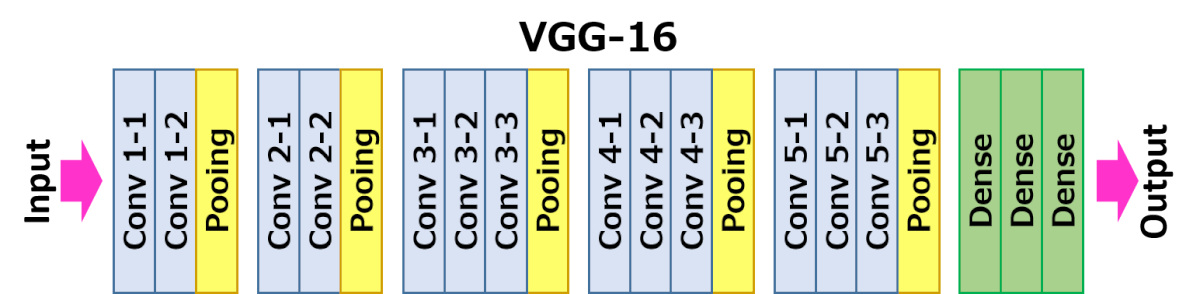
VGG16 – Red convolucional para la clasificación y la detección
VGG16 es un modelo de red neuronal convolucional propuesto por K. Simonyan y A. Zisserman de la Universidad de Oxford en el artículo «Very Deep Convolutional Networks for Large-Scale Image Recognition». El modelo alcanza un 92,7% de precisión en la prueba top-5 en ImageNet, que es un conjunto de datos de más de 14 millones de imágenes pertenecientes a 1000 clases. Fue uno de los famosos modelos presentados a la ILSVRC-2014. Mejora a AlexNet sustituyendo los filtros de gran tamaño del núcleo (11 y 5 en la primera y segunda capa convolucional, respectivamente) por múltiples filtros de tamaño de núcleo 3×3, uno tras otro. VGG16 se entrenó durante semanas y se utilizó la GPU NVIDIA Titan Black.
DataSet
ImageNet es un conjunto de datos de más de 15 millones de imágenes de alta resolución etiquetadas que pertenecen a unas 22.000 categorías. Las imágenes se recogieron de la web y fueron etiquetadas por personas que utilizaron la herramienta de crowdsourcing Mechanical Turk de Amazon. A partir de 2010, como parte del Desafío de Objetos Visuales Pascal, se ha celebrado una competición anual denominada Desafío de Reconocimiento Visual a Gran Escala de ImageNet (ILSVRC). ILSVRC utiliza un subconjunto de ImageNet con aproximadamente 1000 imágenes en cada una de las 1000 categorías. En total, hay aproximadamente 1,2 millones de imágenes de entrenamiento, 50.000 de validación y 150.000 de prueba. ImageNet se compone de imágenes de resolución variable. Por lo tanto, las imágenes se han muestreado a una resolución fija de 256×256. Dada una imagen rectangular, se reescala la imagen y se recorta el parche central de 256×256 de la imagen resultante.
La arquitectura
La arquitectura representada a continuación es VGG16.
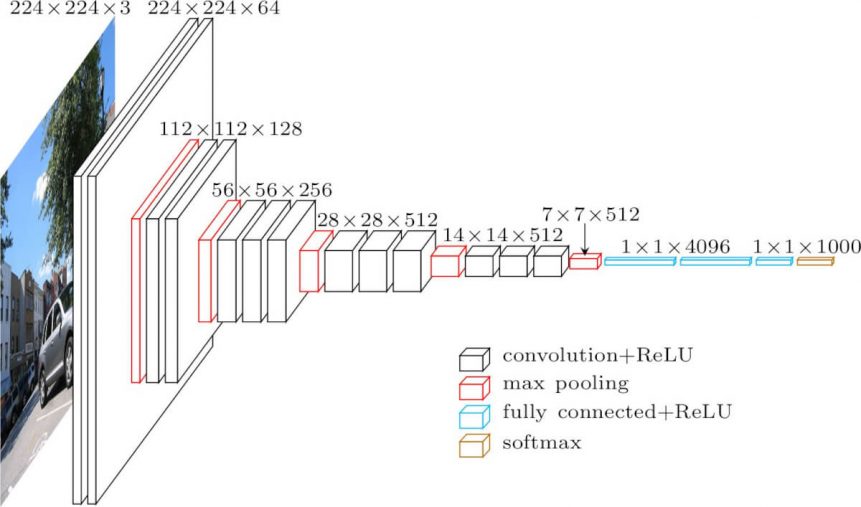
La entrada a la capa cov1 es una imagen RGB de tamaño fijo 224 x 224. La imagen pasa por una pila de capas convolucionales (conv.), donde los filtros se utilizaron con un campo receptivo muy pequeño: 3×3 (que es el tamaño más pequeño para capturar la noción de izquierda/derecha, arriba/abajo, centro). En una de las configuraciones, también se utilizan filtros de convolución 1×1, que pueden verse como una transformación lineal de los canales de entrada (seguida de no linealidad). El intervalo de convolución se fija en 1 píxel; el relleno espacial de la entrada de la capa de conv. es tal que la resolución espacial se conserva después de la convolución, es decir, el relleno es de 1 píxel para las capas de conv. 3×3. El pooling espacial se lleva a cabo mediante cinco capas de max-pooling, que siguen a algunas de las capas de conv. (no todas las capas de conv. van seguidas de max-pooling). El max-pooling se realiza sobre una ventana de 2×2 píxeles, con un stride de 2.
