Big Data ja Hadoop Ecosystem Tutorial
Tervetuloa ensimmäiselle oppitunnille ’Big Data ja Hadoop Ecosystem’ (Big Data Hadoop Ecosystem), joka on osa koulutuskokonaisuutta ’Big Data Hadoop and Spark Developer Certification course’, jonka tarjoaa Simplilearn. Tämä oppitunti on johdatus Big Dataan ja Hadoopin ekosysteemiin. Seuraavassa osassa keskustelemme tämän oppitunnin tavoitteista.
Tavoitteet
Tämän oppitunnin jälkeen osaat:
-
Ymmärtää Big Datan käsitteen ja sen haasteet
-
Esittää, mitä Big Data on
-
Esittää, mitä Hadoop on. ja miten se vastaa Big Datan haasteisiin
-
Kuvaillaan Hadoopin ekosysteemi
Katsotaan nyt yleiskatsaus Big Dataan ja Hadoopiin.
Yleiskatsaus Big Dataan ja Hadoopiin
Ennen vuotta 2000 data oli suhteellisen pientä verrattuna nykyiseen; datan laskenta oli kuitenkin monimutkaista. Kaikki datan laskenta oli riippuvainen käytettävissä olevien tietokoneiden laskentatehosta.
Myöhemmin datan kasvaessa ratkaisuksi tulivat tietokoneet, joissa oli suuri muisti ja nopeat prosessorit. Vuoden 2000 jälkeen data kuitenkin kasvoi jatkuvasti, eikä alkuperäisestä ratkaisusta ollut enää apua.
Viime vuosina datan määrä on kasvanut uskomattomasti. IBM raportoi, että vuonna 2012 dataa tuotettiin päivittäin 2,5 exatavua eli 2,5 miljardia gigatavua.
Tässä on joitakin datan lisääntymisestä kertovia tilastoja Forbesista, syyskuu 2015. Googlessa tehdään 40 000 hakukyselyä joka sekunti. YouTubeen ladataan joka minuutti jopa 300 tuntia videoita.
Facebookissa käyttäjät lähettävät 31,25 miljoonaa viestiä ja 2,77 miljoonaa videota katsotaan joka minuutti. Vuoteen 2017 mennessä lähes 80 prosenttia valokuvista otetaan älypuhelimilla.
Vuoteen 2020 mennessä vähintään kolmannes kaikesta datasta kulkee pilvipalvelimen (Internetin kautta yhdistettyjen palvelimien verkko) kautta. Vuoteen 2020 mennessä noin 1,7 megatavua uutta tietoa syntyy joka sekunti jokaista maapallon ihmistä kohti.
Data kasvaa nopeammin kuin koskaan ennen. Voit käyttää enemmän tietokoneita tämän jatkuvasti kasvavan datan hallintaan. Sen sijaan, että yksi kone suorittaisi tehtävän, voit käyttää useita koneita. Tätä kutsutaan hajautetuksi järjestelmäksi.
Voit tutustua Big Data Hadoop and Spark Developer Certification -kurssin esikatseluun täällä!
Katsotaanpa esimerkkiä, jotta ymmärretään, miten hajautettu järjestelmä toimii.
Miten hajautettu järjestelmä toimii?
Asettele, että sinulla on yksi kone, jolla on neljä tulo-/lähtökanavaa. Kunkin kanavan nopeus on 100 MB/sek ja haluat käsitellä sillä yhden teratavun dataa.
Ykseltä koneelta kestää 45 minuuttia käsitellä yksi teratavu dataa. Oletetaan nyt, että yksi teratavu dataa käsitellään 100 koneella, joilla on sama konfiguraatio.
Sadalta koneelta kestää vain 45 sekuntia käsitellä yksi teratavu dataa. Hajautetuissa järjestelmissä Big Datan käsittelyyn kuluu vähemmän aikaa.
Katsotaan nyt hajautetun järjestelmän haasteita.
