternatives tierces
Il existe des alternatives bien connues de moteurs de règles/moteurs de flux de travail, voici le top 3 d’entre elles (IMHO):
1. Comunda – c’est un produit mature avec des versions communautaires et d’entreprise, que vous pouvez vouloir utiliser. Évidemment, la version entreprise est payante.
2. Luigi – c’est un outil de moteur de flux de travail développé par Spotify pour leurs besoins internes, mais déjà utilisé par des dizaines d’autres entreprises.
3. Apache Airflow – c’est un autre produit bien connu qui a prouvé qu’il était capable, pratique et personnalisable.
Ce qui unit ces outils, c’est qu’ils utilisent tous des graphes acycliques directs comme structure de données qui représente les règles d’affaires ou les flux de travail. Ce n’est pas une surprise.
Il peut y avoir d’autres produits qui méritent l’attention, mais toute enquête devrait commencer avec ces trois-là.
Conclusion
Construire votre propre moteur de règles métier peut être un défi, mais c’est gratifiant. Non seulement vous obtenez un système interne, mais il est également construit en fonction des exigences spécifiques de votre entreprise. Une bonne équipe DevOps est indispensable pour assurer la fiabilité, l’évolutivité et la surveillance. Après tout, vous obtenez un produit fantastique dont vous pouvez être fier.