Tres capas totalmente conectadas (FC) siguen a una pila de capas convolucionales (que tiene una profundidad diferente en las distintas arquitecturas): las dos primeras tienen 4096 canales cada una, la tercera realiza una clasificación ILSVRC de 1000 vías y, por tanto, contiene 1000 canales (uno para cada clase). La última capa es la capa soft-max. La configuración de las capas totalmente conectadas es la misma en todas las redes.
Todas las capas ocultas están equipadas con la no linealidad de rectificación (ReLU). También se observa que ninguna de las redes (excepto una) contiene Normalización de Respuesta Local (LRN), dicha normalización no mejora el rendimiento en el conjunto de datos ILSVRC, sino que conduce a un mayor consumo de memoria y tiempo de cálculo.
Configuraciones
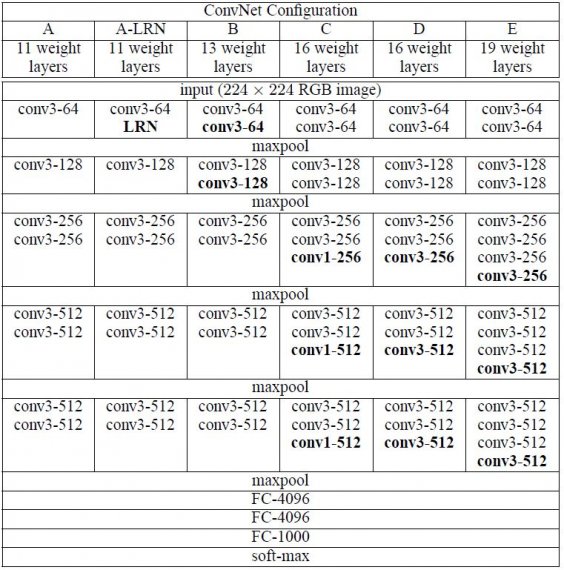
Las configuraciones de las ConvNet se esquematizan en la figura 2. Las redes están referidas a sus nombres (A-E). Todas las configuraciones siguen el diseño genérico presente en la arquitectura y difieren únicamente en la profundidad: desde 11 capas de pesos en la red A (8 capas conv. y 3 capas FC) hasta 19 capas de pesos en la red E (16 capas conv. y 3 capas FC). La anchura de las capas de conv. (el número de canales) es bastante pequeña, empezando por 64 en la primera capa y aumentando en un factor de 2 después de cada capa de agrupación máxima, hasta llegar a 512.
Casos de uso e implementación
Desgraciadamente, hay dos inconvenientes importantes con VGGNet:
- Es dolorosamente lento de entrenar.
- Los pesos de la arquitectura de la red en sí mismos son bastante grandes (en lo que respecta al disco/ancho de banda).
Debido a su profundidad y al número de nodos totalmente conectados, VGG16 ocupa más de 533MB. Esto hace que el despliegue de VGG sea una tarea pesada.VGG16 se utiliza en muchos problemas de clasificación de imágenes de aprendizaje profundo; sin embargo, a menudo son más deseables las arquitecturas de red más pequeñas (como SqueezeNet, GoogLeNet, etc.). Pero es un gran bloque de construcción para el propósito de aprendizaje, ya que es fácil de implementar.
Resultado
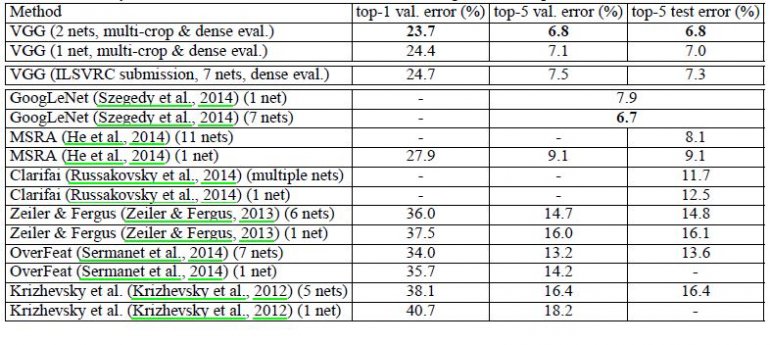
VGG16 supera significativamente la generación anterior de modelos en las competiciones ILSVRC-2012 e ILSVRC-2013. El resultado de VGG16 también compite por el ganador de la tarea de clasificación (GoogLeNet con un error del 6,7%) y supera sustancialmente a la presentación ganadora de la ILSVRC-2013, Clarifai, que logró un 11,2% con datos de entrenamiento externos y un 11,7% sin ellos. En cuanto al rendimiento de una sola red, la arquitectura VGG16 logra el mejor resultado (7,0% de error en la prueba), superando a GoogLeNet en un 0,9%.
Se demostró que la profundidad de la representación es beneficiosa para la precisión de la clasificación, y que el rendimiento de vanguardia en el conjunto de datos del desafío ImageNet puede lograrse utilizando una arquitectura ConvNet convencional con una profundidad sustancialmente mayor.