Haasteet hajautetuissa järjestelmissä
Koska hajautetussa järjestelmässä käytetään useita tietokoneita, järjestelmän vikaantumisen mahdollisuus on suuri. Myös kaistanleveyttä on rajoitettu.
Ohjelmoinnin monimutkaisuus on myös suuri, koska tietojen ja prosessien synkronointi on vaikeaa. Hadoopilla voidaan vastata näihin haasteisiin.
Ymmärretään seuraavassa kappaleessa, mikä Hadoop on.
Mikä on Hadoop?
Hadoop on kehys, joka mahdollistaa suurten tietokokonaisuuksien hajautetun käsittelyn tietokoneklustereissa käyttäen yksinkertaisia ohjelmointimalleja. Se on saanut inspiraationsa Googlen julkaisemasta teknisestä asiakirjasta.
Sanalla Hadoop ei ole mitään merkitystä. Doug Cutting, joka löysi Hadoopin, nimesi sen poikansa keltaisen lelunorsun mukaan.
Keskustellaanpa siitä, miten Hadoop ratkaisee hajautetun järjestelmän kolme haastetta, kuten järjestelmän suuren vikaantumismahdollisuuden, kaistanleveyden rajoituksen ja ohjelmoinnin monimutkaisuuden.
Hadoopin neljä keskeistä ominaisuutta ovat:
-
Taloudellinen: Sen järjestelmät ovat erittäin taloudellisia, koska tietojenkäsittelyyn voidaan käyttää tavallisia tietokoneita.
-
Luotettava: Se on luotettava, koska se tallentaa kopiot tiedoista eri koneisiin ja kestää laitteistovikoja.
-
Skaalautuva: Se on helposti skaalautuva sekä horisontaalisesti että vertikaalisesti. Muutama ylimääräinen solmu auttaa kehyksen skaalautumisessa.
-
Joustava: Se on joustava, ja voit tallentaa niin paljon strukturoitua ja strukturoimatonta dataa kuin haluat ja päättää käyttää niitä myöhemmin.
Traditionaalisesti data tallennettiin keskitettyyn paikkaan, ja se lähetettiin prosessorille suoritusaikana. Tämä menetelmä toimi hyvin rajoitetulle määrälle dataa.
Nykyaikaiset järjestelmät vastaanottavat kuitenkin teratavuja dataa päivässä, ja perinteisten tietokoneiden tai relaatiotietokannan hallintajärjestelmän (RDBMS) on vaikea työntää suuria määriä dataa prosessorille.
Hadoop toi mukaan radikaalin lähestymistavan. Hadoopissa ohjelma menee dataan, ei päinvastoin. Se jakaa datan aluksi useisiin järjestelmiin ja suorittaa myöhemmin laskennan siellä, missä data sijaitsee.
Seuraavassa luvussa puhutaan siitä, miten Hadoop eroaa perinteisestä tietokantajärjestelmästä.
Perinteisen tietokantajärjestelmän ja Hadoopin ero
Alhaalla oleva taulukko auttaa erottamaan perinteisen tietokantajärjestelmän ja Hadoopin toisistaan.
|
Traditionaalinen tietokantajärjestelmä |
Hadoop |
|
Tieto tallennetaan keskitettyyn paikkaan ja lähetetään prosessorille suoritusajankohtana. |
Hadoop:issa ohjelma siirtyy datan luo. Se jakaa datan aluksi useisiin järjestelmiin ja suorittaa myöhemmin laskennan siellä, missä data sijaitsee. |
|
Traditionaalisia tietokantajärjestelmiä ei voida käyttää huomattavan suuren datamäärän (big data) käsittelyyn ja tallentamiseen. |
Hadoop toimii paremmin, kun datan koko on suuri. Se pystyy käsittelemään ja tallentamaan suuren tietomäärän tehokkaasti ja vaikuttavasti. |
|
Traditionaalisia RDBMS-järjestelmiä käytetään vain strukturoitujen ja puolistrukturoitujen tietojen hallintaan. Sitä ei voi käyttää strukturoimattoman datan hallintaan. |
Hadoop pystyy käsittelemään ja tallentamaan monenlaista dataa, oli se sitten strukturoitua tai strukturoimatonta. |
Keskustellaanpa perinteisen RDBMS:n ja Hadoopin eroa erään analogian avulla.
Olet varmaan havainnut eron ihmisen ja tiikerin ruokailutyyleissä. Ihminen syö ruokaa lusikan avulla, jossa ruoka tuodaan suuhun. Kun taas tiikeri tuo suunsa kohti ruokaa.
Nyt jos ruoka on dataa ja suu on ohjelma, ihmisen syömistyyli kuvaa perinteistä RDBMS:ää ja tiikerin tyyli kuvaa Hadoopia.
Katsotaan seuraavassa kappaleessa Hadoopin ekosysteemiä.
Hadoopin ekosysteemi
Hadoopin ekosysteemi Hadoopin ekosysteemi on kehittynyt sen kolmesta ydinkomponentista käsittely, resurssienhallinta ja tallennus. Tässä aiheessa opit Hadoop-ekosysteemin komponentit ja sen, miten ne suorittavat roolinsa Big Datan käsittelyssä.
Hadoop-ekosysteemi kasvaa jatkuvasti Big Datan tarpeisiin. Se koostuu seuraavista kahdestatoista komponentista:
-
HDFS(Hadoop Distributed file system)
-
HBase
-
Sqoop
-
Flume
-
Spark
-
Hadoop. MapReduce
-
Pig
-
Impala
-
Hive
-
Cloudera Search
-
Oozie
-
Hue.
Seuraavissa kappaleissa tutustutaan Hadoop-ekosysteemin kunkin komponentin rooliin.

Ymmärretään Hadoop-ekosysteemin kunkin komponentin rooli.
Hadoop-ekosysteemin komponentit
Aloitetaan Hadoop-ekosysteemin ensimmäisestä komponentista HDFS:stä.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
-
HDFS on Hadoopin tallennuskerros.
-
HDFS soveltuu hajautettuun tallennukseen ja käsittelyyn, eli kun dataa tallennetaan, se ensin hajautetaan ja sitten käsitellään.
-
HDFS tarjoaa suoratoistokäyttöä tiedostojärjestelmän tietoihin.
-
HDFS tarjoaa tiedostojen käyttöoikeudet ja todennuksen.
-
HDFS käyttää komentorivikäyttöliittymää vuorovaikutukseen Hadoopin kanssa.
Millä siis tallennetaan dataa HDFS:ään? Se on HBase, joka tallentaa dataa HDFS:ään.
HBase
-
HBase on NoSQL-tietokanta eli ei-relationaalinen tietokanta.
-
HBase on tärkeä ja sitä käytetään pääasiassa silloin, kun tarvitaan satunnaista, reaaliaikaista, luku- tai kirjoitusoikeutta Big Dataan.
-
Se tukee suurta tietomäärää ja suurta läpimenoa.
-
HBase-tietokannassa taulussa voi olla tuhansia sarakkeita.
Keskustelimme siitä, miten dataa jaetaan ja tallennetaan. Ymmärretään nyt, miten nämä tiedot syötetään tai siirretään HDFS:ään. Sqoop tekee juuri tämän.
Mikä on Sqoop?
-
Sqoop on työkalu, joka on suunniteltu siirtämään dataa Hadoopin ja relaatiotietokantapalvelimien välillä.
-
Sitä käytetään tietojen tuomiseen relaatiotietokannoista (kuten Oraclesta ja MySQL:stä) HDFS:ään ja tietojen viemiseen HDFS:stä relaatiotietokantoihin.
Jos haluat syöttää tapahtumadataa, kuten suoratoistodataa, sensoridataa tai lokitiedostoja, voit käyttää Flumea. Tarkastelemme Flumea seuraavassa kappaleessa.
Flume
-
Flume on hajautettu palvelu, joka kerää tapahtumadataa ja siirtää sen HDFS:ään.
-
Se soveltuu erinomaisesti tapahtumadatan keräämiseen useista eri järjestelmistä.
Kun data on siirretty HDFS:ään, sitä käsitellään. Yksi dataa käsittelevistä kehyksistä on Spark.
Mikä on Spark?
-
Spark on avoimen lähdekoodin klusterilaskentakehys.
-
Se tarjoaa jopa 100 kertaa nopeamman suorituskyvyn muutamille sovelluksille in-memory-primitiivien avulla verrattuna Hadoopin kaksivaiheiseen levypohjaiseen MapReduce-paradigmaan.
-
Spark voi toimia Hadoop-klusterissa ja käsitellä dataa HDFS:ssä.
-
Spark tukee myös monenlaisia työkuormia, joita ovat muun muassa koneoppiminen, liiketoiminta-älykkyys, suoratoisto ja eräkäsittely.
Spark sisältää seuraavat pääkomponentit:
-
Spark Core ja Resilient Distributed datasets eli RDD
-
Spark SQL
-
Spark streaming
-
Koneoppimiskirjasto eli Mlib
-
Graphx.
Spark on nykyään laajalti käytössä, ja opit siitä lisää seuraavilla oppitunneilla.
Hadoop MapReduce
-
Hadoop MapReduce on toinen dataa käsittelevä kehys.
-
Se on alkuperäinen Hadoopin prosessointimoottori, joka on pääasiassa Java-pohjainen.
-
Se perustuu map and reduces -ohjelmointimalliin.
-
Monet työkalut, kuten Hive ja Pig, perustuvat map-reduce-malliin.
-
Se on rakentanut viitekehykseen laajan ja kypsän vikasietoisuuden.
-
Se on edelleen hyvin yleisesti käytetty, mutta se on menettämässä jalansijaa Sparkille.
Datan prosessoinnin jälkeen se analysoidaan. Se voidaan tehdä avoimen lähdekoodin korkean tason tiedonkulkujärjestelmällä nimeltä Pig. Sitä käytetään pääasiassa analytiikkaan.
Ymmärretään nyt, miten Pigiä käytetään analytiikkaan.
Pig
-
Pig muuntaa skriptinsä Map- ja Reduce-koodiksi, jolloin käyttäjä säästyy monimutkaisten MapReduce-ohjelmien kirjoittamiselta.
-
Ad-hoc-kyselyt, kuten Filter ja Join, joita on vaikea suorittaa MapReduce-ohjelmassa, voidaan tehdä helposti Pigin avulla.
-
Datan analysointiin voi käyttää myös Impalaa.
-
Se on avoimen lähdekoodin suorituskykyinen SQL-moottori, joka toimii Hadoop-klusterissa.
-
Se soveltuu erinomaisesti interaktiiviseen analyysiin, ja sillä on hyvin pieni latenssi, joka voidaan mitata millisekunneissa.
Impala
-
Impala tukee SQL:n murretta, joten HDFS:ssä oleva data mallinnetaan tietokantatauluksi.
-
Data-analyysiä voi tehdä myös HIVE:n avulla. Se on abstraktiokerros Hadoopin päällä.
-
Se on hyvin samanlainen kuin Impala. Sitä käytetään kuitenkin mieluummin tietojen käsittelyyn ja Extract Transform Load- eli ETL-operaatioihin.
-
Impalaa käytetään mieluummin ad-hoc-kyselyihin.
HIVE
-
HIVE suorittaa kyselyitä MapReduce-ohjelmalla; käyttäjän ei kuitenkaan tarvitse kirjoittaa mitään koodia matalan tason MapReduce-ohjelmalla.
-
Hive soveltuu strukturoituun dataan. Kun tiedot on analysoitu, ne ovat valmiina käyttäjien käyttöön.
Nyt kun tiedämme, mitä HIVE tekee, keskustelemme siitä, mikä tukee tietojen hakua. Tiedonhaku tapahtuu Cloudera Searchin avulla.
Cloudera Search
-
Haku on yksi Clouderan lähes reaaliaikaisen pääsyn tuotteista. Sen avulla ei-tekniset käyttäjät voivat hakea ja tutkia dataa, joka on tallennettu tai syötetty Hadoopiin ja HBaseen.
-
Käyttäjät eivät tarvitse SQL- tai ohjelmointitaitoja Cloudera Searchin käyttöön, koska se tarjoaa yksinkertaisen kokotekstikäyttöliittymän hakua varten.
-
Toinen Cloudera Searchin etu erillisiin hakuratkaisuihin verrattuna on täysin integroitu tietojenkäsittelyalusta.
-
Cloudera Search käyttää CDH:n tai Cloudera Distributionin sisältämää joustavaa, skaalautuvaa ja vankkaa tallennusjärjestelmää, mukaan lukien Hadoop. Tämä poistaa tarpeen siirtää suuria tietokokonaisuuksia eri infrastruktuurien välillä liiketoimintatehtävien hoitamiseksi.
-
Hadoop-työtehtävissä, kuten MapReduce, Pig, Hive ja Sqoop, on työnkulkuja.
Oozie
-
Oozie on työnkulku- tai koordinointijärjestelmä, jota voit käyttää Hadoop-työtehtävien hallintaan.
Oozie-sovelluksen elinkaari on esitetty alla olevassa kaaviossa.
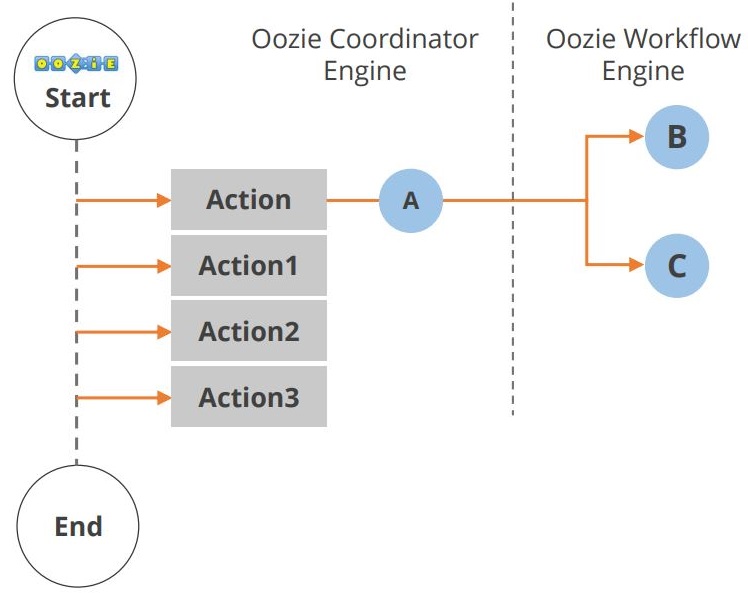 Kuten huomaat, työnkulun alun ja lopun välissä tapahtuu useita toimia. Toinen Hadoop-ekosysteemin komponentti on Hue. Tarkastellaan nyt Huea.
Kuten huomaat, työnkulun alun ja lopun välissä tapahtuu useita toimia. Toinen Hadoop-ekosysteemin komponentti on Hue. Tarkastellaan nyt Huea.
Hue
Hue on lyhenne sanoista Hadoop User Experience. Se on avoimen lähdekoodin web-käyttöliittymä Hadoopille. Huen avulla voit suorittaa seuraavat toiminnot:
-
Lataat ja selaat dataa
-
Kyselet taulukkoa HIVE:ssä ja Impalassa
-
Johdatat Spark- ja Pig-tehtäviä ja -työnkulkuja Etsit dataa
-
Kaiken kaikkiaan Hue tekee Hadoopista helpomman käyttää.
-
Se tarjoaa myös SQL-editorin HIVE:lle, Impalalle, MySQL:lle, Oraclelle, PostgreSQL:lle, SparkSQL:lle ja Solr SQL:lle.
Tämän lyhyen yleiskatsauksen jälkeen, jossa esiteltiin Hadoopin ekosysteemin kaksitoista komponenttia, keskustelemme seuraavaksi siitä, miten nämä komponentit työskentelevät yhdessä käsitelläkseen Big Dataa.
Suuren datan prosessoinnin vaiheet
Suuren datan prosessoinnissa on neljä vaihetta: Ingest, Processing, Analyze, Access. Tarkastellaan niitä yksityiskohtaisesti.
Ingest
Big Datan käsittelyn ensimmäinen vaihe on Ingest. Tiedot ingestoidaan tai siirretään Hadoopiin eri lähteistä, kuten relaatiotietokannoista, järjestelmistä tai paikallisista tiedostoista. Sqoop siirtää dataa RDBMS:stä HDFS:ään, kun taas Flume siirtää tapahtumatietoa.
Käsittely
Toinen vaihe on käsittely. Tässä vaiheessa tiedot tallennetaan ja käsitellään. Tiedot tallennetaan hajautettuun tiedostojärjestelmään, HDFS:ään, ja NoSQL-hajautettuun dataan, HBaseen. Spark ja MapReduce suorittavat tietojen käsittelyn.
Analyze
Kolmas vaihe on Analyze. Tässä data analysoidaan käsittelykehyksillä, kuten Pig, Hive ja Impala.
Pig muuntaa datan mapin ja reducein avulla ja analysoi sen jälkeen. Hive perustuu myös map and reduce -ohjelmointiin, ja se soveltuu parhaiten strukturoituun dataan.
Access
Neljäs vaihe on Access, jonka suorittavat työkalut kuten Hue ja Cloudera Search. Tässä vaiheessa käyttäjät pääsevät käsiksi analysoituun dataan.
Hue on web-käyttöliittymä, kun taas Cloudera Search tarjoaa tekstikäyttöliittymän datan tutkimiseen.
Katso Big Data Hadoop and Spark Developer -sertifiointikurssi täältä!
Yhteenveto
Tehdään nyt yhteenveto siitä, mitä opimme tällä oppitunnilla.
-
Hadoop on hajautetun tallennuksen ja käsittelyn kehys.
-
Hadoopin ydinkomponentteihin kuuluvat HDFS tallennukseen, YARN klusteriresurssien hallintaan ja MapReduce tai Spark käsittelyyn.
-
Hadoopin ekosysteemi sisältää useita komponentteja, jotka tukevat Big Datan käsittelyn jokaista vaihetta.
-
Flume ja Sqoop syöttävät dataa, HDFS ja HBase tallentavat dataa, Spark ja MapReduce käsittelevät dataa, Pig, Hive ja Impala analysoivat dataa, Hue ja Cloudera Search auttavat datan tutkimisessa.
-
Oozie hallitsee Hadoop-työtehtävien työnkulkua.
Loppupäätelmä
Tämä päättää oppitunnin Big Datasta ja Hadoop-ekosysteemistä. Seuraavalla oppitunnilla käsittelemme HDFS:ää ja YARN:ää.
Löydä Big Data Hadoop and Spark Developer Online Classroom -koulutustunnit huippukaupungeissa:
| Name | Date | Place | |
|---|---|---|---|
| Big Data Hadoop and Spark Developer | 3.4.-15.5.2021, Viikonloppuerä | Sinun kaupunki | Katso tiedot |
| Big Data Hadoop and Spark Developer | 12.4.-4.5.2021, Weekdays batch | Your City | View Details |
| Big Data Hadoop and Spark Developer | 24 Apr -5 Jun 2021, Weekend batch | Your City | View Details |
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Tutustu kurssin
Big Data Hadoop and Spark Developer Certification Training
Siirry kurssille
Tutustu kurssin
, ota kurssi
Big Data Hadoop and Spark Developer Certification Training Siirry kurssille